auto.offset.reset: 可理解为kafka consumer读取数据的策略,本地用的kafka版本为0.10,因此该参数可填earliest|latest|none。
earliest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
latest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
none: topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
测试前提: 我们主要做的是Flink的Streaming sql,在创建kafka source的时候封装了该参数,查看是否消费数据,我们借助了jmeter和Flink web ui上的metrics等工具。
测试过程:
earliest模式: kafka source的名称为a1
1.在a1中,topic为test1,groupId为0001,0001从未被消费过,数据(24条)提前发送,再启动sql1(select * from a1 ),会从头开始消费,显示24条数据
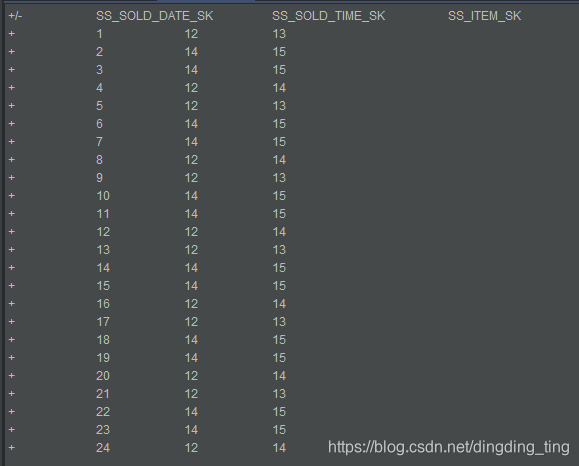
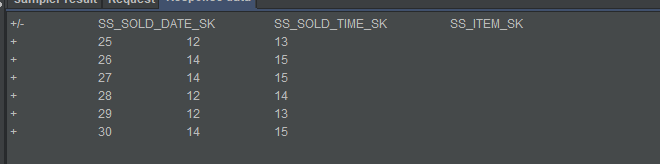
2.停掉1中所提到的sql1,发送不同的6条数据到kafka中,不更换a1的groupId,再启动sql1(select * from a1 ),会接着上次消费的位置开始往后消费,显示6条数据
latest模式:kafka source的名称为a2
1.在a2中,topic为b,groupId为0002,0002未被消费,数据提前发送,再启动sql2(select * from a2),在jmeter上未看到结果,在flink中查看相关metrics,无数据读入;在不杀掉sql2的前提下,发送一批(8条)数据,只消费后发送的8条数据。
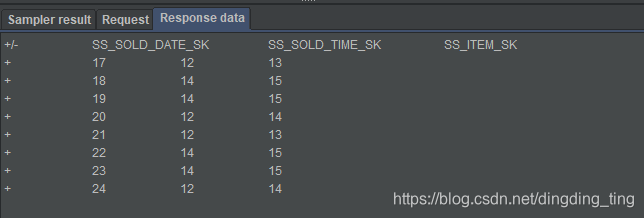
2.停掉1中的sql2,不更换a2中的groupId,发送7条数据到b中,启动sql2,只显示后发送的7条数据
none模式: kafka source的名称为a3
1.在a3中,topic为c,设置groupId为0001(未被消费过),数据提前发送,再启动sql3(select * from a3),sql执行失败,在日志中报错:

2.在a3中,topic为c,设置groupId为0002(被消费过),启动sql3(select * from a3),发送8条数据到c中,jmeter中显示8条数据