都是自己从网上搜集的一些自己感兴趣的东西
----------------------------------------------------------------------------------------------------------------------------------------
Flink是什么?
- Apache Flink是一个面向分布式数据留处理和批量数据处理的开源计算平台,提供支持流处理和批处理两种类型应用的功能
-
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
- Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
- 什么是有状态的计算?
计算任务的结果不仅仅依赖于输入,还依赖于它的当前状态,其实大多数的计算都是 有状态的计算。 比如wordcount,给一些word,其计算它的count,这是一个很常见的业务场景。count做 为输出,在计算的过程中要不断的把输入累加到count上去,那么count就是一个 state。
Flink是怎么来的?
- 在2008 年,Flink 是柏林理工大学一个研究性项目。在 2014 被 Apache 孵化器所接受,然后迅速地成为了 ASF(Apache Software Foundation)的顶级项目之一。
相关的两个框架
- spark于2009年诞生于加州大学伯克利分校AMPLab(AMP:Algorithms,Machines,People),它最初属于伯克利大学的研究性项目,后来在2010年正式开源,并于 2013 年成为了 Apache 基金项目,到2014年便成为 Apache 基金的顶级项目。
- Twitter于2011年 对 Storm 开源。Storm的作者是Nathan Marz,Nathan Marz在BackType公司工作的时候有了Storm的点子并独自一人实现了Storm。在2011年Twitter准备收购BackType之际,Nathan Marz为了提高Twitter对BackType的估值,在一篇博客里向外界介绍了Storm。Twitter对这项技术非常感兴趣,因此在Twitter收购BackType的时候Storm发挥了重大作用。后来Nathan Marz开源Storm时,也借着Twitter的品牌影响力而让Storm名声大震!
个人觉得Flink具备什么特点呢?
- Flink兼备了spark的基于内存的快速计算,又实现了毫秒级的实时计算。并实现了很多更加方便快捷的东西,将对此进行学习。
开始学习
Flink生态圈是什么?
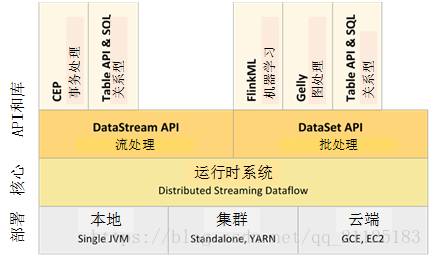
图1 Flink的生态圈
- 从部署模式上讲,Flink支持local模式、集群模式(standalone集群或者Yarn集群)、Cloud端部署。
- Flink的核心是DistributedStreaming Dataflow引擎,它用来执行dataflow程序。Flink的核心运行引擎可以看作是Streaming Dataflow引擎,DataSetAPI和DataStreamAPI都可以通过该引擎创建运行时程序。
- Flink中有两个核心API:用于处理有界数据集DataSet API(通常称为批处理)和用于处理无界数据流的DataStream API(通常称为实时流处理)。
- 在核心API的基础上,Flink还绑定了用于特定于领域的库和API,目前是用于机器学习的FlinkML, 用于图处理的Gelly和用于sql的操作的Table API。从部署模式上讲,Flink支持local模式、集群模式(standalone集群或者Yarn集群)、Cloud端部署。
Flink的架构是什么?

图2 Flink的架构
matser-slaver
- JobManagers(master):用于协调分布式程序执行。它们用来调度task,协调检查点,协调失败时恢复等
- TaskManagers(worker):用于执行一个dataflow的task(或者特殊的subtask)、数据缓冲和data stream的交换。
Flink程序的核心概念是什么?
flink程序三个基本构建块
- source:数据源
- transformations:基于数据流的一组operate操作
- sink:数据处理结果的目的地
并行数据流
- 在flink中,transformation是由一组operator组成,每一个operator被分割成operator subtask,同一个operator的多个 subtasks在不同的线程、不同的物理机或不同的容器中彼此互不依赖得并行执行。
- Stream在operator有两种形式:One-to-one:类似于spark中的窄依赖;Redistributing:类似于spark中的宽依赖