一、Mapper XML 文件
Mapper映射文件是在实际开发过程中使用最多的,也是我们学习的重点。
Mapper文件中包含的元素有:
- cache – 配置给定命名空间的缓存。
- cache-ref – 从其他命名空间引用缓存配置。
- resultMap – 映射复杂的结果对象。
- sql – 可以重用的 SQL 块,也可以被其他语句引用。
- insert – 映射插入语句
- update – 映射更新语句
- delete – 映射删除语句
- select – 映射查询语句
二、CRUD操作
①select

select标签叫Statement
id,必要属性,在当前的命名空间下不能重复,指的就是在dao层接口中的方法
指定输出类型,resultType,值的就是返回的类型
parameterType (不是必须)如果不指定,自动识别,指的就是传入的参数
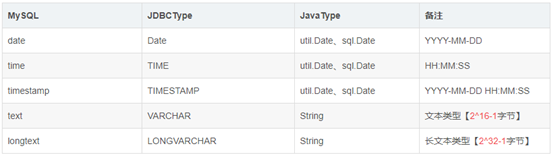
别名问题:


数据库字段类型--->程序中属性类型对应关系

②insert

③如何获得到自增id

useGeneratedKeys:开启自增长映射
keyProperty:指定id所对应对象中的属性名
当执行完saveUser()方法后,其返回值依然是执行sql影响的行数,并不是要获取的自增ID!Mybatis会自动将返回的主键值赋值给对象User的属性id,因此可以通过属性的get方法获得插入的主键值: System.out.println(User.getId());
另外一种写法:
在插入操作完成之前或之后,可以配置<selectKey>标签获得生成的主键的值,获得插入之前还是之后的值,可以通过配置order属性来指定。
LAST_INSERT_ID:该函数是mysql的函数,获取自增主键的ID,它必须配合insert语句一起使用
<!-- 增删改返回的都是int值 不用写返回值 -->
<insert id="addUser" parameterType="User">
<selectKey keyProperty="id" resultType="int" order="AFTER">
SELECT LAST_INSERT_ID()
</selectKey>
INSERT INTO USER VALUES (null,#{name},#{time},#{address})
</insert>
这里因为使用的MySql数据库,所以配置的order是after,如果使用的是Oracle数据库,就该配置成before,这是因为MySql和Oracle生成主键不一样的原因
④update

⑤delete

⑥#和$区别(面试题)
在映射文件配置<select>标签执行查询操作。
注意:
- {}:相当于占位符
{id}:其中的id可以表示输入参数的名称,如果是简单类型名称可以任意
- ${}:表示拼接sql语句
- ${value}:表示输入参数的名称,如果参数是简单类型,参数名称必须是value
<!--
根据id查询用户,User findById(int id)
select:配置查询语句
id:可以通过id找到执行的statement,statement唯一标识
parameterType:输入参数类型
resultType:输出结果类型
#{}:相当于占位符
#{id}:其中的id可以表示输入参数的名称,如果是简单类型名称可以任意
-->
<select id="getById" parameterType="int" resultType="User" >
select * from user where id=#{id}
</select>
<!--
根据用户名称来模糊查询用户信息列表;
${}:表示拼接sql语句
${value}:表示输入参数的名称,如果参数是简单类型,参数名称必须是value
-->
<select id="findByUsername" parameterType="java.lang.String"
resultType="User">
select * from user where username like '%${value}%'
</select>
在Mybatis的mapper中,参数传递有2种方式,一种是#{}另一种是${},两者有着很大的区别:
#{} 实现的是sql语句的预处理参数,之后执行sql中用?号代替,使用时不需要关注数据类型,Mybatis自动实现数据类型的转换。并且可以防止SQL注入。 preparestament
${} 实现是sql语句的直接拼接,不做数据类型转换,需要自行判断数据类型。不能防止SQL注入。
总结:
#{} 占位符,用于参数传递。?占位
${}用于SQL拼接。 直接拼接在SQL语句中 有注入问题!如果是字符串 value
比如模糊查询


三、parameterType的传入参数
传入类型有三种:
1、简单类型,string、long、integer等
2、Pojo类型,User等
3、HashMap类型。
①传入类型是HashMap类型
查询需求:
<select id="getUsers" parameterType="map" resultType="User">
select * from user where birthday between #{startdate} and #{enddate}
</select>
查询测试:
@Test
public void test7(){
HashMap<String, Object> map=new HashMap<String, Object>();
map.put("startdate", "2018-09-07");
map.put("enddate", "2018-09-25");
List<User> users = mapper.getUsers(map);
for (User user : users) {
System.out.println(user);
}
}
注意:map的key要和sql中的占位符保持名字一致
②分页查询
查询需求:
<!-- 分页:map传参 -->
<select id="selectAuthorByPage" resultType="User">
SELECT * FROM USER LIMIT #{offset}, #{pagesize}
</select>
接口:
List<User> selectAuthorByPage(Map<String, Object> paramList);测试:
@Test
public void testSelectAuthorByPage() {
Map<String, Object> map = new HashMap<String, Object>();
map.put("offset", 0);
map.put("pagesize", 2);
List<User> authorList = mapper.selectAuthorByPage(map);
for (int i = 0; i < authorList.size(); i++) {
System.out.println(authorList.get(i));
}
}
分页查询使用注解传入:
mapper文件中的参数占位符的名字一定要和接口中参数的注解保持一致
<!-- 分页:map传参 -->
<select id="selectUserByPage2" resultType="User">
SELECT * FROM USER LIMIT #{offset}, #{pagesize}
</select>
接口:
List<User> selectUserByPage2(@Param(value = "offset") int offset, @Param(value = "pagesize") int pagesize);
测试:
@Test
public void testSelectAuthorByPage2() {
List<User> authorList = mapper.selectUserByPage2(0, 2);
for (int i = 0; i < authorList.size(); i++) {
System.out.println(authorList.get(i));
System.out.println("----------------------");
}
}
分页查询使用参数顺序:
<!-- 分页:传参顺序 -->
<select id="selectUserByPage3" parameterType="map" resultType="User">
SELECT * FROM USER LIMIT #{param1},#{param2}
</select>
接口:
List<User> selectUserByPage3(int offset, int pagesize);测试:
@Test
public void testSelectAuthorByPage3() {
List<User> users = mapper.selectUserByPage3(1, 1);
for (int i = 0; i < users.size(); i++) {
System.out.println(users.get(i));
System.out.println("----------------------");
}
}
四、返回Map类型查询结果
Mybatis中查询结果集为Map的功能,只需要重写ResultHandler接口,,然后用SqlSession 的select方法,将xml里面的映射文件的返回值配置成 HashMap 就可以了。具体过程如下
xml配置
<resultMap id="resultMap1" type="HashMap">
<result property="AA" column="r1" />
<result property="BB" column="r2" />
</resultMap>
<select id="getResult" resultMap="resultMap1">
select count(*) r1, max(birthday) r2 from user
</select>
接口:
public HashMap<String, Object> getResult();测试:
@Test
public void test8(){
HashMap<String, Object> result = mapper.getResult();
System.out.println(result);
}
返回多个值:
<select id="getResult" resultType="map">
select count(*) r1, max(birthday) r2,min(id) r3 from user
</select>
五、解决数据库字段和实体类属性不同
在平时的开发中,我们表中的字段名和表对应实体类的属性名称不一定都是完全相同的,下面来演示一下这种情况下的如何解决字段名与实体类属性名不相同的冲突。
上面的测试代码演示当实体类中的属性名和表中的字段名不一致时,使用MyBatis进行查询操作时无法查询出相应的结果的问题以及针对问题采用的两种办法:
解决办法一: 通过在查询的sql语句中定义字段名的别名,让字段名的别名和实体类的属性名一致,这样就可以表的字段名和实体类的属性名一一对应上了,这种方式是通过在sql语句中定义别名来解决字段名和属性名的映射关系的。

解决办法二: 通过<resultMap>来映射字段名和实体类属性名的一一对应关系。这种方式是使用MyBatis提供的解决方式来解决字段名和属性名的映射关系的。


六、MyBatis整体架构
Mybatis是一个类似于Hibernate的ORM持久化框架,支持普通SQL查询,存储过程以及高级映射。Mybatis通过使用简单的XML或注解用于配置和原始映射,将接口和POJO对象映射成数据库中的记录。
由于Mybatis是直接基于JDBC做了简单的映射包装,所以从性能角度来看:
JDBC > Mybatis > Hibernate

1、配置2类配置文件,其中一类是:Mybatis-Config.xml (名字不是写死,随便定义),另一类:Mapper.xml(多个),定义了sql片段;
2、通过配置文件得到SqlSessionFactory
3、通过SqlSessionFactory得到SqlSession(操作数据库)
4、通过底层的Executor(执行器)执行sql,Mybatis提供了2种实现,一种是基本实现,另一种带有缓存功能的实现;