连接复用主要是指,一个连接可以被多个使用者同时使用,且互相之间不受影响,可以并发的发送多个请求,而应答是异步的,可复用的连接一般用于私有协议的连接,因为可复用的连接,请求可以一直发送,应答也不一定是按照请求顺序进行应答,就带来了一个问题,应答怎样才能和请求对应上。私有协议就比较容易在协议包内,增加sequence id,所以能达到连接复用的要求。唯品会网关调用唯品会内部的私有协议服务时,就采用的这种连接复用模式。
连接复用还有一种实现模式,是spymemcache的模式,memcached本身不支持sequenceid,但同一个连接上的操作会保证顺序性,所以,spymemcache通过把请求缓存在queue中的形式,顺序匹配返回结果,达到连接复用。
===================================
连接池的异步化,在连接池使用的所有阶段都应该异步化。我们在设计网关的连接池时,考虑了以下几个方面:获取连接的异步化。从连接池获取连接,一般情况被认为是个没有block的动作,实际上分解来看,获取连接池,可能需要锁连接池对象所在的队列,操作连接池计数器时,可能会遇到锁、超时等问题。后面我会跟大家分享我们怎样去做的优化。连接使用就是说实际用连接去调用其他服务,这块的异步化,大家基本都会考虑到。归还连接的异步化。归还连接时,也会操作连接池中的连接队列,有时连接已经异常还会执行关闭连接等动作,所以也会产生锁的问题。
和获取连接时类似,我们也把操作封装为task,交由netty做cpu亲缘性路由。
==================================================================================================================================================================================
从系统架构来看,目前的商用服务器大体可以分为三类,即:
对称多处理器结构(SMP:Symmetric Multi-Processor)
非一致存储访问结构(NUMA:Non-Uniform Memory Access)
以及海量并行处理结构(MPP:Massive Parallel Processing)
从系统架构来看,目前的商用服务器大体可以分为三类,即
对称多处理器结构(SMP:Symmetric Multi-Processor),
非一致存储访问结构(NUMA:Non-Uniform Memory Access),
海量并行处理结构(MPP:Massive Parallel Processing)。
它们的特征分别描述如下:
SMP(Symmetric Multi-Processor)
所谓对称多处理器结构,是指服务器中多个CPU对称工作,无主次或从属关系。各CPU共享相同的物理内存,每个 CPU访问内存中的任何地址所需时间是相同的,因此SMP也被称为一致存储器访问结构(UMA:Uniform Memory Access)。对SMP服务器进行扩展的方式包括增加内存、使用更快的CPU、增加CPU、扩充I/O(槽口数与总线数)以及添加更多的外部设备(通常是磁盘存储)。
SMP服务器的主要特征是共享,系统中所有资源(CPU、内存、I/O等)都是共享的。也正是由于这种特征,导致了SMP服务器的主要问题,那就是它的扩展能力非常有限。对于SMP服务器而言,每一个共享的环节都可能造成SMP服务器扩展时的瓶颈,而最受限制的则是内存。由于每个CPU必须通过相同的内存总线访问相同的内存资源,因此随着CPU数量的增加,内存访问冲突将迅速增加,最终会造成CPU资源的浪费,使 CPU性能的有效性大大降低。实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU。

图1.SMP服务器CPU利用率状态
NUMA(Non-Uniform Memory Access)
由于SMP在扩展能力上的限制,人们开始探究如何进行有效地扩展从而构建大型系统的技术,NUMA就是这种努力下的结果之一。利用NUMA技术,可以把几十个CPU(甚至上百个CPU)组合在一个服务器内。其CPU模块结构如图2所示:

图2.NUMA服务器CPU模块结构
NUMA服务器的基本特征是具有多个CPU模块,每个CPU模块由多个CPU(如4个)组成,并且具有独立的本地内存、I/O槽口等。由于其节点之间可以通过互联模块(如称为Crossbar Switch)进行连接和信息交互,因此每个CPU可以访问整个系统的内存(这是NUMA系统与MPP系统的重要差别)。显然,访问本地内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致存储访问NUMA的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同CPU模块之间的信息交互。利用NUMA技术,可以较好地解决原来SMP系统的扩展问题,在一个物理服务器内可以支持上百个CPU。比较典型的NUMA服务器的例子包括HP的Superdome、SUN15K、IBMp690等。
但NUMA技术同样有一定缺陷,由于访问远地内存的延时远远超过本地内存,因此当CPU数量增加时,系统性能无法线性增加。如HP公司发布Superdome服务器时,曾公布了它与HP其它UNIX服务器的相对性能值,结果发现,64路CPU的Superdome (NUMA结构)的相对性能值是20,而8路N4000(共享的SMP结构)的相对性能值是6.3。从这个结果可以看到,8倍数量的CPU换来的只是3倍性能的提升。
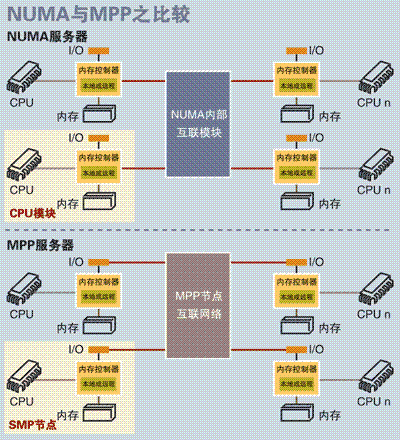
图3.MPP服务器架构图
MPP(Massive Parallel Processing)
和NUMA不同,MPP提供了另外一种进行系统扩展的方式,它由多个SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个SMP服务器(每个SMP服务器称节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构,因而扩展能力最好,理论上其扩展无限制,目前的技术可实现512个节点互联,数千个CPU。目前业界对节点互联网络暂无标准,如 NCR的Bynet,IBM的SPSwitch,它们都采用了不同的内部实现机制。但节点互联网仅供MPP服务器内部使用,对用户而言是透明的。
在MPP系统中,每个SMP节点也可以运行自己的操作系统、数据库等。但和NUMA不同的是,它不存在异地内存访问的问题。换言之,每个节点内的CPU不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution)。
但是MPP服务器需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程。目前一些基于MPP技术的服务器往往通过系统级软件(如数据库)来屏蔽这种复杂性。举例来说,NCR的Teradata就是基于MPP技术的一个关系数据库软件,基于此数据库来开发应用时,不管后台服务器由多少个节点组成,开发人员所面对的都是同一个数据库系统,而不需要考虑如何调度其中某几个节点的负载。
NUMA与MPP的区别
从架构来看,NUMA与MPP具有许多相似之处:它们都由多个节点组成,每个节点都具有自己的CPU、内存、I/O,节点之间都可以通过节点互联机制进行信息交互。那么它们的区别在哪里?通过分析下面NUMA和MPP服务器的内部架构和工作原理不难发现其差异所在。
首先是节点互联机制不同,NUMA的节点互联机制是在同一个物理服务器内部实现的,当某个CPU需要进行远地内存访问时,它必须等待,这也是NUMA服务器无法实现CPU增加时性能线性扩展的主要原因。而MPP的节点互联机制是在不同的SMP服务器外部通过I/O 实现的,每个节点只访问本地内存和存储,节点之间的信息交互与节点本身的处理是并行进行的。因此MPP在增加节点时性能基本上可以实现线性扩展。
其次是内存访问机制不同。在NUMA服务器内部,任何一个CPU可以访问整个系统的内存,但远地访问的性能远远低于本地内存访问,因此在开发应用程序时应该尽量避免远地内存访问。在MPP服务器中,每个节点只访问本地内存,不存在远地内存访问的问题。
数据仓库的选择
哪种服务器更加适应数据仓库环境?这需要从数据仓库环境本身的负载特征入手。众所周知,典型的数据仓库环境具有大量复杂的数据处理和综合分析,要求系统具有很高的I/O处理能力,并且存储系统需要提供足够的I/O带宽与之匹配。而一个典型的OLTP系统则以联机事务处理为主,每个交易所涉及的数据不多,要求系统具有很高的事务处理能力,能够在单位时间里处理尽量多的交易。显然这两种应用环境的负载特征完全不同。
从NUMA架构来看,它可以在一个物理服务器内集成许多CPU,使系统具有较高的事务处理能力,由于远地内存访问时延远长于本地内存访问,因此需要尽量减少不同CPU模块之间的数据交互。显然,NUMA架构更适用于OLTP事务处理环境,当用于数据仓库环境时,由于大量复杂的数据处理必然导致大量的数据交互,将使CPU的利用率大大降低。
相对而言,MPP服务器架构的并行处理能力更优越,更适合于复杂的数据综合分析与处理环境。当然,它需要借助于支持MPP技术的关系数据库系统来屏蔽节点之间负载平衡与调度的复杂性。另外,这种并行处理能力也与节点互联网络有很大的关系。显然,适应于数据仓库环境的MPP服务器,其节点互联网络的I/O性能应该非常突出,才能充分发挥整个系统的性能。
相信梦想是价值的源泉,相信眼光决定未来的一切,相信成功的信念比成功本身更重要,相信人生有挫折没有失败,相信生命的质量来自决不妥协的信念!——I`m geek!
==================================================================================================================================================================================
CPU亲合力就是指在Linux系统中能够将一个或多个进程绑定到一个或多个处理器上运行.
一个进程的CPU亲合力掩码决定了该进程将在哪个或哪几个CPU上运行.在一个多处理器系统中,设置CPU亲合力的掩码可能会获得更好的性能.
一个CPU的亲合力掩码用一个cpu_set_t结构体来表示一个CPU集合,下面的几个宏分别对这个掩码集进行操作:
·CPU_ZERO() 清空一个集合
·CPU_SET()与CPU_CLR()分别对将一个给定的CPU号加到一个集合或者从一个集合中去掉.
·CPU_ISSET()检查一个CPU号是否在这个集合中.
===========================================================================================================================================================================================================================================================================
Linux CPU亲缘性详解
前言
在淘宝开源自己基于nginx打造的tegine服务器的时候,有这么一项特性引起了笔者的兴趣。“自动根据CPU数目设置进程个数和绑定CPU亲缘性”。当时笔者对CPU亲缘性没有任何概念,当时作者只是下意识的打开了google并输入CPU亲缘性(CPU Affinity)简单了做了个了解。
后来,在笔者参加实际工作以后,就碰到了这么两个问题。
问题一:如何在SMP的系统中,保证某个特定进程即使在其他进程都很忙的情况下都能够获得足够的CPU资源?解决的思路主要有以下两种:
- 提高进程的处理优先级
- 从SMP系统中,专门划拨出某一个CPU用于运行该程序。 而将其他进程划拨到其他的CPU上进行运行。
问题二:通过每日监控数据,我们发现服务器的CPU使用率出现这样子的情况,除了CPU0,其他CPU的负载都很低。
我们选择了通过设置CPU亲缘性的方式进行优化,在完成相关优化后,我们的应用程序性能得到了一定的提高。(大致有10%的性能提升)
此次,笔者借着博文的机会将“CPU亲缘性”这一特性的学习过程整理下来,以备日后查验。注意,本文所提到的CPU亲缘性均基于Linux。
什么是CPU亲缘性
所谓CPU亲缘性可以分为两大类:软亲缘性和硬亲缘性。
Linux 内核进程调度器天生就具有被称为 CPU 软亲缘性(soft affinity) 的特性,这意味着进程通常不会在处理器之间频繁迁移。这种状态正是我们希望的,因为进程迁移的频率小就意味着产生的负载小。但不代表不会进行小范围的迁移。
CPU 硬亲缘性是指通过Linux提供的相关CPU亲缘性设置接口,显示的指定某个进程固定的某个处理器上运行。本文所提到的CPU亲缘性主要是指硬亲缘性。
使用CPU亲缘性的好处
目前主流的服务器配置都是SMP架构,在SMP的环境下,每个CPU本身自己会有缓存,缓存着进程使用的信息,而进程可能会被kernel调度到其他CPU上(即所谓的core migration),如此,CPU cache命中率就低了。设置CPU亲缘性,程序就会一直在指定的cpu运行,防止进程在多SMP的环境下的core migration,从而避免因切换带来的CPU的L1/L2 cache失效。从而进一步提高应用程序的性能。
Linux CPU亲缘性的使用
我们有两种办法指定程序运行的CPU亲缘性。
- 通过Linux提供的taskset工具指定进程运行的CPU。
- 方式二,glibc本身也为我们提供了这样的接口,借来的内容主要为大家讲解如何通过编程的方式设置进程的CPU亲缘性。
相关接口
利用glibc库中的sched_getaffinity接口,我们获取应用程序当前的cpu亲缘性,而通过sched_setaffinity接口则可以把应用程序绑定到固定的某个或某几cpu上运行。相关定义如下:
1 #include <sched.h> 2 3 4 void CPU_ZERO(cpu_set_t *set); 5 void CPU_CLR(int cpu, cpu_set_t *set); 6 void CPU_SET(int cpu, cpu_set_t *set); 7 int CPU_ISSET(int cpu, cpu_set_t *set); 8 9 int sched_getaffinity(pid_t pid, unsigned int cpusetsize, cpu_set_t *mask); 10 11 int sched_setaffinity(pid_t pid, unsigned int cpusetsize, cpu_set_t *mask);
其中的cpu_set_t结构体的具体定义:
1 /*/usr/include/bits/sched.h*/
2
3
4 # define __CPU_SETSIZE 1024
5 # define __NCPUBITS (8 * sizeof (__cpu_mask))
6
7 /* Type for array elements in 'cpu_set'. */
8 typedef unsigned long int __cpu_mask;
9
10 typedef struct
11 {
12 __cpu_mask __bits[__CPU_SETSIZE / __NCPUBITS];
13 } cpu_set_t;
可以看到其用每一bit位表示一个cpu的状态,最多可以表示1024个cpu的亲缘状态,这在目前来说足够用了.
在 Linux 内核中,所有的进程都有一个相关的数据结构,称为 task_struct。这个结构非常重要,原因有很多;其中与 亲缘性(affinity)相关度最高的是 cpus_allowed 位掩码。这个位掩码由 n 位组成,与系统中的 n 个逻辑处理器一一对应。 具有 4 个物理 CPU 的系统可以有 4 位。如果这些 CPU 都启用了超线程,那么这个系统就有一个 8 位的位掩码。
如果为给定的进程设置了给定的位,那么这个进程就可以在相关的 CPU 上运行。因此,如果一个进程可以在任何 CPU 上运行,并且能够根据需要在处理器之间进行迁移,那么位掩码就全是 1。实际上,这就是 Linux 中进程的缺省状态。相关内核调度代码如下:
=========================================
Linux通过select_task_rq函数决定进程在哪一个CPU上进行运行。
cpumask_test_cpu 当前CPU是否处于广播的掩码中
---------------------------------------------------------------------------------
1) 先从task_rq(task)->rd->cpupri中寻找优先级最低的cpu集合,并求出此 最低优先级cpu集合 与task->cpus_allowed交集的集合,放到lowest_mask中,后续都优先在此集合中进行选择;
2) 首先检查新任务的默认cpu是否在lowest_mask这个集合中,如果是,则选择此cpu返回;
3) 其次在当前就绪队列所在的各级sched_domain中查找存在的cpu,如果当前运行的this_cpu在lowest_mask中,且this_cpu又在sched_domain中就优先选择此cpu;(why?因为,this_cpu是task迁移"相对便宜"的cpu);
4) 否则就退而求此次选择lowest_mask与sched_domain中有交集的cpu;
5) 如果在各级sched_domain中也未能找到合适的cpu,就检查正在运行的this_cpu是否在lowest_mask中,如果是的话就选择当前正在运行的this_cpu作为新任务的cpu;
6) 如果前面没有能找到符合要求的cpu,则就在lowest_mask中随便选择一个cpu返回,如果lowest_mask中压根就没有cpu,则返回-1。
如果上面最终没有能够找到一个合适的cpu,则需要通过select_fallback_rq(int cpu, struct task_struct *p)在其他集合中为新任务选择一个cpu,但这种情况比较罕见。
-------------------------------------------------------------------------
===============================================================
1 static inline
2 int select_task_rq(struct task_struct *p, int sd_flags, int wake_flags)
3 {
4 int cpu = p->sched_class->select_task_rq(p, sd_flags, wake_flags);
5
6 /*
7 * In order not to call set_task_cpu() on a blocking task we need
8 * to rely on ttwu() to place the task on a valid ->cpus_allowed
9 * cpu.
10 *
11 * Since this is common to all placement strategies, this lives here.
12 *
13 * [ this allows ->select_task() to simply return task_cpu(p) and
14 * not worry about this generic constraint ]
15 */
16 if (unlikely(!cpumask_test_cpu(cpu, &p->cpus_allowed) ||
17 !cpu_online(cpu)))
18 cpu = select_fallback_rq(task_cpu(p), p);
19
20 return cpu;
21 }
另外的几个宏CPU_CLR\CPU_ISSET\CPU_SET\CPU_ZERO定义也都定义在头文件/usr/include/bits/sched.h内:
1 /* Access functions for CPU masks. */
2 # define __CPU_ZERO(cpusetp) \
3 do { \
4 unsigned int __i; \
5 cpu_set_t *__arr = (cpusetp); \
6 for (__i = 0; __i < sizeof (cpu_set_t) / sizeof (__cpu_mask); ++__i) \
7 __arr->__bits[__i] = 0; \
8 } while (0)
9 # define __CPU_SET(cpu, cpusetp) \
10 ((cpusetp)->__bits[__CPUELT (cpu)] |= __CPUMASK (cpu))
11 # define __CPU_CLR(cpu, cpusetp) \
12 ((cpusetp)->__bits[__CPUELT (cpu)] &= ~__CPUMASK (cpu))
13 # define __CPU_ISSET(cpu, cpusetp) \
14 (((cpusetp)->__bits[__CPUELT (cpu)] & __CPUMASK (cpu)) != 0)
15 #endif
利用这几个宏方便我们操作指定cpu的对应bit位,比如清零,置位等。看一个完整的demo程序:
1 /**
2 * FileName: affinity_demo.c
3 */
4
5 #define _GNU_SOURCE
6
7 #include <stdint.h>
8 #include <stdio.h>
9 #include <sched.h>
10 #include <pthread.h>
11 #include <stdlib.h>
12
13
14 static inline void print_cpu_mask(cpu_set_t cpu_mask)
15 {
16 unsigned char flag = 0;
17 printf("Cpu affinity is ");
18 for (unsigned int i = 0; i < sizeof(cpu_set_t); i ++)
19 {
20 if (CPU_ISSET(i, &cpu_mask))
21 {
22 if (flag == 0)
23 {
24 flag = 1;
25 printf("%d", i);
26 }
27 else
28 {
29 printf(",%d", i);
30 }
31 }
32 }
33 printf(".\n");
34 }
35
36 static inline void get_cpu_mask(pid_t pid, cpu_set_t *mask)
37 {
38 if (sched_getaffinity(pid, sizeof(cpu_set_t), mask) == -1)
39 {
40 perror("get cpu affinity failed.\n");
41 abort();
42 }
43 }
44
45 static inline void set_cpu_mask(pid_t pid, cpu_set_t *mask)
46 {
47 if (sched_setaffinity(pid, sizeof(cpu_set_t), mask) == -1)
48 {
49 perror("set cpu affinity failed.\n");
50 abort();
51 }
52 }
53
54 int main(int argc, char *argv[])
55 {
56 unsigned int active_cpu = 0;
57 cpu_set_t cpu_mask;
58
59 get_cpu_mask(0, &cpu_mask);
60 print_cpu_mask(cpu_mask);
61
62 CPU_ZERO(&cpu_mask);
63 CPU_SET(active_cpu, &cpu_mask);
64 set_cpu_mask(0, &cpu_mask);
65
66 get_cpu_mask(0, &cpu_mask);
67 print_cpu_mask(cpu_mask);
68
69 for(;;)
70 {
71 ;
72 }
73 return 0;
74 }
编译,并运行
gcc affinity_demo.c -o demo -std=c99

程序卡死在死循环,让我们另开一个终端来看看当前系统cpu使用率:
mpstat -P ALL 1
/*
mpstat -P ALL 显示所有CPU信息
mpstat -P n 显示第n个cup信息,n为数字,计数从0开始
*/

0号cpu占用率为百分之百,而其它cpu基本完全空闲。我们再来试试把活动cpu设置为1的情况, 我们将上面程序的第56行修改为:
unsigned int active_cpu = 1;
编译并运行,同时观察一下此时我们的系统CPU使用率发生了什么变化:

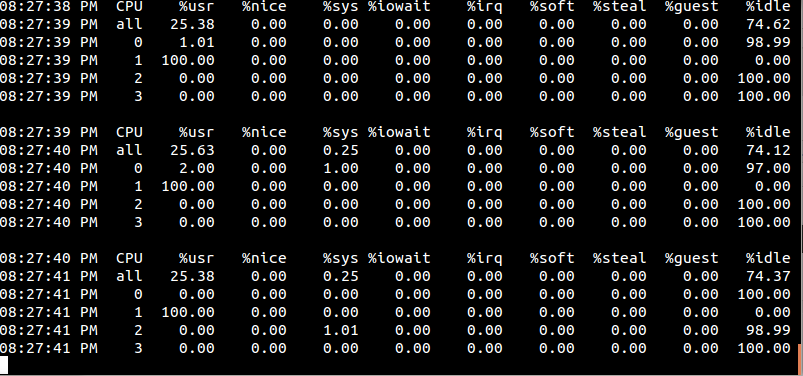
值得注意的是,cpu affinity会被传递给子线程。
1 /**
2 * FileName: affinity_demo.c
3 */
4 #define _GNU_SOURCE
5
6 #include <stdint.h>
7 #include <stdio.h>
8 #include <sched.h>
9 #include <pthread.h>
10 #include <stdlib.h>
11
12 static inline void print_cpu_mask(cpu_set_t cpu_mask)
13 {
14 unsigned char flag = 0;
15 printf("Cpu affinity is ");
16 for (unsigned int i = 0; i < sizeof(cpu_set_t); i ++)
17 {
18 if (CPU_ISSET(i, &cpu_mask))
19 {
20 if (flag == 0)
21 {
22 flag = 1;
23 printf("%d", i);
24 }
25 else
26 {
27 printf(",%d", i);
28 }
29 }
30 }
31 printf(".\n");
32 }
33
34 static inline void get_cpu_mask(pid_t pid, cpu_set_t *mask)
35 {
36 if (sched_getaffinity(pid, sizeof(cpu_set_t), mask) == -1)
37 {
38 perror("get cpu affinity failed.\n");
39 abort();
40 }
41 }
42
43 static inline void set_cpu_mask(pid_t pid, cpu_set_t *mask)
44 {
45 if (sched_setaffinity(pid, sizeof(cpu_set_t), mask) == -1)
46 {
47 perror("set cpu affinity failed.\n");
48 abort();
49 }
50 }
51
52 void *thread_func(void *param)
53 {
54 cpu_set_t cpu_mask;
55 get_cpu_mask(0, &cpu_mask);
56 printf("Slave thread ");
57 print_cpu_mask(cpu_mask);
58 while (1);
59 }
60
61 int main(int argc, char *argv[])
62 {
63 unsigned int active_cpu = 0;
64 cpu_set_t cpu_mask;
65 pthread_t thread;
66
67 get_cpu_mask(0, &cpu_mask);
68 print_cpu_mask(cpu_mask);
69
70 CPU_ZERO(&cpu_mask);
71 CPU_SET(active_cpu, &cpu_mask);
72 set_cpu_mask(0, &cpu_mask);
73
74 get_cpu_mask(0, &cpu_mask);
75 printf("Master thread ");
76 print_cpu_mask(cpu_mask);
77
78 if (pthread_create(&thread, NULL, thread_func, NULL) != 0)
79 {
80 perror("pthread_create failed.\n");
81 }
82 pthread_join(thread, NULL);
83
84 return 0;
85 }
当然,我们可以在子线程主函数thread_func再设置CPU亲缘性
1 void *thread_func(void *param)
2 {
3 cpu_set_t cpu_mask;
4 get_cpu_mask(0, &cpu_mask);
5 printf("Slave thread ");
6 print_cpu_mask(cpu_mask);
7
8 CPU_ZERO(&cpu_mask);
9 CPU_SET(1, &cpu_mask);
10 CPU_SET(2, &cpu_mask);
11 set_cpu_mask(0, &cpu_mask);
12 get_cpu_mask(0, &cpu_mask);
13 printf("Slave thread ");
14 print_cpu_mask(cpu_mask);
15
16 for (;;)
17 {
18 ;
19 }
20 }
编译并运行:
是吧

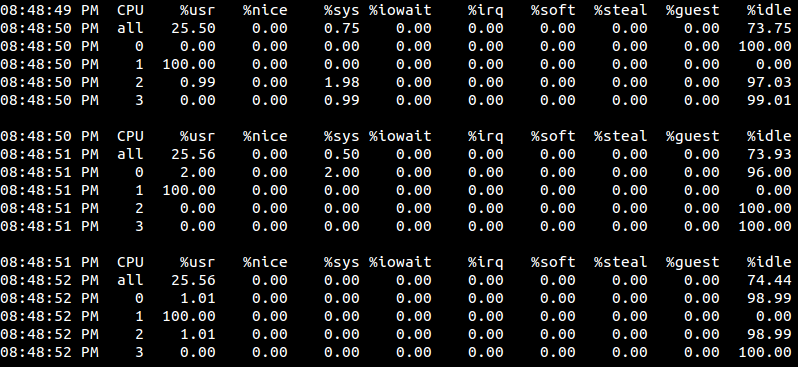
我们发现只有有1号cpu的利用率为百分之百?这是因为线程的执行代码太简单了,只有一个空的循环,而且当前系统也很空闲,即便是分配了两个cpu,进程调度程序也根本就没去调度它,所以它就随机的在某一个cpu上固定的死耗。当然,如果有其它程序要使用cpu1,那么此种情况下demo就可能会被调度到cpu2上去执行。可以试试,开两个终端都执行demo,此时看到的情况就是这样了:

在上面调用sched_getaffinity和sched_setaffinity时,我们传递的第一个参数pid都为0,这意味着修改的亲缘性就是针对当前调用该函数的线程,这也是最方便的,大多数情况下都这么用,除非你确实想修改其它线程的cpu亲缘性。
还有另外相关接口,可以用来指定某个线程的CPU亲缘性:

1 #define _GNU_SOURCE 2 #include <pthread.h> 3 4 int pthread_setaffinity_np(pthread_t thread, size_t cpusetsize, const cpu_set_t *cpuset); 5 int pthread_getaffinity_np(pthread_t thread, size_t cpusetsize, cpu_set_t *cpuset);
在利用NPTL创建出来的线程代码里,为了更好的兼容性,建议使用pthread_getaffinity_np和pthread_setaffinity_np,此时第一个参数不能再传0,可改成pthread_self()即可。而在其它情况下,当然还是使用sched_getaffinity和sched_setaffinity。
1 /**
2 * FileName: affinity_demo.c
3 */
4 #define _GNU_SOURCE
5
6 #include <stdint.h>
7 #include <stdio.h>
8 #include <sched.h>
9 #include <pthread.h>
10 #include <stdlib.h>
11
12 static inline void print_cpu_mask(cpu_set_t cpu_mask)
13 {
14 unsigned char flag = 0;
15 printf("Cpu affinity is ");
16 for (unsigned int i = 0; i < sizeof(cpu_set_t); i ++)
17 {
18 if (CPU_ISSET(i, &cpu_mask))
19 {
20 if (flag == 0)
21 {
22 flag = 1;
23 printf("%d", i);
24 }
25 else
26 {
27 printf(",%d", i);
28 }
29 }
30 }
31 printf(".\n");
32 }
33
34 static inline void get_cpu_mask(pthread_t tid, cpu_set_t *mask)
35 {
36 if (pthread_getaffinity_np(tid, sizeof(cpu_set_t), mask) == -1)
37 {
38 perror("get cpu affinity failed.\n");
39 abort();
40 }
41 }
42
43 static inline void set_cpu_mask(pthread_t tid, cpu_set_t *mask)
44 {
45 if (pthread_setaffinity_np(tid, sizeof(cpu_set_t), mask) == -1)
46 {
47 perror("set cpu affinity failed.\n");
48 abort();
49 }
50 }
51
52 void *thread_func(void *param)
53 {
54 cpu_set_t cpu_mask;
55 get_cpu_mask(pthread_self(), &cpu_mask);
56 printf("Slave thread ");
57 print_cpu_mask(cpu_mask);
58
59 CPU_ZERO(&cpu_mask);
60 CPU_SET(1, &cpu_mask);
61 CPU_SET(2, &cpu_mask);
62 set_cpu_mask(pthread_self(), &cpu_mask);
63 get_cpu_mask(pthread_self(), &cpu_mask);
64 printf("Slave thread ");
65 print_cpu_mask(cpu_mask);
66
67 for (;;)
68 {
69 ;
70 }
71 }
72
73 int main(int argc, char *argv[])
74 {
75 unsigned int active_cpu = 0;
76 cpu_set_t cpu_mask;
77 pthread_t thread;
78
79 get_cpu_mask(pthread_self(), &cpu_mask);
80 print_cpu_mask(cpu_mask);
81
82 CPU_ZERO(&cpu_mask);
83 CPU_SET(active_cpu, &cpu_mask);
84 set_cpu_mask(pthread_self(), &cpu_mask);
85
86 get_cpu_mask(pthread_self(), &cpu_mask);
87 printf("Master thread ");
88 print_cpu_mask(cpu_mask);
89
90 if (pthread_create(&thread, NULL, thread_func, NULL) != 0)
91 {
92 perror("pthread_create failed.\n");
93 }
94 pthread_join(thread, NULL);
95
96 return 0;
97 }
备注
本文中有相当份量的内容参考借鉴了网络上各位网友的热心分享,特别是一些带有完全参考的文章,其后附带的链接内容更直接、更丰富,笔者只是做了一下归纳&转述,在此一并表示感谢。
==================================================================================================================================================================================
Kernel调度器负载均衡(二)
2014年08月10日 20:32:27 cq062364 阅读数:1257
感觉通过贴代码,写注释的方法来描述,往往不能很好的把大体框架,总是陷入代码的细节中,所以这次就少贴代码,只说代码流程。
migration(迁移,移居)
在每个cpu的调度队列上都有一个migration_thread,该migration_thread负责在该队列负载不均衡的时候将该调度队列上的任务,“推送”到其他的cpu上去。该线程往往一般是处于休眠状态,当在load_balance函数中进行move_tasks失败时,就会将该线程唤醒,主动推送任务到其他cpu上。move_tasks有时候失败是因为要移动的任务当前正在执行,但是将migration_thread唤醒后,要移动的任务肯定不处于执行状态,所以再次移动就会成功。此外,migration_thread还负责处理进程迁移请求队列中的请求,下文有介绍。
在主调度器schedule中会判断当前CPU的rq上的进程个数是否为0,如果为0的话,说明该cpu即将处于空闲状态,就调用idle_balance函数,进行负载均衡,看这个cpu能否为其他的cpu分担负载。
---------------------------------------------------------------------------------------------------------------------------------
idle_balance
load_balance_newidle
--------------------------------------------------------------------------------------------------------------------------------------
idle_balance函数会按从低到高的顺序遍历该cpu所在的调度域,在每个调度域上执行函数load_balance_newidle,该函数和load_balance函数很类似,感觉最大的不同就是传递当前cpu空闲状态不同,idle总是等于CPU_NEWLY_IDLE。load_balance_newidle的流程如下:
1.调用find_busiest_group找出最忙的调度组。
2.如果找到最忙的调度组,则在最忙的调度组上调用find_busiest_queue,找出该组上最忙的cpu调度队列。
3.如果能够找到最忙的调度队列,而且调度队列中的任务个数不止1个,则调用move_tasks将最忙的调度队列上的一些任务移动到当前cpu的队列中,让这个即将处于idle状态的cpu帮最忙的cpu分担一些任务。
4.move_tasks移动任务成功还则罢了,否则,更新移动失败的统计信息,然后唤醒migration_thread,用主动推送的方式将任务移动一部分到即将处于空闲的这个cpu上。
第三种进行负载均衡的时机是使用do_execve创建进程时,该函数会调用sched_exec函数。代码如下:
void sched_exec(void)
{
struct task_struct *p = current;
struct migration_req req;
unsigned long flags;
struct rq *rq;
int dest_cpu;
rq = task_rq_lock(p, &flags);
dest_cpu = p->sched_class->select_task_rq(rq, p, SD_BALANCE_EXEC, 0);//调用要创建的进程所属的调度类的select_task_rq函数,该函数会在调度域选出一个最闲的cpu。
if (dest_cpu == smp_processor_id())//如果选出的cpu是当前cpu,则不需要进行进程迁移,退出函数。
goto unlock;
/*
* select_task_rq() can race against ->cpus_allowed
*/
if (cpumask_test_cpu(dest_cpu, &p->cpus_allowed) &&
likely(cpu_active(dest_cpu)) &&
migrate_task(p, dest_cpu, &req)) {//初始化一个进程迁移的migration_req请求,添加到请求队列中。
/* Need to wait for migration thread (might exit: take ref). */
struct task_struct *mt = rq->migration_thread;
get_task_struct(mt);
task_rq_unlock(rq, &flags);
wake_up_process(mt);//唤醒migration_thread,处理进程迁移请求队列中的请求
put_task_struct(mt);
wait_for_completion(&req.done);//等待进程迁移请求处理完毕。
return;
}
unlock:
task_rq_unlock(rq, &flags);
}
负载均衡的第四时机是使用try_to_wake_up函数唤醒进程时。在try_to_wake_up函数中有如下代码:
cpu = select_task_rq(rq, p, SD_BALANCE_WAKE, wake_flags);//选择负载最轻的cpu
if (cpu != orig_cpu)
set_task_cpu(p, cpu);//如果选择的cpu不是当前的cpu,则设置选择到的cpu为该进程运行的cpu。
__task_rq_unlock(rq);
rq = cpu_rq(cpu);//获取所选cpu的运行队列
spin_lock(&rq->lock);
update_rq_clock(rq);
......
activate_task(rq, p, 1);//将当前进程加入到所选则的cpu的运行队列中。
感觉kernel里面关于负载均衡的情况就这四个方面,不知道我列全了没有,也不知道理解的都对不对,希望有大牛能够指点一二,不胜感激。
===========================================================================================================================================================================================================================================================================
实时任务的创建与唤醒
转载自。 https://blog.csdn.net/wennuanddianbo/article/details/55272003
(注:基于4.4.42内核)
摘要
我们使用fork()等类似系统调用创建一个任务时,内核会调用_do_fork() --> copy_process()为新任务创建、初始化task_struct以及thread_info等任务相关信息。
在任务相关的主要数据结构task_struct创建好后,还需要根据任务调度类型,将任务挂到相应的运行队列上,以便有机会得到调度。这是通过wake_up_new_task()来实现。针对实时任务,会将新创建的rt任务挂到其所属的优先级运行队列rt_rq的优先级队列queue[prio]上。
一、整体流程
内核在do_fork()的copy_process()阶段为新任务分配好了task_struct,并为其分配了内核堆栈,还指定了一个默认的运行cpu---即继承于parent的cpu。
但这仅仅是第一步,针对我们这里讨论的实时任务,接下来还需要做如下事情以便cpu能够调度到新任务:
1) 如果当前默认知道的cpu不适合新任务运行,就通过select_task_rq() 为新任务选择一个合适的cpu;
2) 调用set_task_cpu(),根据第1步选择的cpu(有可能是新的cpu,也有可能就是原来默认的)设置新任务的运行cpu、运行队列rt_rq 、rt_se.parent ;
3) 调用activate_task(rq,p,0)来将任务挂到运行队列rt_rq.active.queue[prio]上;
4) 检查新任务是否需要抢占当前任务,如果条件具备则将当前任务(rq->curr)调度出去;
5) 调用task_woken_rt()对当前cpu进行均衡。
这些事情是在wake_up_new_task()中来完成的。
二、选择cpu:select_task_rq()
虽然内核在do_fork()的第一阶段copy_process()虽然已经为新创建的RT任务指定了一个运行cpu,但是这个cpu并不一定适合新任务运行,甚至新任务根本无法在这个默认cpu上得到运行。
因此,出于亲和性以及负载均衡等等原因需要检查这个默认cpu是否适合新任务运行;如果不适合,就需要为其重新找一个运行cpu,这是通过函数select_task_rq(struct task_struct *p, int cpu, int sd_flags, int wake_flags)来实现的。
调用的流程为:
wake_up_new_task(p)
| set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
其中参数p是新创建的实时任务的task_struct结构指针;cpu是新任务thread_info->cpu,也就是来自父进程的默认cpu;sd_flags为SD_BALANCE_FORK表示需要考虑负载均衡;wake_flags为0表示将新任务挂载运行队列的尾端;函数的返回值即是任务新选择的cpu。
2.1 检查默认cpu是否适合新任务
由于新任务的许多内容都是复制于父进程,因而如果新任务就在被创建时的这个cpu上运行可以充分利用缓存;另一方面,如果有亲和性限制或者负载均衡方面的考虑有可能使得新任务不适合在默认cpu上运行,所以这里需要判断以做出正确选择:
这就需要进行检查判断:
1) p->nr_cpus_allowed >1 &&
2) curr存在 &&
3) curr->prio < 100 &&
4) ((curr->nr_cpus_allowed < 2) || (curr->prio <= p->prio))
其中,curr是当前就绪队列上正在运行的任务,即rq->curr,p是新创建的RT任务。
如果上面4个条件依次满足,才会考虑为新任务寻找一个新的运行cpu,否则还是使用原来默认的cpu。
2.2 为新任务另寻新的cpu
如果2.1中4个条件都依次满足,则需要通过find_lowest_rq(struct task_struct *task)函数为新任务task选择一个新的合适的运行cpu,调用链为:
wake_up_new_task(p)
| set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
| find_lowest_rq(struct task_struct *task)
这个查找选择的流程如下所示:
1) 先从task_rq(task)->rd->cpupri中寻找优先级最低的cpu集合,并求出此 最低优先级cpu集合 与task->cpus_allowed交集的集合,放到lowest_mask中,后续都优先在此集合中进行选择;
2) 首先检查新任务的默认cpu是否在lowest_mask这个集合中,如果是,则选择此cpu返回;
3) 其次在当前就绪队列所在的各级sched_domain中查找存在的cpu,如果当前运行的this_cpu在lowest_mask中,且this_cpu又在sched_domain中就优先选择此cpu;(why?因为,this_cpu是task迁移"相对便宜"的cpu);
4) 否则就退而求此次选择lowest_mask与sched_domain中有交集的cpu;
5) 如果在各级sched_domain中也未能找到合适的cpu,就检查正在运行的this_cpu是否在lowest_mask中,如果是的话就选择当前正在运行的this_cpu作为新任务的cpu;
6) 如果前面没有能找到符合要求的cpu,则就在lowest_mask中随便选择一个cpu返回,如果lowest_mask中压根就没有cpu,则返回-1。
如果上面最终没有能够找到一个合适的cpu,则需要通过select_fallback_rq(int cpu, struct task_struct *p)在其他集合中为新任务选择一个cpu,但这种情况比较罕见。
三、指定运行cpu:set_task_cpu()
在通过select_task_rq()为新任务选择了cpu后,就可以通过set_task_cpu(struct task_struct *p, unsigned int new_cpu)函数重新为新任务设置运行cpu和就绪队列rq,调用流程为:
wake_up_new_task(p)
| set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
实际上指定cpu的意义并不仅仅在于设置任务的thread_info->cpu,更重要的是:为任务指定到此cpu的运行队列。 在引入组调度之后,调度器的组织呈现层级结构,每一个任务组在各个cpu上都有对应的调度队列。而且调度队列上挂着的不再只是任务,而是抽象出来的调度实体:它既可以表示一个任务也可以表示一个组。对于实时任务,对应的调度实体为:struct sched_rt_entity。
一个实时任务用 task_struct.rt 成员来表示对应的调度实体sched_rt_entity;每个实时调度实体又根据优先级挂到优先级队列rt_rq.queue[prio]上。
其中调度实体挂接到所属的运行队列rt_rq是sched_rt_entity.rt_rq来结构类型;同时,由于加入了组调度,调度实体还可能有自己所属的上层实体parent (注意:这个parent与我们将进程创建时的父进程不是一个领域也不是一个概念),这个是用sched_rt_entity.parent来表示的。
关于实时任务中的调度实体、运行队列、优先级数组等等相关组织结构可以参考《RT任务调度概览》中的示意图。
而set_task_cpu()的主要任务就是为新任务p指定自己的运行队列和上层调度实体parent。
在2.2节找到新任务的运行cpu后,就需要设置新任务所属的运行队列和所属的parent实体等等信息了。
1) 通过 struct task_group tg = p->sched_task_group 找到新任务p所属的任务组;
2) p->rt.rt_rq = tg->rt_rq[new_cpu] ,设置新任务的运行队列。每个任务组task_group在创建的时候会在各个cpu上创建rt_rq和sched_rt_entity。
3) p->rt.parent = tg->rt_se[cpu],设置新任务的调度实体parent。
这样,新任务p就找到了自己归属的运行队列p->rt.rt_rq以及自己的上层调度实体p->rt.parent。
四、加入就绪队列
4.1 组织结构
我们知道一个任务要得到cpu的调度,必须要加入到运行队列才有可能得到垂青。在第二节和第三节已经分别通过select_task_rq()和set_task_cpu()为新建的实时任务指定了运行cpu和合适运行队列,现在是时候将其挂到运行队列接受调度器的检验了。代码流程:
wake_up_new_task(p)
| set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
| activate_task(rq, p, 0);
新任务p加入到运行队列以等待调度就是由activate_task()来实现的。在探讨activate_task()函数如何把任务加入运行队列之前,我们来看下一个rt_rq的组织结构,以明确我们的新任务该往哪里放,该怎么放,放进去了会有什么影响。
-
/* Real-Time classes' related field in a runqueue: */ -
struct rt_rq { -
struct rt_prio_array active; /* 我们的调度实体最终是放到优先级数组active中 */ -
unsigned int rt_nr_running; -
#if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED -
struct { -
int curr; /* highest queued rt task prio */ -
#ifdef CONFIG_SMP -
int next; /* next highest */ -
#endif -
} highest_prio; -
#endif -
...... -
struct rq *rq; -
struct task_group *tg; -
#endif -
};
这里展示了新任务相关的rt_rq结构成员,新任务最终的归属在优先级数组rt_rq.active成员中,其结构如下所示:
-
/* -
* This is the priority-queue data structure of the RT scheduling class: -
*/ -
struct rt_prio_array { -
DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); /* include 1 bit for delimiter */ -
struct list_head queue[MAX_RT_PRIO]; -
};
可以看到优先级数组结构有两个成员,一个是位图bitmap,一个是list_head数组。
其中链表数组queue[]有MAX_RT_PRIO(即100)个list_head链表,每个链表上挂的任务都具有同一个优先级,即实时任务0~99个优先级,每个任务根据优先级挂到queue[MAX_RT_PRIO]数组的不同链表上;
而bitmap的作用则是一个位图,实际是一个unsigned long型的数组,用以表示优先级队列queue[]上哪个优先级的队列上挂着调度实体,哪些队列是空的。
新任务创建好后,最终最终是要根据自己的优先级prio,挂到自己p->rt.rt_rq(这个rt_rq在第三节已经指定妥当)中的active.queue[prio]队列上。
4.2 详细流程
我们看看activate_task函数的主要处理流程:
activate_task(rq, p, 0)
| enqueue_task(rq, p, flags)
| update_rq_clock(rq);
| enqueue_task_rt(rq, p, flags)
| enqueue_rt_entity(rt_se, flags & ENQUEUE_HEAD)
| enqueue_pushable_task(rq, p)
我们已经知道现在的调度器中实际上是将调度组和任务抽象成了调度实体,所以任务入队,也就是调度实体rt_se入队的主要工作是由函数 enqueue_rt_entity(rt_se, flags & ENQUEUE_HEAD) 来完成。
同时,由于组调度的层级关系,一个调度实体的优先级和调度信息都依赖于其子层级的调度实体和task。例如一个组的优先级就是其下属的优先级最高的那个task。因此实时调度中一个调度实体的“入队”、“出队”可以说是牵一发而动全身,其parent,parent的parent.....其所有的祖先都需要随之发生动荡。
因此新任务加入到运行队列这个过程是相当复杂的。
整个流程如下所示:
1) 将rt_se及其所有祖先的各个调度实体从上到下层(top-rt_se到该rt_se)依次出队;
1.1) 将rt_se的各个层级祖先从上往下组织起来;
1.2) 更新rq->nr_running -= rt_rq->rt_nr_running;
1.3) 从rt_se的顶层祖先开始,从上到下调用__dequeue_rt_entity(rt_se)将各个rt_se出队。
1.3.1) 将rt_se从其所在的优先级队列出队并更新优先级位图;
1.3.2) rt_se出队后需要更新相关信息
1.3.2.1) 更新rt_se->rt_rq的rt_nr_running,即减去rt_se中的rt_nr_running;
1.3.2.2) dec_rt_prio(rt_rq, rt_se_prio(rt_se)) 更新rt_rq的优先级
1.3.2.2.1) 更新rt_rq->highest_prio.curr;
1.3.2.2.2) 如果需要出队的rt_se所在的rt_rq是top rt_rq且top rt_rq的优先级已经改变(可能是在2.1得到更新),则更新rq所在cpu的 cpu priority。
1.3.2.3) 调用dec_rt_migration()更新过载和迁移信息;
1.3.2.3.1) 如果rt_se是一个task,则更新rt_rq->rt_nr_total 、rt_rq->rt_nr_migratory;
1.3.2.3.2) 根据前面更新的rt_nr_total和rt_nr_migratory再更新rt_rq->overload 和 rq->rd->rto_mask;
1.3.2.4) 如果rt_se是boosted的(rt_se或者rt_se->my_q上有优先级翻转的任务),则需要更新rt_rq->rt_nr_boosted。
2) 将rt_se及其所有祖先的各个调度实体从下到上层(从该rt_se到top-rt_se)依次入队;
2.1) 如果rt_se不是任务而是一个组且 (调度受到限制或者组内没有可运行的实体)则返回;
2.2) 否则将rt_se挂到对应优先级队列queue的尾部,并设置rt_se优先级对应的位图;
2.3) rt_se入队后需要更新相关信息,如所属rt_rq的rt_nr_running、rt_rq的优先级、cpu优先级、过载和迁移信息以及rt_nr_boosted等等,参考__dequeue_rt_entity。
3) 调用enqueue_top_rt_rq(&rq->rt)将top rt_rq入队
3.1) 如果top rt_rq调度受限(rt_throttled标志置位 且 rt_rq中没有优先级翻转的task) 或者 top rt_rq没有就绪的实体则直接返回;
3.2) 否则将top rt_rq的rt_nr_running统计到rq->nr_running中,并置rt_rq->rt_queued。
最后,如果新加入到运行队列的任务不是正在运行的,即不是rq->curr且新任务没有亲和性限制,则将新任务加入到pushable链表中并更新就绪队列上的highest prio pushable task。
五、调度curr
一旦新任务加入到了运行队列就有可能比当前任务更有运行资格,这个时候就需要检查是否需要将当前任务rq->curr调度出去,这是调用check_preempt_curr(rq, p, WF_FORK)来实现的。
wake_up_new_task(p)
| set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
| activate_task(rq, p, 0);
| check_preempt_curr(rq, p, WF_FORK);
实际上它完成的主要工作是检查:
1) 如果新任务p->sched_class与当前任务rq->curr->sched_class相等,则调用sched_class->check_preempt_curr(rq, p, flags)检查rq->curr是否需要调度出去;
2) 否则判断新任务p的调度类是否比rq->curr调度类优先级“高”,如果高则将rq上的当前任务调度出去。
由于我们这里讨论的是实时任务,而实时调度类比系统中的大部分任务优先级要“高”,因而当前任务很有可能被调度出去。
然而如果rq->curr任务也是实时调度类,则需要通过check_preempt_curr_rt()函数来进行检查:
1) 如果rq->curr优先级小于新任务p的优先级,则当前任务rq->curr被调度出去;
2) 如果rq->curr优先级与新任务p的优先级相等:
2.1) 若rq->curr不可迁移只能期望将p迁移出去而不将rq->curr调度出去;
2.2) 否则,若新任务p可以迁移那么就期望将p迁移出去,而不将rq->curr调度出去;
2.3) 否则,就是rq->curr可迁移而新任务不可迁移的情况,此时就将rq->curr调度出去,使其有机会到其他cpu的rq上运行。
这里的调度类优先级“高”、“低”是什么意思呢?我们知道现在的调度器有许多不同的调度类,如我们熟悉的实时调度rt_sched_class、公平调度fair_sched_class等等。这些调度类通过一个next指针组织成一个链表,链表越靠前面的调度类越容易被先被cpu"垂青",这就是我这里所说的优先级“高”、“低”。系统中所有的调度类简单组织情况如下:
【stop_sched_class -> dl_sched_class -> rt_sched_class -> fair_sched_class -> idle_sched_class】
其中stop_sched_class没有真正参与调度;dl_sched_class属于dead_line调度类,这类任务没有优先级概念,是系统中最紧迫的任务(这个还没有研究过)。而我们平时关注任务一般都是是rt和fair调度类。
六、队列均衡
由于我们先加了一个rt任务到当前cpu上,这个很可能引发此cpu上的rt任务过载而打乱了cpu上的负载均衡。这个时候就需要调用task_woken_rt(rq, p)来进行检查,以确定是否需要对当前的cpu的rq就绪队列执行push操作,即将当前cpu上的实时任务“推”到其他空闲的cpu上,以达到cpu负载均衡。关于实时任务负载均衡的问题后续再讨论,这里我们重点关注task_woken_rt(rq,p)在满足什么条件才会执行push。
1) 新任务p的p->on_cpu为0 &&
2) 当前任务rq->curr没有设置need reschedule &&
3) 新任务p没有cpu允许迁移 &&
4) rq->curr是dead_line或者rt类型的任务 &&
5) rq->curr不许迁移或者rq->curr优先级高于等于p的优先级。
只有同时满足上面5个条件才会执行push_rt_tasks(rq),以尝试将本cpu的rq中的任务“推”给其他cpu。
七、总结
一个实时任务的整个创建流程(与调度相关的)的主要如下所示:
-
_do_fork() -
| copy_process() -
| wake_up_new_task() -
| select_task_rq() -
| set_task_cpu() -
| activate_task() -
| enqueue_task_rt() -
| check_preempt_curr() -
| task_woken_rt()
其中工作量最大的就是activate_task(),因为实时任务的入队流程是“牵一发而动全身”。当然,由于水平有限,许多小细节都没有分析的明白,还有待加强。有任何建议或者意见都欢迎交流、指正和讨论。
====================================================================================================================================================================================================================================================================================================================================================================
kernel_thread函数的作用是产生一个新的线程
内核线程实际上就是一个共享父进程地址空间的进程,它有自己的系统堆栈.
内核线程和进程都是通过do_fork()函数来产生的,系统中规定的最大进程数与线程数由fork_init来决定:
===========================================================================================================================================================================================================================================================================
linux内核线程migration_thread和kthreadd的创建
分类: LINUX
2012-12-26 15:15:42
linux内核中两大重要的线程,migration_thread负责cpu的负载均衡(将进程从本地队列移动到目标cpu的队列),kthreadd负责为kthread_create_list链表中的成员创建内核线程。
内核版本2.6.24中的引导部分,start_kernel()->rest_init():
点击(此处)折叠或打开
- static void noinline __init_refok rest_init(void)
- __releases(kernel_lock)
- {
- int pid;
- kernel_thread(kernel_init, NULL, CLONE_FS | CLONE_SIGHAND);
- numa_default_policy();
- pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
- kthreadd_task = find_task_by_pid(pid);
- ……
- }
以上依次创建了kernel_init线程和kthreadd线程,rest_init()是在禁用抢占(preempt_disable)的情况下运行,因此保证了kernel_init()运行时kthreadd_task 已经指向ktheadd线程。
kernel_init()调用do_pre_smp_initcalls()->migration_init();创建了负责将进程在cpu间移动(cpu负载均衡)的内核线程migration_thread(每个cpu一个),创建线程是通过将包含待运行函数及参数的kthread_create_info结构挂入kthread_create_list链表,然后唤醒kthreadd_task(即ktheadd线程),而ktheadd线程负责为链表上的每个结构创建相应的线程。
点击(此处)折叠或打开
- void __init migration_init(void)
- {
- void *cpu = (void *)(long)smp_processor_id();
- int err;
- /* Start one for the boot CPU: */
- err = migration_call(&migration_notifier, CPU_UP_PREPARE, cpu);
- BUG_ON(err == NOTIFY_BAD);
- migration_call(&migration_notifier, CPU_ONLINE, cpu);
- register_cpu_notifier(&migration_notifier);
- }
首先直接调用migration_call两次创建了引导cpu的migration_thread线程并唤醒,然后调用register_cpu_notifier()将migration_notifier挂入cpu_chain链表,在之后kernel_init()->smp_init()中将依次对其余未上线的cpu调用cpu_up()->_cpu_up(),该函数分别以参数CPU_UP_PREPARE和CPU_ONLINE调用两次__raw_notifier_call_chain(),实则是运行cpu_chain链表上的函数,也包括了migration_call(),因此其余cpu的migration_thread也得以创建,最终是每个cpu上都有一个migration_thread线程。
点击(此处)折叠或打开
- static int __cpuinit _cpu_up(unsigned int cpu, int tasks_frozen)
- {
- int ret, nr_calls = 0;
- void *hcpu = (void *)(long)cpu;
- unsigned long mod = tasks_frozen ? CPU_TASKS_FROZEN : 0;
- if (cpu_online(cpu) || !cpu_present(cpu))
- return -EINVAL;
- raw_notifier_call_chain(&cpu_chain, CPU_LOCK_ACQUIRE, hcpu);
- ret = __raw_notifier_call_chain(&cpu_chain, CPU_UP_PREPARE | mod, hcpu,
- -1, &nr_calls);
- ……
- /* Now call notifier in preparation. */
- raw_notifier_call_chain(&cpu_chain, CPU_ONLINE | mod, hcpu);
- ……
- }
/*
1、以CPU_UP_PREPARE为参数调用时,创建migration_thread线程,并绑定到cpu,设置调用策略为实时进程SCHED_FIFO,
优先级99,cpu运行队列的migration_thread指向该内核线程,此时线程是不可中断睡眠状态。
2、以CPU_ONLINE为参数调用时,唤醒cpu_rq(cpu)->migration_thread指向的migration_thread线程。
*/
点击(此处)折叠或打开
- static int __cpuinit
- migration_call(struct notifier_block *nfb, unsigned long action, void *hcpu)
- {
- struct task_struct *p;
- int cpu = (long)hcpu;
- unsigned long flags;
- struct rq *rq;
- switch (action) {
- case CPU_LOCK_ACQUIRE:
- mutex_lock(&sched_hotcpu_mutex);
- break;
- case CPU_UP_PREPARE:
- case CPU_UP_PREPARE_FROZEN:
- p = kthread_create(migration_thread, hcpu, "migration/%d", cpu);
- if (IS_ERR(p))
- return NOTIFY_BAD;
- kthread_bind(p, cpu);
- /* Must be high prio: stop_machine expects to yield to it. */
- rq = task_rq_lock(p, &flags);
- __setscheduler(rq, p, SCHED_FIFO, MAX_RT_PRIO-1);
- task_rq_unlock(rq, &flags);
- cpu_rq(cpu)->migration_thread = p;
- break;
- case CPU_ONLINE:
- case CPU_ONLINE_FROZEN:
- /* Strictly unnecessary, as first user will wake it. */
- wake_up_process(cpu_rq(cpu)->migration_thread);
- break;
- ……
- }
/*创建线程是通过将包含线程运行函数和参数的kthread_create_info结构挂入kthread_create_list链表,
并唤醒内核线程kthreadd_task对链表上的各个线程创建需求进行处理来实现的,当创建成功后返回进程指针,
这是通过wait_for_completion(&create.done)进行同步的。此内核线程创建函数不负责将线程绑定到cpu,绑定工作
须由调用函数负责。
*/
点击(此处)折叠或打开
- struct task_struct *kthread_create(int (*threadfn)(void *data),
- void *data,
- const char namefmt[],
- ...)
- {
- struct kthread_create_info create;
- create.threadfn = threadfn;
- create.data = data;
- init_completion(&create.started);
- init_completion(&create.done);
- spin_lock(&kthread_create_lock);
- list_add_tail(&create.list, &kthread_create_list);
- wake_up_process(kthreadd_task);
- spin_unlock(&kthread_create_lock);
- wait_for_completion(&create.done);
- ……
- return create.result;
- }
===========================================================================================================================================================================================================================================================================
Idle进程的切换过程
分类: C/C++
2015-06-21 11:52:55
原文地址:Idle进程的切换过程 作者:djjsindy
每个cpu都有自己的运行队列,如果当前cpu上运行的任务都已经dequeue出运行队列,而且idle_balance也没有移动到当前运行队列的任务,那么schedule函数中,按照rt ,cfs,idle这三种调度方式顺序,寻找各自的运行任务,那么如果rt和cfs都未找到运行任务,那么最后会调用idle schedule的idle进程,作为schedule函数调度的下一个任务。
kernel/sched.c 中的schedule()函数中的片段
- if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
- //state大于0代表prev也就是当前运行的任务不是running状态,并且没有标记 PREEMPT_ACTIVE,就表示当前的运行的任务没有必要停留在运行队列中了
- if (unlikely(signal_pending_state(prev->state, prev))) //如果当前进程标记了状态是TASK_INTERRUPTIBLE,并且还有信号未处理,那么没有必要从运行队列中移除这个进程
- prev->state = TASK_RUNNING;
- else
- deactivate_task(rq, prev, DEQUEUE_SLEEP); //从运行队列中移除这个进程
- switch_count = &prev->nvcsw;
- }
- pre_schedule(rq, prev);
- if (unlikely(!rq->nr_running)) //如果当前运行队列没有进程可以运行了,就balance其他运行队列的任务到当前运行队列,这里balance的具体过程暂时不说
- idle_balance(cpu, rq);
- put_prev_task(rq, prev);
- next = pick_next_task(rq); //按照rt,cfs,idle优先级的顺序挑选进程,如果在rt和cfs中都没有找到能够运行的任务,那么当前cpu会切换到idle进程。
这里 PREEMPT_ACTIVE是个标志位,由于进程由于系统调用或者中断异常返回到用户态之前,都要判断是否可以被抢占,会首先判断preempt_count,等于0的时候表示没有禁止抢占,然后再去判断是否标记了need_resched,如果标记了,在去调用schedule函数,如果在某些时候禁止了抢占,禁止了一次就要preempt_count加1。可以肯定的一点是进程的state和是否在运行队列的因果关系并不是十分同步的,修改了进程的状态后,可能还需要做一些其他的工作才去调用schedule函数。引用一下其他人的例子。
- for (;;) {
- prepare_to_wait(&wq, &__wait,TASK_UNINTERRUPTIBLE);
- if (condition)
- break;
- schedule();
- }
可以看出在修改了进程的state之后,并不会立刻调用schedule函数,即使立刻调用了schedule函数,也不能保证在schedule函数之前的禁止抢占开启之前有其他的抢占动作。毕竟修改进程的state和从运行队列中移除任务不是一行代码(机器码)就能搞定的事情。所以如果在修改了进程的状态之后和schedule函数禁止抢占之前有抢占动作(可能是中断异常返回),如果这个时候进程被其他进程抢占,这个时候把当前进程移除运行队列,那么这个进程将永远没有机会运行后面的代码。所以这个时候在抢占的过程之前将preempt_count标记PREEMPT_ACTIVE,这样抢占中调用schedule函数将不会从当前运行队列中移除当前进程,这样才有前面分析schedule函数代码,有判断进程state同时判断preempt_count未标记PREEMPT_ACTIVE的情况。
在当前进程被移除出运行队列之前还需要判断是否有挂起的信号需要处理,如果当前进程的状态是TASK_INTERRUPTIBLE或者TASK_WAKEKILL的时候,如果还有信号未处理,那么当前进程就不需要被移除运行队列,并且将state置为running。
- static inline int signal_pending_state(long state, struct task_struct *p)
- {
- if (!(state & (TASK_INTERRUPTIBLE | TASK_WAKEKILL))) //首先判断状态不是这两个可以处理信号的状态就直接返回0,后面的逻辑不考虑了
- return 0;
- if (!signal_pending(p)) //如果没有信号挂起就不继续了
- return 0;
- return (state & TASK_INTERRUPTIBLE) || __fatal_signal_pending(p); //如果有信号
- }
说下 put_prev_task的逻辑,按照道理说应该是rt,cfs,idle的顺序寻找待运行态的任务。
- pick_next_task(struct rq *rq)
- {
- const struct sched_class *class;
- struct task_struct *p;
- /*
- * Optimization: we know that if all tasks are in
- * the fair class we can call that function directly:
- */
- //这里注释的意思都能看懂,如果rq中的cfs队列的运行个数和rq中的运行个数相同,直接调用cfs中 的pick函数,因为默认的调度策略是cfs。
- if (likely(rq->nr_running == rq->cfs.nr_running)) {
- p = fair_sched_class.pick_next_task(rq);
- if (likely(p))
- return p;
- }
- //这里 sched_class_highest就是rt_sched_class,所以前面没有选择出任务,那么从rt开始挑选任务,直到idle
- class = sched_class_highest;
- for ( ; ; ) {
- p = class->pick_next_task(rq);
- if (p)
- return p;
- /*
- * Will never be NULL as the idle class always
- * returns a non-NULL p:
- */
- class = class->next;
- }
- }
从每个调度类的代码的最后可以看出这个next关系
sched_rt.c中:
- static const struct sched_class rt_sched_class = {
- .next = &fair_sched_class,
sched_fair.c中:
- static const struct sched_class fair_sched_class = {
- .next = &idle_sched_class,
那么可以试想如果rt和cfs都没有可以运行的任务,那么最后就是调用idle的pick_next_task函数
sched_idletask.c:
- static struct task_struct *pick_next_task_idle(struct rq *rq)
- {
- schedstat_inc(rq, sched_goidle);
- calc_load_account_idle(rq);
- return rq->idle; //可以看到就是返回rq中idle进程。
- }
这idle进程在启动start_kernel函数的时候调用init_idle函数的时候,把当前进程(0号进程)置为每个rq的idle上。
kernel/sched.c:5415
- rq->curr = rq->idle = idle;
这里idle就是调用start_kernel函数的进程,就是0号进程。
0号进程在fork完init进程等之后,进入cpu_idle函数,大概的逻辑是for循环调用hlt指令,每次hlt返回后,调用schedule函数,具体的流程现在还没太看懂,可以看到的是在具体的逻辑在default_idle函数中,调用了safe_halt函数
- static inline void native_safe_halt(void)
- {
- asm volatile("sti; hlt": : :"memory");
- }
关于hlt指令的作用是:引用wiki百科
In the x86 computer architecture, HLT (halt) is an assembly language instruction which halts the CPU until the next external interrupt is fired.[1] Interrupts are signals sent by hardware devices to the CPU alerting it that an event occurred to which it should react. For example, hardware timers send interrupts to the CPU at regular intervals.
The HLT instruction is executed by the operating system when there is no immediate work to be done, and the system enters its idle state. In Windows NT, for example, this instruction is run in the "System Idle Process".
可以看到注释的意思是,hlt指令使得cpu挂起,直到有中断产生这个时候cpu重新开始运行。所以时钟中断会唤醒正在hlt中的cpu,让它调用schedule函数,检测是否有新的任务在rq中,如果有的话切换到新的任务,否则继续执行hlt,cpu继续挂起。
参考文章
1.http://blog.csdn.net/dog250/article/details/5303547
2.http://en.wikipedia.org/wiki/HLT
===========================================================================================================================================================================================================================================================================
CFS调度器(1)-基本原理
蜗窝科技 2018-10-07 38 阅读
前言
首先需要思考的问题是:什么是调度器(scheduler)?调度器的作用是什么?调度器是一个操作系统的核心部分。可以比作是CPU时间的管理员。调度器主要负责选择某些就绪的进程来执行。不同的调度器根据不同的方法挑选出最适合运行的进程。目前Linux支持的调度器就有RT scheduler、Deadline scheduler、CFS scheduler及Idle scheduler等。我想用一系列文章呈现Linux 调度器的设计原理。