版权声明: https://blog.csdn.net/ah_quwei/article/details/81384830
Spark 是基于内存计算的大数据并行计算框架。因为其基于内存计算,比Hadoop 中 MapReduce 计算框架具有更高的实时性,同时保证了高效容错性和可伸缩性。从 2009 年诞生于 AMPLab 到现在已经成为 Apache 顶级开源项目,并成功应用于商业集群中,学习 Spark 就需要了解其架构。
Spark 架构图如下:
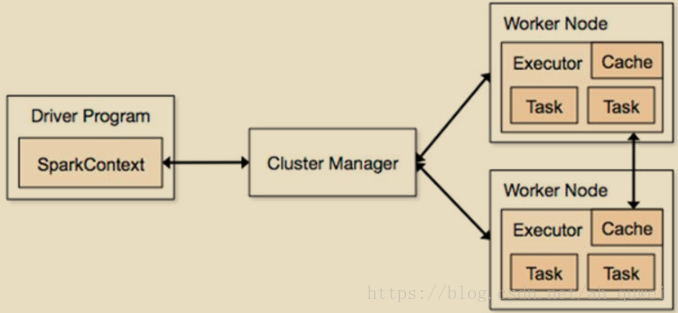
Spark架构使用了分布式计算中master-slave模型,master是集群中含有master进程的节点,slave是集群中含有worker进程的节点。
①Driver Program :运⾏main函数并且新建SparkContext的程序。
②Application:基于Spark的应用程序,包含了driver程序和集群上的executor。
③Cluster Manager:指的是在集群上获取资源的外部服务。目前有三种类型 :
Standalone:spark原生的资源管理,由Master负责资源的分配
ApacheMesos:与hadoop MR兼容性良好的一种资源调度框架
HadoopYarn: 主要是指Yarn中的ResourceManager
④Worker Node: 集群中任何可以运行Application代码的节点,在Standalone模式中指的是通过slaves文件配置的Worker节点,在Spark on Yarn模式下就是NodeManager节点
⑤Executor:是在一个worker node上为某应⽤启动的⼀个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。每个应⽤都有各自独立的executor。
⑥Task :被送到某个executor上的工作单元。