前言
高并发场景下使用缓存可以有效降低并发QPS对于数据库的压力,但是使用缓存就必须面对数据一致性的问题。
高并发处理
有效利用java多线程特性并行计算,充分利用CPU资源。 在序列化处理上考虑更好的工具,比如之前数据是用XML,JSON存储,随着访问量的飙升,CPU和带宽带来了很大的压力,后来我们自己定义了一种传输协议和序列化方案,一方面数据压缩到原来的30%~40%,极大节约了宽带,同时CPU的运算量大大降低,服务器数量也随之减少。
比如我们之前用Fastjson,正常情况下确实解析很快,但是一旦并发量上来后,就会越来越吃内存,甚至JVM很快内存溢出。 原因是Fastjson设计的初衷是先把整个数据装载至内存,然后解析,所以执行很快,但会相当消耗内存。
所以Fastjson是有他适合的使用场景的,作为架构师需要对自己的场景有很好的理解,在技术选型上有很好的取舍。
同时引入NIO解决过多长连接导致的系统稳定性和开销问题。
消息队列
为完成数据异步更新到缓存,可以采用消息队列方式(主备AMQ)来管理异步任务。 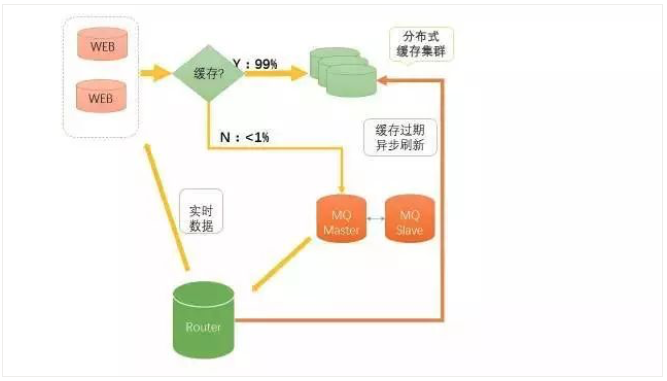 异步更新缓存的核心逻辑是,如何判断缓存过期。上图中引入了一个Router。 举个例子:运营会设置细化一个航班段的缓存有效期,比如北京到纽约,一般来说买机票的人不多,航班信息缓存几天没有问题,但如果是北京到上海,可能只能最多5分钟了。
异步更新缓存的核心逻辑是,如何判断缓存过期。上图中引入了一个Router。 举个例子:运营会设置细化一个航班段的缓存有效期,比如北京到纽约,一般来说买机票的人不多,航班信息缓存几天没有问题,但如果是北京到上海,可能只能最多5分钟了。
Router解决的复杂工作,我们叫“去伪存真”。进行一些规则设计,这个规则设计需要很灵活,也可以引入消息队列进行异步化解耦,进行很好的读写分离。
整体系统流转
当缓存系统相关数据过期后,前台搜索告知MQ有实时搜索任务,MQ统一把异步任务交给Router,这是Router不会直接请求下游数据,而是找Node池。
Node池会动态分配一个Node节点给Router,最后Router查找Node节点映射的数据,最后异步更新到缓存数据。