原文简介:
《Pro SQL Server Internals》2nd edition(专业SQL服务器内部-第二版)
作者:Dmitri Korotkevitch
作者简介:
Dmitri Korotkevitch是Microsoft Data Platform MVP和Microsoft Certified Master (SQL Server 2008),他拥有20多年的IT经验,包括作为应用程序和数据库开发人员、数据库管理员和数据库架构师与Microsoft SQL Server一起工作的经验。Dmitri专门从事复杂OLTP系统的设计、开发和性能调优,这些系统每秒处理数千个事务。Dmitri经常在各种Microsoft和SQL PASS活动上发言,他为世界各地的客户提供SQL Server培训;
作者的博客地址:http://aboutsqlserver.com
原文链接:http://www.doc88.com/p-4042504089228.html
设计和优化索引
It is impossible to define an indexing strategy that will work everywhere. Every system is unique and requires its own indexing approach based on workload, business requirements, and quite a few other factors. However, there are several design considerations and guidelines that can be applied in every system. The same is true when we are optimizing existing systems. While optimization is an iterative process that is unique in every case, there is a set of techniques that can be used to detect inefficiencies in every database system. In this chapter, we will cover a few important factors that you will need to keep in mind when designing new indexes and optimizing existing systems.
定义一个索引方法在每一处都能有效这是不可能的,每一个系统都是独一的,需要基于工作负载的索引方法,商业要求和很多其他的因素,然而,有很多的设计考虑和指导都能够呗应用到每一个系统,当我们在优化系统时也是同样的,虽然优化是一个迭代过程,在每一个的系统中都是独特的,在每一个数据系统中有一组技术能够用于侦探出无效性。在这一章节中,我们将会介绍很多当你在设计新的索引和优化现有的数据库,你必须要记住的重要因素;
集群索引设计注意事项
Every time you change the value of a clustered index key, two things happen. First, SQL Server moves the row to a different place in the clustered index page chain and in the data files. Second, it updates the row-id , which is the clustered index key. The row-id is stored and needs to be updated in all nonclustered indexes. That can be expensive in terms of I/O, especially in the case of batch updates. Moreover, it can increase the fragmentation of the clustered index and, in cases of row-id size increase, of the nonclustered indexes. Thus, it is better to have a static clustered index where key values do not change.
每次更改聚集索引键的值时,都会发生两件事情。首先,SQL Server将行移动到集群索引页链和数据文件中的不同位置。其次,它更新行id,这是聚集索引键。行id存储在所有非集群索引中,需要更新。就I/O而言,这可能很昂贵,尤其是在批量更新的情况下。此外,它还可以增加聚集索引的碎片,并且在行id大小增加的情况下,还可以增加非聚集索引的碎片。因此,最好在键值不变的情况下使用静态聚集索引。
All nonclustered indexes use a clustered index key as the row-id . A too-wide clustered index key increases the size of nonclustered index rows and requires more space to store them. As a result, SQL Server needs to process more data pages during index- or range-scan operations, which makes the index less efficient.
所有非聚集索引都使用聚集索引键作为行id。太宽的聚集索引键会增加非聚集索引行的大小,并需要更多的空间来存储它们。因此,SQL Server在索引或范围扫描操作期间需要处理更多的数据页,这会降低索引的效率。
In cases of non-unique nonclustered indexes, the row-id is also stored at non-leaf index levels, which, in turn, reduces the number of index records per page and can lead to extra intermediate levels in the index. Even though non-leaf index levels are usually cached in memory, this introduces additional logical reads every time SQL Server traverses the nonclustered index B-Tree.
对于非惟一的非集群索引,行id也存储在非叶索引级别,这反过来减少了每页索引记录的数量,并可能导致索引中额外的中间级别。尽管非叶索引级别通常缓存在内存中,但每次SQL Server遍历非集群索引b树时,都会引入额外的逻辑读取。
Finally, larger nonclustered indexes use more space in the buffer pool and introduce more overhead during index maintenance. Obviously, it is impossible to provide a generic threshold value that defines the maximum acceptable size of a key that can be applied to any table. However, as a general rule, it is better to h ave a narrow clustered index key, with the index key as small as possible.
最后,较大的非集群索引在缓冲池中使用更多空间,并在索引维护期间引入更多开销。显然,不可能提供一个通用阈值来定义可以应用于任何表的键的最大可接受大小。但是,通常情况下,h最好拥有一个窄的聚集索引键,索引键越小越好。
It is also beneficial to have the clustered index be defined as unique . The reason this is important is not obvious. Consider a scenario in which a table does not have a unique clustered index and you want to run a query that uses a nonclustered index seek in the execution plan. In this case, if the row-id in the nonclustered index were not unique, SQL Server would not know what clustered index row to choose during the key lookup operation.
将聚集索引定义为惟一的也是有益的。这一点很重要的原因并不明显。考虑这样一个场景:表没有惟一的集群索引,您希望在执行计划中运行使用非集群索引查询的查询。在这种情况下,如果非集群索引中的行id不是惟一的,SQL Server将不知道在键查找操作期间选择什么集群索引行。
SQL Server solves such problems by adding another nullable integer column called uniquifier to nonunique c lustered indexes. SQL Server populates uniquifiers with NULL for the first occurrence of the key value, autoincrementing it for each subsequent duplicate inserted into the table.
SQL Server通过向非惟一c排序的索引中添加另一个名为uniquifier的可空整数列来解决此类问题。对于键值的第一次出现,SQL Server用NULL填充uniquifiers,并为插入到表中的每个后续重复值自动递增。
The number of possible duplicates per clustered index key value is limited by integer domain values. You cannot have more than 2,147,483,648 rows with the same clustered index key. This is a theoretical limit, and it is clearly a bad idea to create indexes with such poor selectivity.
每个群集索引键值可能的重复次数受整型域值的限制。使用相同的聚集索引键,不能有超过2,147,483,648行。这是一个理论上的限制,创建选择性如此差的索引显然不是一个好主意。
Let’s look at the overhead introduced by uniquifiers in non-unique clustered indexes. The code shown in Listing 7-1 creates three different tables of the same structure and populates them with 65,536 rows each. Table dbo.UniqueCI is the only table with a unique clustered index defined. Table dbo.NonUniqueCINoDups does not have any duplicated key values. Finally, table dbo.NonUniqueCDups has a large number of duplicates in the index.
让我们看看在非惟一聚集索引中uniquifiers引入的开销。清单7-1所示的代码创建了三个相同结构的不同表,每个表都填充了65,536行。dbo表。UniqueCI是唯一定义了唯一聚集索引的表。dbo表。NonUniqueCINoDups没有任何重复的键值。最后,dbo表。NonUniqueCDups在索引中有大量的副本。
清单7 - 1。非惟一聚集索引:表创建
create table dbo.UniqueCI
(
KeyValue int not null,
ID int not null,
Data char(986) null,
VarData varchar(32) not null
constraint DEF_UniqueCI_VarData
default 'Data'
);
create unique clustered index IDX_UniqueCI_KeyValue
on dbo.UniqueCI(KeyValue);
create table dbo.NonUniqueCINoDups
(
KeyValue int not null,
ID int not null,
Data char(986) null,
VarData varchar(32) not null
constraint DEF_NonUniqueCINoDups_VarData
default 'Data'
);
create /*unique*/ clustered index IDX_NonUniqueCINoDups_KeyValue
on dbo.NonUniqueCINoDups(KeyValue);
create table dbo.NonUniqueCIDups
(
KeyValue int not null,
ID int not null,
Data char(986) null,
VarData varchar(32) not null
constraint DEF_NonUniqueCIDups_VarData
default 'Data'
create /*unique*/ clustered index IDX_NonUniqueCIDups_KeyValue
on dbo.NonUniqueCIDups(KeyValue);
-- Populating data
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.UniqueCI(KeyValue, ID)
select ID, ID from IDs;
insert into dbo.NonUniqueCINoDups(KeyValue, ID)
select KeyValue, ID from dbo.UniqueCI;
insert into dbo.NonUniqueCIDups(KeyValue, ID)
select KeyValue % 10, ID from dbo.UniqueCI;
Now, let’s look at the clustered indexes’ physical statistics for each table. The code for this is shown in Listing 7-2 , and the results are shown in Figure 7-1 .
Listing 7-2. Nonunique clustered index : Checking clustered indexes’ row sizes
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys.dm_db_index_physical_stats(db_id(), object_id(N'dbo.UniqueCI'), 1, null ,'DETAILED');
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
, avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.NonUniqueCINoDups'), 1, null ,'DETAILED');
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.NonUniqueCIDups'), 1, null ,'DETAILED');
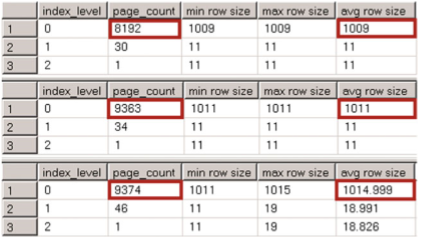
7 - 1所示。非唯一聚集索引:聚集索引的行大小
Even though there are no duplicated key values in the dbo.NonUniqueCINoDups table, there are still two extra bytes added to the row. SQL Server stores a uniquifier in the variable-length section of the data, and those two bytes are added by yet another entry in a variable-length data offset array.
即使dbo中没有重复的键值。表中,仍然有两个额外的字节添加到行中。SQL Server在数据的可变长度部分存储一个uniquifier,这两个字节由可变长度数据偏移数组中的另一个条目添加。
In the case, when a clustered index has duplicate values, uniquifiers add yet another four bytes, which makes for an overhead of six bytes total.
在这种情况下,当集群索引具有重复值时,uniquifiers将再添加4个字节,这将导致总共6个字节的开销。
It is worth mentioning that in some edge cases, the extra storage space used by the uniquifier can reduce the number of rows that can fit onto the data page. Our example demonstrates such a condition. As you can see, dbo.UniqueCI uses about 15 percent fewer data pages than the other two tables.
值得一提的是,在某些边缘情况下,uniquifier使用的额外存储空间可以减少数据页上可以容纳的行数。我们的示例演示了这种情况。如你所见,dbo。与其他两个表相比,UniqueCI使用的数据页少了大约15%。
Now, let’s see how the uniquifier affects nonclustered indexes. The code shown in Listing 7-3 creates nonclustered indexes in all three tables. Figure 7-2 shows the physical statistics for those indexes.
现在,让我们看看uniquifier如何影响非集群索引。清单7-3所示的代码在所有三个表中创建了非集群索引。图7-2显示了这些索引的物理统计信息。
Listing 7-3. Nonunique clustered index : Checking nonclustered indexes’ row size
清单7。非唯一聚集索引:检查非聚集索引的行大小
create nonclustered index IDX_UniqueCI_ID
on dbo.UniqueCI(ID);
create nonclustered index IDX_NonUniqueCINoDups_ID
on dbo.NonUniqueCINoDups(ID);
create nonclustered index IDX_NonUniqueCIDups_ID
on dbo.NonUniqueCIDups(ID);
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.UniqueCI'), 2, null ,'DETAILED');
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.NonUniqueCINoDups'), 2, null ,'DETAILED');
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.NonUniqueCIDups'), 2, null ,'DETAILED');
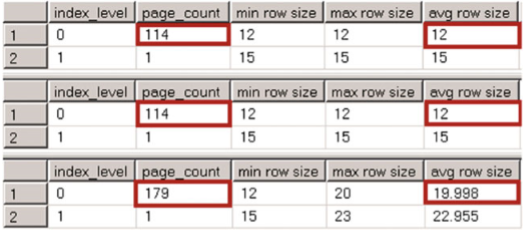
There is no overhead in the nonclustered index in the dbo.NonUniqueCINoDups table. As you will recall, SQL Server does not store offset information in a variable-length offset array for trailing columns storing NULL data. Nonetheless, the uniquifier introduces eight bytes of overhead in the dbo.NonUniqueCIDups table. Those eight bytes consist of a four-byte uniquifier value, a two-byte variable-length data offset array entry, and a two-byte entry storing the number of variable-length columns in the row.
dbo中的非集群索引没有开销。NonUniqueCINoDups表。正如您所记得的,SQL Server不会将偏移量信息存储在用于存储尾随列的可变长度偏移量数组中
空数据。尽管如此,uniquifier在dbo中引入了8字节的开销。NonUniqueCIDups表。这8个字节由一个4字节的uniquifier值、一个2字节的可变长度数据偏移数组条目和一个存储行中可变长度列数的2字节条目组成。
We can summarize the storage overhead of the uniquifier in the following way. For the rows that have a uniquifier as NULL , there is a two-byte overhead if the index has at least one variable-length column that stores a NOT NULL value. That overhead comes from the variable-length offset array entry for the uniquifier column. There is no overhead otherwise.
我们可以用以下方式总结统一器的存储开销。对于以uniquifier为NULL的行,如果索引中至少有一个存储非NULL值的变长列,则会有两个字节的开销。该开销来自uniquifier列的可变长度偏移数组条目。否则就没有开销了。
In cases where the uniquifier is populated, the overhead is six bytes if there are variable-length columns that store NOT NULL values. Otherwise, the overhead is eight bytes.
在填充uniquifier的情况下,如果存在存储非空值的变长列,则开销为6字节。否则,开销是8字节。
If you expect a large number of duplicates in the clustered index values, you can add an integer
identity column as the rightmost column to the index, thereby making it unique. This adds a four-byte predictable storage overhead to every row as compared to an unpredictable up to eight-byte storage overhead introduced by uniquifiers. This can also improve the performance of individual lookup operations when you reference the row by all of its clustered index columns.
如果期望集群索引值中有大量重复,可以添加整数
标识列作为索引的最右列,从而使其惟一。这为每一行增加了4字节的可预测存储开销,而uniquifier引入了最多8字节的不可预测存储开销。当您通过该行的所有聚集索引列引用该行时,这还可以提高单个查找操作的性能。
It is beneficial to design clustered indexes in a way that minimizes index fragmentation caused by inserting new rows. One of the methods to accomplish this is by making clustered index values ever increasing . The index on the identity column is one such example. Another example is a datetime column populated with the current system time at the moment of insertion.
以最小化插入新行导致的索引碎片的方式设计聚集索引是有益的。实现这一点的方法之一是使聚集索引值不断增加。标识列上的索引就是这样一个例子。另一个例子是datetime列,其中填充了插入时的当前系统时间。
There are two potential issues with ever-increasing indexes, however. The first relates to statistics. As you learned in Chapter 3 , the legacy cardinality estimator in SQL Server underestimates cardinality when parameter values are not present in the histogram. You should factor such behavior into your statistics maintenance strategy for the system, unless you are using the new SQL Server 2014-2016 cardinality estimators, which assume that data outside of the histogram has distributions similar to those of other data in the table.
然而,索引不断增长存在两个潜在问题。第一个与统计有关。正如您在第3章中了解到的,当直方图中没有参数值时,SQL Server中的遗留基数估计器会低估基数。您应该将这种行为考虑到系统的统计维护策略中,除非您使用新的SQL Server 2014-2016基数估计器,该估计器假定直方图之外的数据具有与表中其他数据相似的分布。
The next problem is more complicated. With ever-increasing indexes, the data is always inserted at the end of the index. On the one hand, it prevents page splits and reduces fragmentation. On the other hand, it can lead to hot spots , which are serialization delays that occur when multiple sessions are trying to modify the same data page and/or allocate new pages or extents. SQL Server does not allow multiple sessions to update the same data structures, and instead serializes those operations.
下一个问题更复杂。随着索引的增加,数据总是插入索引的末尾。一方面,它可以防止页面分裂,减少碎片。另一方面,它可能导致热点,即当多个会话试图修改相同的数据页和/或分配新的页或区段时发生的序列化延迟。SQL Server不允许多个会话更新相同的数据结构,而是序列化这些操作。
Hot spots are usually not an issue unless a system collects data at a very high rate and the index handles hundreds of inserts per second. We will discuss how to detect such an issue in Chapter 27 , “System Troubleshooting.”
热点通常不是问题,除非系统以非常高的速率收集数据,并且索引每秒处理数百次插入。我们将在第27章“系统故障排除”中讨论如何检测此类问题。
Finally, if a system has a set of frequently executed and important queries, it might be beneficial to consider a clustered index, which optimizes them. This eliminates expensive key lookup operations and improves the performance of the system.
最后,如果系统有一组频繁执行的重要查询,那么考虑集群索引可能是有益的,它可以优化这些查询。这消除了昂贵的键查找操作,并提高了系统的性能。
Even though such queries can be optimized by using covering nonclustered indexes, it is not always the ideal solution. In some cases, it requires you to create very wide nonclustered indexes, which will use up a lot of storage space both on disk and in the buffer pool.
尽管可以通过使用覆盖非集群索引来优化此类查询,但它并不总是理想的解决方案。在某些情况下,需要创建非常宽的非集群索引,这将占用磁盘和缓冲池中的大量存储空间。
Another important factor is how often columns are modified. Adding frequently modified columns to nonclustered indexes requires SQL Server to change data in multiple places, which negatively affects the update performance of the system and increases blocking.
另一个重要因素是修改列的频率。将经常修改的列添加到非集群索引需要SQL Server在多个位置更改数据,这会对系统的更新性能产生负面影响,并增加阻塞。
With all that being said, it is not always possible to design clustered indexes that will satisfy all of these guidelines. Moreover, you should not consider these guidelines to be absolute requirements. You should analyze the system, business requirements, workload, and queries and choose clustered indexes that would benefit you, even if they violate some of those guidelines.
尽管如此,设计满足所有这些指导原则的聚集索引并不总是可能的。此外,您不应该认为这些指导方针是绝对的需求。您应该分析系统、业务需求、工作负载和查询,并选择对您有利的集群索引,即使它们违反了某些指导原则。
Identities, Sequences, and Uniqueidentifiers
身份、序列和独特标识符
People often choose identities, sequences, and uniqueidentifiers as clustered index keys. As always, that approach has its own set of pros and cons. Clustered indexes defined on such columns are unique , static, and narrow . Moreover, identities and sequences are ever increasing, which reduces index fragmentation. One of the ideal use cases for them is catalog entity tables. You can think about tables, which store lists of customers, articles, or devices, as an example. Those tables store thousands, or maybe even a few million, rows, although the data is relatively static, and, as a result, hot spots are not an issue. Moreover, such tables are usually referenced by foreign keys and used in joins. Indexes on integer or bigint columns are very compact and efficient, which will improve the performance of queries.
人们通常选择标识符、序列和惟一标识符作为集群索引键。与往常一样,这种方法有它自己的优缺点。在这些列上定义的聚集索引是惟一的、静态的和窄的。此外,恒等式和序列不断增加,这减少了索引碎片。它们的理想用例之一是编目实体表。例如,您可以考虑表格,其中存储了客户、文章或设备的列表。这些表存储了数千甚至数百万行,尽管数据相对静态,因此热点不是问题。而且,这些表通常由外键引用,并在连接中使用。integer或bigint列上的索引非常紧凑和高效,这将提高查询的性能。
We will discuss foreign key constraints in greater detail in Chapter 8 , “Constraints.” 我们将在第8章“约束”中更详细地讨论外键约束。
Clustered indexes on identity or sequence columns are less efficient in the case of transactional tables, which collect large amounts of data at a very high rate, due to the potential hot spots they introduce. Uniqueidentifiers, on the other hand, are rarely a good choice for indexes, both clustered and nonclustered. Random values generated with the NEWID() function greatly increase index fragmentation. Moreover, indexes on uniqueidentifiers decrease the performance of batch operations. Let’s look at an example and create two tables: one with clustered indexes on identity columns and one with clustered indexes on uniqueidentifier columns. In the next step, we will insert 65,536 rows into both tables. You can see the code for doing this in Listing 7-4 .
在事务性表中,身份或序列列上的聚集索引效率较低,事务性表以非常高的速率收集大量数据,这是由于它们引入的潜在热点造成的。另一方面,对于聚集索引和非聚集索引,uniqueidentifier很少是一个好的选择。使用NEWID()函数生成的随机值极大地增加了索引碎片。此外,惟一标识符上的索引会降低批处理操作的性能。让我们看一个示例并创建两个表:一个表在标识列上具有集群索引,另一个表在uniqueidentifier列上具有集群索引。下一步,我们将在两个表中插入65,536行。您可以在清单7-4中看到执行此操作的代码。
Listing 7-4. Uniqueidentifiers: Table creat
create table dbo.IdentityCI
(
ID int not null identity(1,1),
Val int not null,
Placeholder char(100) null
);
create unique clustered index IDX_IdentityCI_ID
on dbo.IdentityCI(ID);
create table dbo.UniqueidentifierCI
(
ID uniqueidentifier not null
constraint DEF_UniqueidentifierCI_ID
default newid(),
Val int not null,
Placeholder char(100) null,
);
create unique clustered index IDX_UniqueidentifierCI_ID
on dbo.UniqueidentifierCI(ID)
go
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.IdentityCI(Val)
select ID from IDs;
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.UniqueidentifierCI(Val)
select ID from IDs;
The execution time on my computer and number of reads are shown in Table 7-1 . Figure 7-3 shows execution plans for both queries.
F igure 7-3. Inserting data into the tables: Execution plans
我的计算机上的执行时间和读取次数如表7-1所示。图7-3显示了这两个查询的执行计划。
图7-3将数据插入表:执行计划

Table 7-1. Inserting Data into the Tables: Execution Statistics
表7 - 1。将数据插入表中:执行统计信息
As you can see, there is another sort operator in the case of the index on the uniqueidentifier column. SQL Server sorts randomly generated uniqueidentifier values before the insert, which decreases the performance of the query. Let’s insert another batch of rows into the table and check index fragmentation. The code for doing this is shown in Listing 7-5 . Figure 7-4 shows the results of the queries.
Listing 7-5. Uniqueidentifiers : Inserting rows and checking fragmentation
如您所见,在uniqueidentifier列上的索引的情况下,还有另一个排序操作符。SQL Server在插入之前对随机生成的uniqueidentifier值进行排序,这会降低查询的性能。让我们向表中插入另一批行并检查索引碎片。执行此操作的代码如清单7-5所示。图7-4显示了查询的结果。
清单7 - 5。惟一标识符:插入行并检查碎片
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.IdentityCI(Val)
select ID from IDs;
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.UniqueidentifierCI(Val)
select ID from IDs;
select page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.IdentityCI'),1,null,'DETAILED');
select page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.UniqueidentifierCI'),1,null ,'DETAILED');
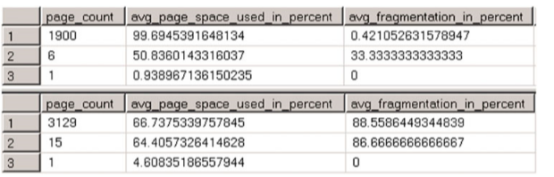
As you can see, the index on the uniqueidentifier column is heavily fragmented, and it uses about 40 percent more data pages as compared to the index on the identity column. A batch insert into the index on the uniqueidentifier column inserts data at different places in the data file, which leads to heavy, random physical I/O in the case of large tables. This can significantly decrease the performance of the operation.
正如您所看到的,uniqueidentifier列上的索引非常分散,与identity列上的索引相比,它使用的数据页多了大约40%。在uniqueidentifier列上的索引中进行批量插入,会在数据文件的不同位置插入数据,对于大型表,这会导致大量随机物理I/O。这样会大大降低手术的效果。
PERSONAL EXPERIENCE
个人经验
Some time ago, I had been involved in the optimization of a system that had a 250 GB table with one clustered and three nonclustered indexes. One of the nonclustered indexes was the index on the uniqueidentifier column. By removing this index, we were able to speed up a batch insert of 50,000 rows from 45 seconds down to 7 seconds.
不久前,我参与了一个系统的优化,该系统有一个250gb的表,其中有一个集群索引和三个非集群索引。其中一个非集群索引是uniqueidentifier列上的索引。通过删除这个索引,我们能够将50,000行的批插入从45秒提高到7秒。
There are two common use cases for when you would want to create indexes on uniqueidentifier columns. The first one is for supporting the uniqueness of values across multiple databases. Think about a distributed system where rows can be inserted into every database. Developers often use uniqueidentifiers to make sure that every key value is unique system wide.
当您希望在uniqueidentifier列上创建索引时,有两个常见的用例。第一个是支持跨多个数据库的值的唯一性。考虑一个分布式系统,其中行可以插入到每个数据库中。开发人员经常使用uniqueidentifier来确保每个键值在系统范围内是唯一的。
The key element in such an implementation is how key values were generated. As you have already seen, the random values generated with the NEWID() function or in the client code negatively affect system performance. However, you can use the NEWSEQUENTIALID() function, which generates unique and generally ever-increasing values (SQL Server resets their base value from time to time). Indexes on uniqueidentifier columns generated with the NEWSEQUENTIALID() function are similar to indexes on identity and sequence columns; however, you should remember that the uniqueiden tifier data type uses 16 bytes of storage space, compared to the 4-byte int or 8-byte bigint data types.
这种实现中的关键元素是如何生成键值。正如您已经看到的,NEWID()函数或客户机代码中生成的随机值会对系统性能产生负面影响。但是,您可以使用NEWSEQUENTIALID()函数,该函数生成惟一且通常不断增长的值(SQL Server不时重置它们的基值)。使用NEWSEQUENTIALID()函数生成的uniqueidentifier列上的索引类似于标识列和序列列上的索引;但是,您应该记住,与4字节的int或8字节的bigint数据类型相比,uniqueidentifier数据类型使用16字节的存储空间。
As an alternative solution, you may consider creating a composite index with two columns
(InstallationId, Unique_Id_Within_Installation). The combination of these two columns guarantees uniqueness across multiple installations and databases and uses less storage space than uniqueidentifiers do. You can use an integer identity or sequence to generate the Unique_Id_Within_Installation value, which will reduce the fragmentation of the index.
作为一种替代解决方案,您可以考虑创建一个包含两列的复合索引
(InstallationId Unique_Id_Within_Installation)。这两列的组合保证了跨多个安装和数据库的唯一性,并且比惟一标识符使用更少的存储空间。您可以使用整数标识或序列来生成Unique_Id_Within_Installation值,这将减少索引的碎片。
In cases where you need to generate unique key values across all entities in the database, you can consider using a single sequence object across all entities. This approach fulfils the requirement but uses a smaller data type than uniqueidentifiers
在需要跨数据库中所有实体生成惟一键值的情况下,可以考虑跨所有实体使用单个sequence对象。这种方法满足了需求,但是使用了比惟一标识符更小的数据类型
Another common use case is security, where a uniqueidentifier value is used as a security token or a random object ID. Unfortunately, you cannot use the NEWSEQUENTIALID() function in this scenario, because it is possible to guess the next value returned by that function.
另一个常见的用例是安全性,惟一标识符值用作安全令牌或随机对象ID。不幸的是,在此场景中不能使用NEWSEQUENTIALID()函数,因为可以猜测该函数返回的下一个值。
One possible improvement in this scenario is creating a calculated column using the CHECKSUM() function, indexing it afterward without creating the index on the uniqueidentifier column. The code is shown in Listing 7-6 .
在这个场景中,一个可能的改进是使用CHECKSUM()函数创建一个计算列,然后索引它,而不需要在uniqueidentifier列上创建索引。代码如清单7-6所示。
create table dbo.Articles
(
ArticleId int not null identity(1,1),
ExternalId uniqueidentifier not null
constraint DEF_Articles_ExternalId
default newid(),
ExternalIdCheckSum as checksum(ExternalId),
/* Other Columns */
);
create unique clustered index IDX_Articles_ArticleId
on dbo.Articles(ArticleId);
create nonclustered index IDX_Articles_ExternalIdCheckSum
on dbo.Articles(ExternalIdCheckSum);
You can index a calculated column without persisting it.
Even though the IDX_Articles_ExternalIdCheckSum index is going to be heavily fragmented, it will be more compact as compared to the index on the uniqueidentifier column (a 4-byte key versus 16 bytes). It also improves the performance of batch operations because of faster sorting, which also requires less memory to proceed.
可以索引计算出的列,而无需持久化它。
尽管IDX_Articles_ExternalIdCheckSum索引将非常分散,但与惟一标识符列上的索引(4字节键与16字节键)相比,它将更加紧凑。它还提高了批处理操作的性能,因为排序速度更快,而且需要更少的内存。
One thing that you must keep in mind is that the result of the CHECKSUM() function is not guaranteed to be unique. You should include both predicates to the queries, as shown in Listing 7-7 .
您必须记住的一件事是,CHECKSUM()函数的结果不一定是惟一的。应该将这两个谓词包含到查询中,如清单7-7所示。
select ArticleId /* Other Columns */
from dbo.Articles
where checksum(@ExternalId) = ExternalIdCheckSum and ExternalId = @ExternalId
You can use the same technique in cases where you need to index string columns larger than 900/1,700 bytes, which is the maximum size of a nonclustered index key. Even though such an index would not support range scan operations, it could be used for point lookups .
如果需要索引大于900/ 1700字节的字符串列(这是非集群索引键的最大大小),可以使用相同的技术。即使这样的索引不支持范围扫描操作,它也可以用于点查找。