目的
- 设计一个简化,高效的KV存储引擎。
- 要求提供write,read,range搜索接口。
要求
- 并发写入数据性能。
- 任意执行kill -9来模拟进程意外退出而数据不丢失。
IO
- key固定为8字节,可以用long表示。
- value为4kb,4kb整数落盘是非常磁盘IO友好的。
- 4kb可以在内存中做索引,可以使用int而不是long来记录数据偏移,内存占用会减少一半。
kill -9 数据不丢失
光使用内存做存储很难满足这一点。但是没有要求断电不丢失,也就是说:可以使用pageCache来做写入缓存。 所以想到使用pageCache来充当数据和索引的写入缓冲(两者策略不同)。 方案具体可以参考ES的pageCache方案。
随机读写
按照随机写,随机读,顺序读进行实验。 随机写阶段不需要在内存维护索引,可以直接落盘。 随机读和顺序读,磁盘均存在数据,恢复索引可以采用多线程并发恢复。
pageCache处理
由于采用了pageCache,采用脚本方式清空pageCache会比较耗时。 所以不能无节制的使用pageCache,所以准备引入Direct IO。
文件IO
由于key可以均匀分布,采用数据分区方式,可以大大减少顺序读写的锁冲突,key分布均匀可以按照key搞n位来做hash,可以确保key两个分区之间整体有序,于是可以尝试将数据分成1024,2048个分区。
架构设计
随机写入key时,可以根据key进行hash将随机写转换成对应分区的文件顺序写。 
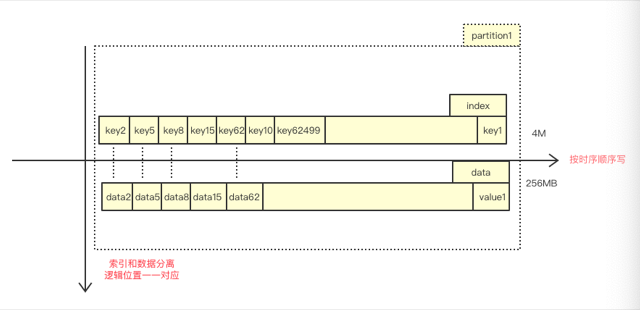
内存维护有序的 key[1024][625000] 数组和 offset[1024][625000] 数组。
利用数据分布均匀特性,将全局数据hash为1024分区,每个分区存放两类文件:索引文件和数据文件(对kafka熟悉的同学,是不是很亲切)。
在随机写入阶段,根据key获得该数据对应分区位置,按照时序,顺序追加到文件尾部,将全局随机转换为局部顺序。
利用索引和数据一一对应特性,不需要将数据的逻辑偏移落盘,在恢复阶段可以按照恢复key的测序,反推value的逻辑偏移量。
由于做了分区,在range查询阶段,partition(N)中任何一个数据一定大于partition(N-1)中任何一个数据,于是我们可以大块的读,将一个partition整体读进内存,给64个线程消费。
读盘线程负责按分区读盘进入内存,64个消费线程消费内存,按照key顺序访问内存,进行回调。
优化
使用pageCache实现写入缓冲区
磁盘IO类型的系统,第一步是测量磁盘IOPS及多少个线程一次读写多大的缓存能够打满IO,在固定64线程写入前提下,16kb,64kb均可达到理想IOPS,所以可以为每个分区分配一个写入缓存,凑齐4个value落盘。
由于要求kill -9不丢失数据,不能简单的在内存中分配一个ByteBuffer.allocate(4096*4);,可以考虑mmap内存映射一片写入缓冲,凑齐4个刷盘,这样kill -9之后,pageCache不会丢失。
索引文件落盘比较简单,key固定为8b,所以mmap可以发挥写小数据的优势,将pageCache利用起来,mmap相比filechannel写索引快3s左右。
随机写入后不会立即随机读,所以不需要在写入时维护内存索引,只需要在恢复阶段恢复索引顺序,反推出数据的逻辑偏移,因为key和value在同一个分区的位置是一一对应的。
恢复阶段
需要在数据库引擎启动时,将索引从数据文件恢复到内存中。
由于有1024个分区,可以使用64个线程并发恢复索引,使用快速排序对 key[1024][62500] 数组和 offset[1024][62500] 进行 sort,之后再 compact,对 key 进行去重。
数据随机读取
根据key定位到分区,之后在有序的key数据中进行二分查找key/offset,拿到数据的逻辑偏移和分区编号,可以随机读取了。
数据顺序读取
顺序读取思路是生产者消费者模型,n个生产者从磁盘读数据放入内存,64个消费线程消费同时判断内存数据以验证数据。 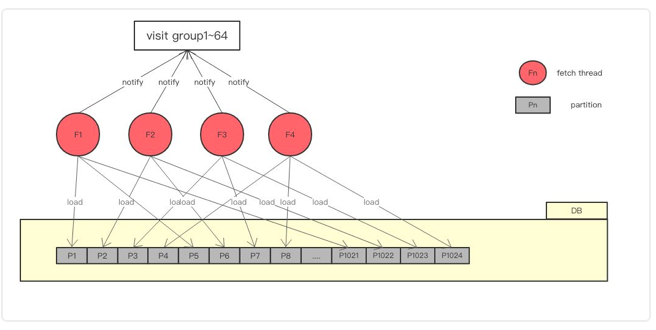
直接内存的使用和JVM调优
堆外内存的好处是大大减少了一份内存拷贝,并且对gc友好。
-
server
-
Xms2560m
-
Xmx2560m
-
XX
:
MaxDirectMemorySize
=
1024m
-
XX
:
NewRatio
=
4
-
XX
:+
UseConcMarkSweepGC
-
XX
:+
UseParNewGC
-
XX
:-
UseBiasedLocking
- young区过大,对象在年轻代呆的太久,多次拷贝。
- old区太小,会频繁触发old区的cms gc。
对于那些需要反复new出来的东西,都可以池化,分配内存在回收也是不小的开销,直接可以使用threadlocal缓存搞定。
减少线程切换
io线程的切换成本很高,为了减少io线程的时间片流失可以考虑使用while(true)轮训,也可以采用sleep(1us)避免cpu空转带来的整体性能问题。
机器抖动在所难免,避免IO切换不能靠while(true),cpu级别的优化可以专门腾出4个核心专门给IO线程使用,避免IO线程的时间片征用(采用Affinity )。