基于Redis5.0
在字典中, 一个键(key)可以和一个值(value)进行关联(或者说将键映射为值), 这些关联的键和值就被称为键值对
字典中的每个键都是独一无二的, 程序可以在字典中根据键查找与之关联的值, 或者通过键来更新值, 又或者根据键来删除整个键值对, 等等
字典的实现
Redis 的字典使用哈希表作为底层实现, 一个哈希表里面可以有多个哈希表节点, 而每个哈希表节点就保存了字典中的一个键值对
哈希表
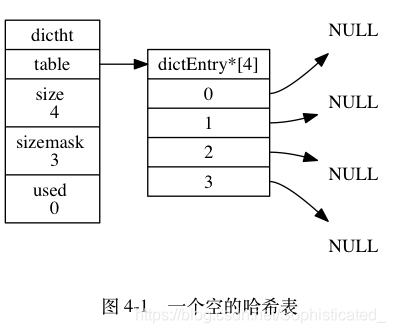
Redis 字典所使用的哈希表由 dict.h/dictht 结构定义:
//dict.h Hash Tables Implementation.
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
-
table属性是一个数组, 数组中的每个元素都是一个指向 dict.h/dictEntry 结构的指针, 每个 dictEntry 结构保存着一个键值对 -
size属性记录了哈希表的大小, 也即是 table 数组的大小 -
sizemask属性的值总是等于 size - 1 , 这个属性和哈希值一起决定一个键应该被放到 table 数组的哪个索引上面。 -
used属性则记录了哈希表目前已有节点(键值对)的数量
哈希表节点
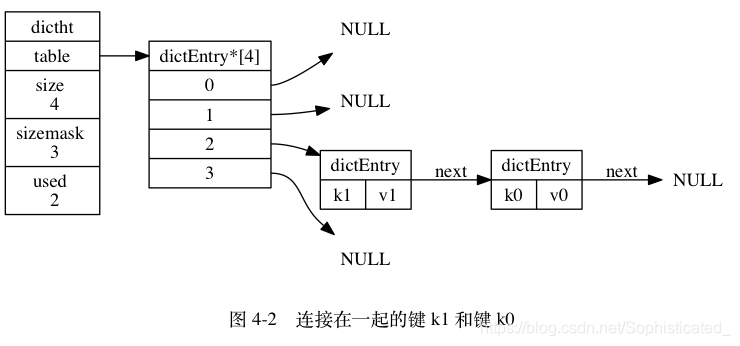
哈希表节点使用 dictEntry 结构表示, 每个 dictEntry 结构都保存着一个键值对:
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
key属性保存着键值对中的键v属性则保存着键值对中的值, 其中键值对的值可以是一个指针, 或者是一个 uint64_t 整数, 又或者是一个 int64_t 整数,或者是double类型的浮点数next属性是指向另一个哈希表节点的指针, 这个指针可以将多个哈希值相同的键值对连接在一次, 以此来解决键冲突(collision)的问题
字典
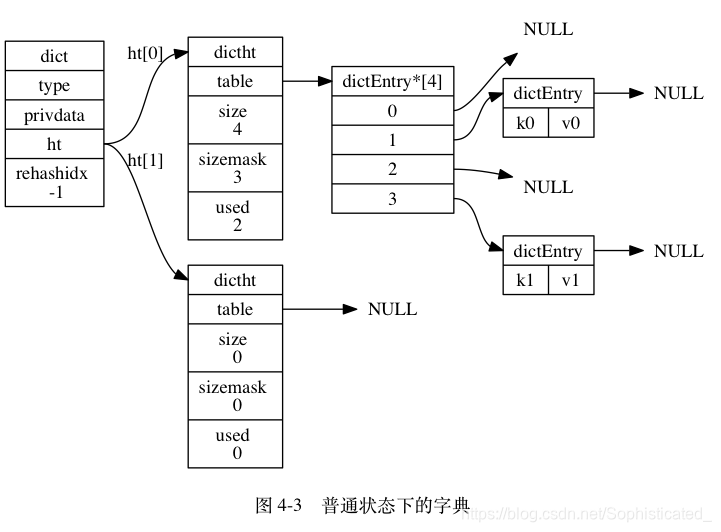
Redis 中的字典由 dict.h/dict 结构表示:
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
//字典所持有的迭代器,只有是安全迭代器时才会增加此字段
unsigned long iterators; /* number of iterators currently running */
} dict;
type 属性和 privdata 属性是针对不同类型的键值对, 为创建多态字典而设置的:
type属性是一个指向dictType结构的指针, 每个dictType结构保存了一簇用于操作特定类型键值对的函数, Redis 会为用途不同的字典设置不同的类型特定函数。privdata属性则保存了需要传给那些类型特定函数的可选参数
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;
-
ht属性是一个包含两个项的数组, 数组中的每个项都是一个dictht哈希表, 一般情况下, 字典只使用ht[0]哈希表,ht[1]哈希表只会在对ht[0]哈希表进行 rehash 时使用 -
rehashidx: 它记录了 rehash 目前的进度, 如果目前没有在进行 rehash , 那么它的值为 -1 -
iterators:字典迭代器的数量,只有是安全迭代器时(dictIterator->safe = 1)才会增加此字段
迭代器
字典的迭代器由 dict.h/dictIterator 结构表示:
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
typedef struct dictIterator {
//指向迭代器处理的字典
dict *d;
//dictht中table数组的下标
long index;
//table是dict结构中dictht数组的下标,即标识ht[0]还是ht[1]。
//safe字段用于标识该迭代器是否为一个安全的迭代器
int table, safe;
//entry和nextEntry分别指向当前的元素和下一个元素
dictEntry *entry, *nextEntry;
//fingerprint是字典的指纹
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint;
} dictIterator;
safe字段用于标识该迭代器是否为一个安全的迭代器。如果是,则可以在迭代过程中使用dictDelete、dictFind等方法;如果不是,则只能使用dictNext遍历方法
迭代器提供了遍历字典中所有元素的方法,通过dicGetIterator()获得迭代器后,使用dictNext(dictIterator *)获得下一个元素。遍历的过程,先从ht[0]开始,依次从第一个桶table[0]开始遍历桶中的元素,然后遍历table[1],'*** ,table[size],若正在扩容,则会继续遍历ht[1]中的桶。遍历桶中元素时,依次访问链表中的每一个元素。
更方便的宏定义:
/* ------------------------------- Macros ------------------------------------*/
#define dictFreeVal(d, entry) \
if ((d)->type->valDestructor) \
(d)->type->valDestructor((d)->privdata, (entry)->v.val)
#define dictSetVal(d, entry, _val_) do { \
if ((d)->type->valDup) \
(entry)->v.val = (d)->type->valDup((d)->privdata, _val_); \
else \
(entry)->v.val = (_val_); \
} while(0)
#define dictSetSignedIntegerVal(entry, _val_) \
do { (entry)->v.s64 = _val_; } while(0)
#define dictSetUnsignedIntegerVal(entry, _val_) \
do { (entry)->v.u64 = _val_; } while(0)
#define dictSetDoubleVal(entry, _val_) \
do { (entry)->v.d = _val_; } while(0)
#define dictFreeKey(d, entry) \
if ((d)->type->keyDestructor) \
(d)->type->keyDestructor((d)->privdata, (entry)->key)
#define dictSetKey(d, entry, _key_) do { \
if ((d)->type->keyDup) \
(entry)->key = (d)->type->keyDup((d)->privdata, _key_); \
else \
(entry)->key = (_key_); \
} while(0)
#define dictCompareKeys(d, key1, key2) \
(((d)->type->keyCompare) ? \
(d)->type->keyCompare((d)->privdata, key1, key2) : \
(key1) == (key2))
#define dictHashKey(d, key) (d)->type->hashFunction(key)
#define dictGetKey(he) ((he)->key)
#define dictGetVal(he) ((he)->v.val)
#define dictGetSignedIntegerVal(he) ((he)->v.s64)
#define dictGetUnsignedIntegerVal(he) ((he)->v.u64)
#define dictGetDoubleVal(he) ((he)->v.d)
#define dictSlots(d) ((d)->ht[0].size+(d)->ht[1].size)
#define dictSize(d) ((d)->ht[0].used+(d)->ht[1].used)
#define dictIsRehashing(d) ((d)->rehashidx != -1)
哈希算法
当要将一个新的键值对添加到字典里面时, 程序需要先根据键值对的键计算出哈希值和索引值, 然后再根据索引值, 将包含新键值对的哈希表节点放到哈希表数组的指定索引上面
Redis 计算哈希值和索引值的方法如下:
// 使用字典设置的哈希函数,计算键 key 的哈希值
hash = dict->type->hashFunction(key);
// 使用哈希表的 sizemask 属性和哈希值,计算出索引值
// 根据情况不同, ht[x] 可以是 ht[0] 或者 ht[1]
index = hash & dict->ht[x].sizemask;
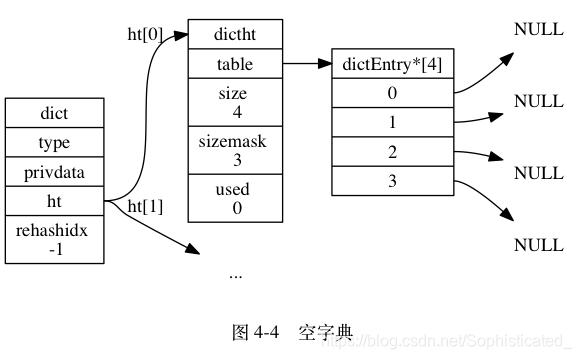
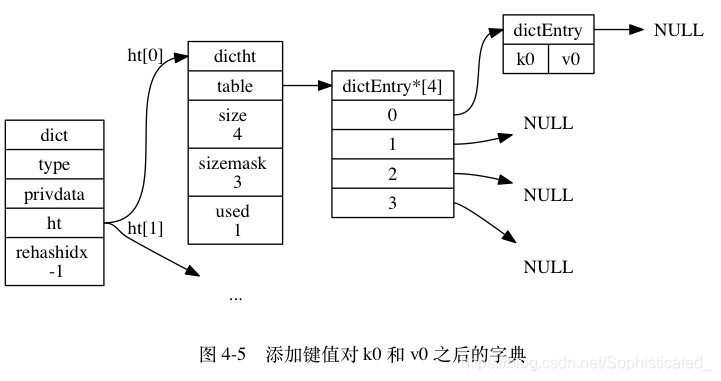
举个例子, 对于图 4-4 所示的字典来说, 如果我们要将一个键值对 k0 和 v0 添加到字典里面, 那么程序会先使用语句:
hash = dict->type->hashFunction(k0);
计算键 k0 的哈希值。
假设计算得出的哈希值为 8 , 那么程序会继续使用语句:
index = hash & dict->ht[0].sizemask = 8 & 3 = 0;
计算出键 k0 的索引值 0 , 这表示包含键值对 k0 和 v0 的节点应该被放置到哈希表数组的索引 0 位置上, 如图 4-5 所示。
当字典被用作数据库的底层实现, 或者哈希键的底层实现时, Redis 使用 SipHash算法来计算键的哈希值
/* -------------------------- hash functions -------------------------------- */
static uint8_t dict_hash_function_seed[16];
void dictSetHashFunctionSeed(uint8_t *seed) {
memcpy(dict_hash_function_seed,seed,sizeof(dict_hash_function_seed));
}
uint8_t *dictGetHashFunctionSeed(void) {
return dict_hash_function_seed;
}
/* The default hashing function uses SipHash implementation
* in siphash.c. */
uint64_t siphash(const uint8_t *in, const size_t inlen, const uint8_t *k);
uint64_t siphash_nocase(const uint8_t *in, const size_t inlen, const uint8_t *k);
uint64_t dictGenHashFunction(const void *key, int len) {
return siphash(key,len,dict_hash_function_seed);
}
uint64_t dictGenCaseHashFunction(const unsigned char *buf, int len) {
return siphash_nocase(buf,len,dict_hash_function_seed);
}
解决键冲突
当有两个或以上数量的键被分配到了哈希表数组的同一个索引上面时, 我们称这些键发生了冲突(collision)
Redis 的哈希表使用链地址法(separate chaining)来解决键冲突: 每个哈希表节点都有一个 next 指针, 多个哈希表节点可以用 next 指针构成一个单向链表, 被分配到同一个索引上的多个节点可以用这个单向链表连接起来, 这就解决了键冲突的问题
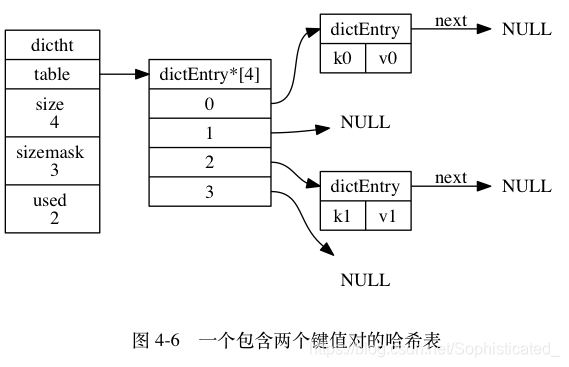
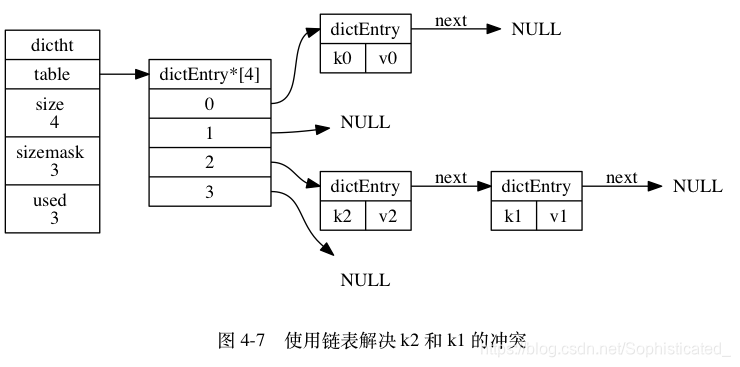
因为 dictEntry 节点组成的链表没有指向链表表尾的指针, 所以为了速度考虑, 程序总是将新节点添加到链表的表头位置(复杂度为 O(1)), 排在其他已有节点的前面
Rehash
随着操作的不断执行, 哈希表保存的键值对会逐渐地增多或者减少, 为了让哈希表的负载因子(load factor)维持在一个合理的范围之内, 当哈希表保存的键值对数量太多或者太少时, 程序需要对哈希表的大小进行相应的扩展或者收缩。
扩展和收缩哈希表的工作可以通过执行 rehash (重新散列)操作来完成, Redis 对字典的哈希表执行 rehash 的步骤如下:
- 为字典的
ht[1]哈希表分配空间, 这个哈希表的空间大小取决于要执行的操作, 以及ht[0]当前包含的键值对数量 (也即是ht[0].used属性的值):- 如果执行的是扩展操作, 那么
ht[1]的大小为第一个大于等于ht[0].used * 2的 2^n (2 的 n 次方幂); - 如果执行的是收缩操作, 那么
ht[1]的大小为第一个大于等于ht[0].used的 2^n 。
- 如果执行的是扩展操作, 那么
- 将保存在
ht[0]中的所有键值对 rehash 到ht[1]上面: rehash 指的是重新计算键的哈希值和索引值, 然后将键值对放置到ht[1]哈希表的指定位置上。 - 当
ht[0]包含的所有键值对都迁移到了ht[1]之后 (ht[0] 变为空表), 释放ht[0], 将ht[1]设置为ht[0], 并在ht[1]新创建一个空白哈希表, 为下一次 rehash 做准备,下面会对照代码解读
【注】:为什么哈希表的大小一定要是2的n次方呢?
- 减小哈希冲突概率:
如果len是2的N次方,那么len-1的后N位二进制一定是全1,不同hashcode的key计算出来的数组下标一定不同- 提高计算下标的效率:
如果len的二进制后n位非全1,与len-1相与时,0与1相与需要取反,如果len为2的N次方,那么与len-1相与,跟取余len等价,而与运算效率高于取余
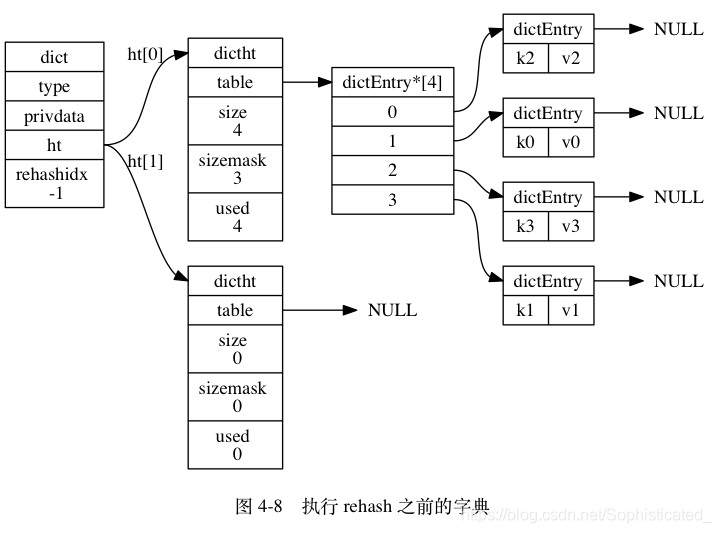
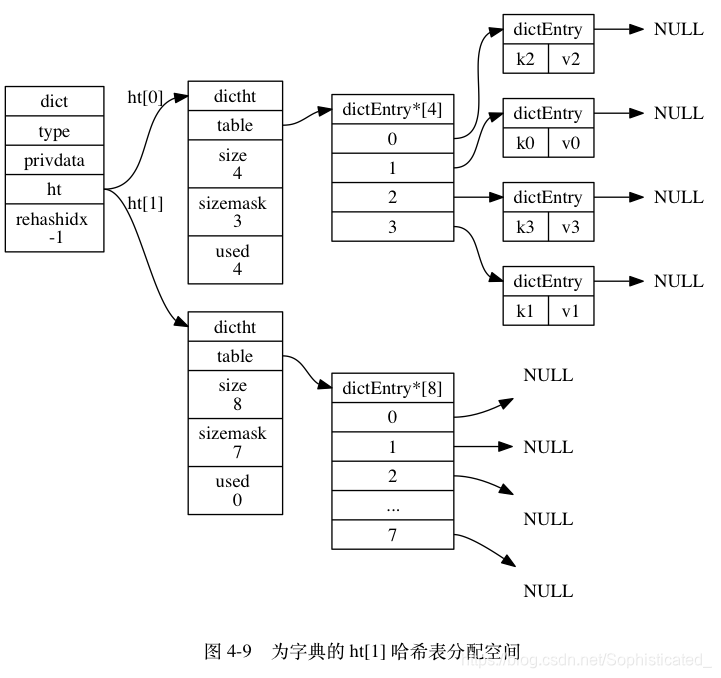
假设程序要对图 4-8 所示字典的 ht[0] 进行扩展操作, 那么程序将执行以下步骤:
ht[0].used当前的值为 4 , 4 * 2 = 8 , 而 8 (2^3)恰好是第一个大于等于 4 的 2 的 n 次方, 所以程序会将ht[1]哈希表的大小设置为 8 。 图 4-9 展示了ht[1]在分配空间之后, 字典的样子。- 将
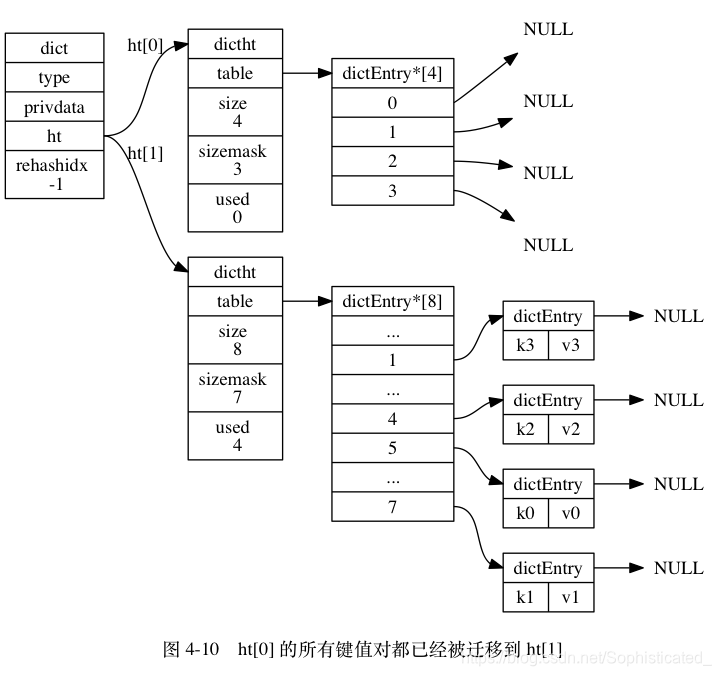
ht[0]包含的四个键值对都 rehash 到ht[1], 如图 4-10 所示。 - 释放
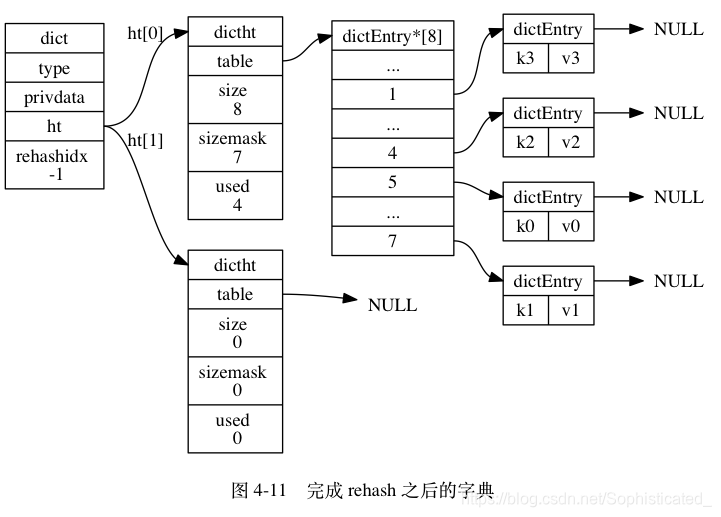
ht[0],并将ht[1]设置为ht[0],然后为ht[1]分配一个空白哈希表,如图 4-11 所示。
哈希表的扩展与收缩
当以下条件中的任意一个被满足时, 程序会自动开始对哈希表执行扩展操作:
- 服务器目前没有在执行
BGSAVE命令或者BGREWRITEAOF命令, 并且哈希表的负载因子大于等于1; - 服务器目前正在执行
BGSAVE命令或者BGREWRITEAOF命令, 并且哈希表的负载因子大于等于5;
其中哈希表的负载因子可以通过公式:
# 负载因子 = 哈希表已保存节点数量 / 哈希表大小
load_factor = ht[0].used / ht[0].size
根据 BGSAVE 命令或 BGREWRITEAOF 命令是否正在执行, 服务器执行扩展操作所需的负载因子并不相同, 这是因为在执行 BGSAVE 命令或 BGREWRITEAOF 命令的过程中, Redis 需要创建当前服务器进程的子进程, 而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率, 所以在子进程存在期间, 服务器会提高执行扩展操作所需的负载因子, 从而尽可能地避免在子进程存在期间进行哈希表扩展操作, 这可以避免不必要的内存写入操作, 最大限度地节约内存
另一方面, 当哈希表的负载因子小于 0.1 时, 程序自动开始对哈希表执行收缩操作
渐进式 Rehash
扩展或收缩哈希表需要将 ht[0] 里面的所有键值对 rehash 到 ht[1] 里面, 但是, 这个 rehash 动作并不是一次性、集中式地完成的, 而是分多次、渐进式地完成的
如果 ht[0] 里只保存着四个键值对, 那么服务器可以在瞬间就将这些键值对全部 rehash 到 ht[1] ; 但是, 如果哈希表里保存的键值对数量不是四个, 而是四百万、四千万甚至四亿个键值对, 那么要一次性将这些键值对全部 rehash 到 ht[1] 的话, 庞大的计算量可能会导致服务器在一段时间内停止服务
哈希表渐进式 rehash 的详细步骤:
- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。 - 在字典中维持一个索引计数器变量
rehashidx, 并将它的值设置为 0 , 表示 rehash 工作正式开始。 - 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将rehashidx属性的值增一。 - 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将rehashidx属性的值设为 -1 , 表示 rehash 操作已完成。
图 4-12 至图 4-17 展示了一次完整的渐进式 rehash 过程, 注意观察在整个 rehash 过程中, 字典的 rehashidx 属性是如何变化的
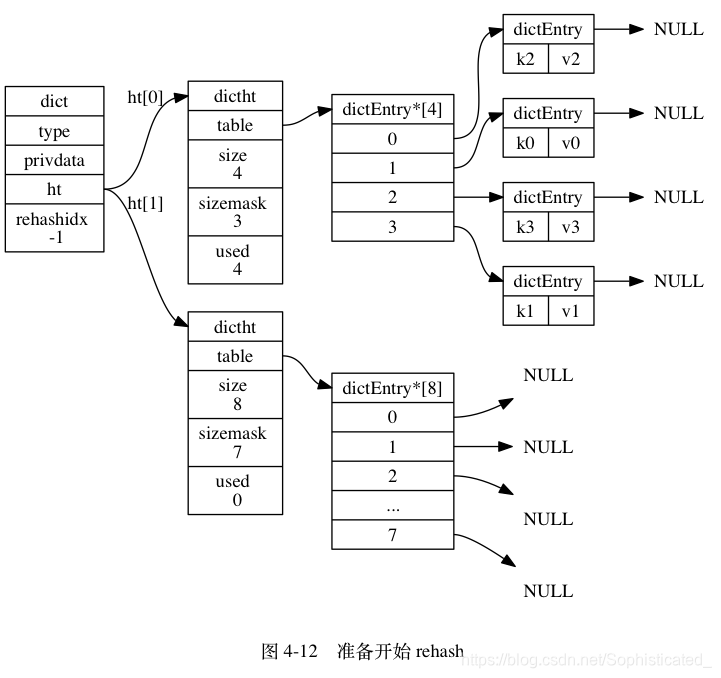
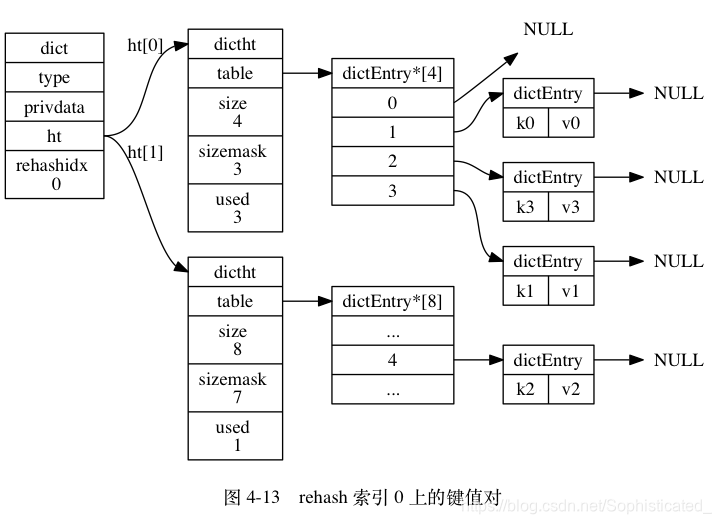
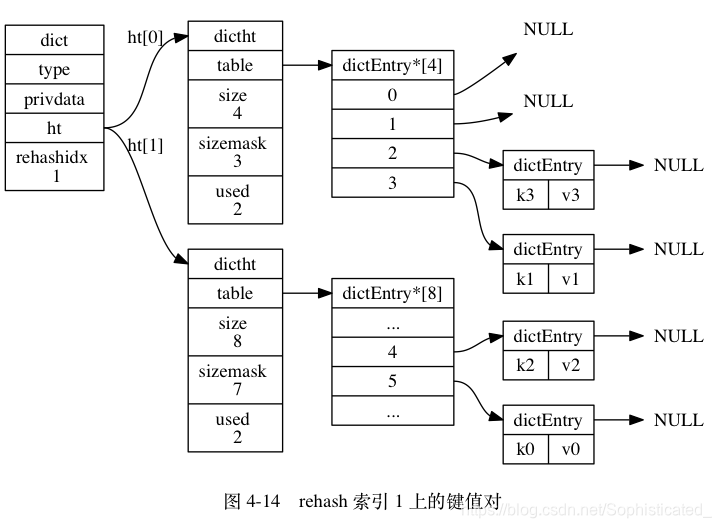
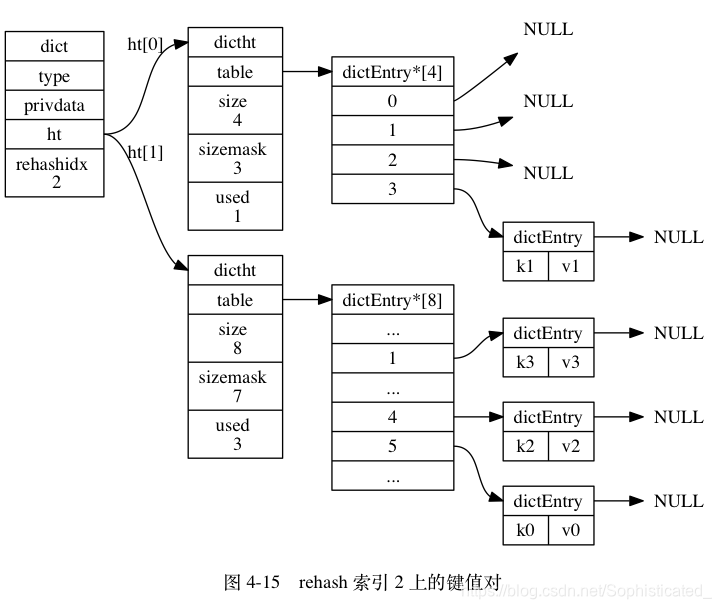
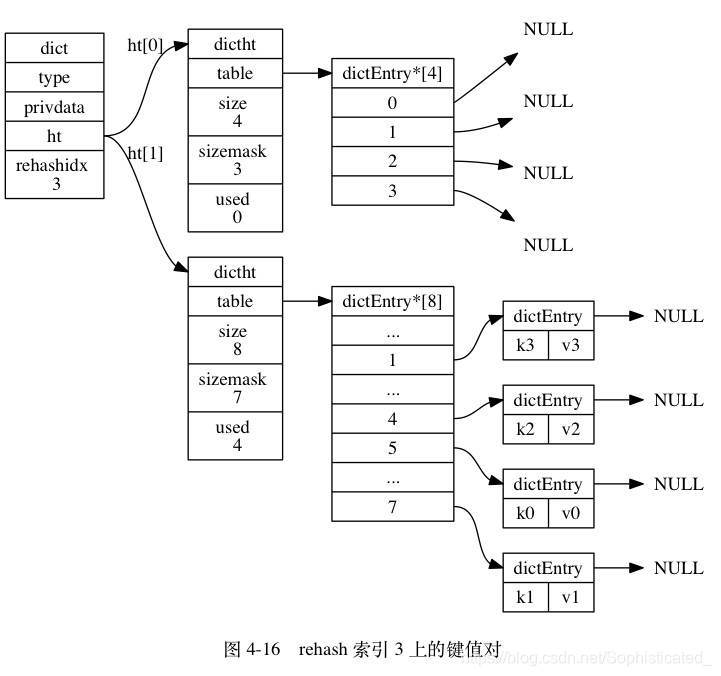
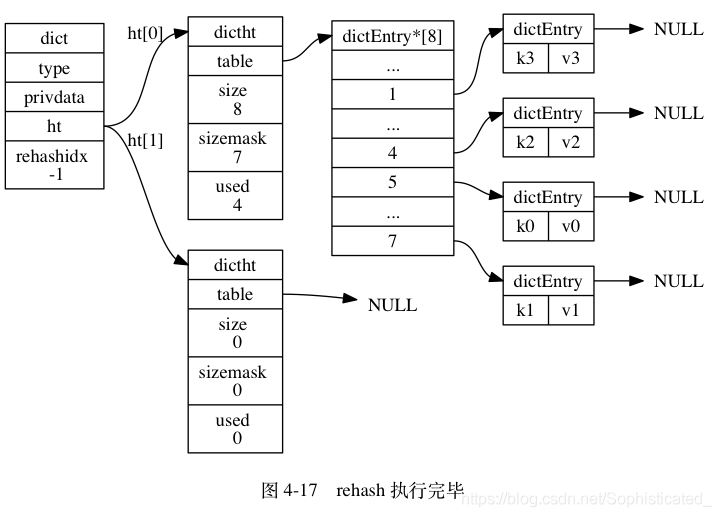
rehashidx即为table(hash表)的下标
因为在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0] 里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找
在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表
通过源码解读字典API
接下来将通过Redis5.0源码对上述操作进行解读
新建一个哈希表:
//dict.c
/* Reset a hash table already initialized with ht_init().
* NOTE: This function should only be called by ht_destroy(). */
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
/* Create a new hash table */
dict *dictCreate(dictType *type,
void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
/* Initialize the hash table */
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}
添加一个元素到哈希表:
/* Add an element to the target hash table */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
/* Low level add or find:
* This function adds the entry but instead of setting a value returns the
* dictEntry structure to the user, that will make sure to fill the value
* field as he wishes.
*
* This function is also directly exposed to the user API to be called
* mainly in order to store non-pointers inside the hash value, example:
*
* entry = dictAddRaw(dict,mykey,NULL);
* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
*
* Return values:
*
* If key already exists NULL is returned, and "*existing" is populated
* with the existing entry if existing is not NULL.
*
* If key was added, the hash entry is returned to be manipulated by the caller.
*/
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
//判断 dict 是否正在扩容,如果正在扩容则再尝试步长为1的扩容
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
从hash表删除一个元素:
/* Search and remove an element. This is an helper function for
* dictDelete() and dictUnlink(), please check the top comment
* of those functions. */
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
uint64_t h, idx;
dictEntry *he, *prevHe;
int table;
if (d->ht[0].used == 0 && d->ht[1].used == 0) return NULL;
//判断 dict 是否正在扩容,如果正在扩容则再尝试步长为1的扩容
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
prevHe = NULL;
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
/* Unlink the element from the list */
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
}
d->ht[table].used--;
return he;
}
prevHe = he;
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return NULL; /* not found */
}
/* Remove an element, returning DICT_OK on success or DICT_ERR if the
* element was not found. */
int dictDelete(dict *ht, const void *key) {
return dictGenericDelete(ht,key,0) ? DICT_OK : DICT_ERR;
}
/* Remove an element from the table, but without actually releasing
* the key, value and dictionary entry. The dictionary entry is returned
* if the element was found (and unlinked from the table), and the user
* should later call `dictFreeUnlinkedEntry()` with it in order to release it.
* Otherwise if the key is not found, NULL is returned.
*
* This function is useful when we want to remove something from the hash
* table but want to use its value before actually deleting the entry.
* Without this function the pattern would require two lookups:
*
* entry = dictFind(...);
* // Do something with entry
* dictDelete(dictionary,entry);
*
* Thanks to this function it is possible to avoid this, and use
* instead:
*
* entry = dictUnlink(dictionary,entry);
* // Do something with entry
* dictFreeUnlinkedEntry(entry); // <- This does not need to lookup again.
*/
dictEntry *dictUnlink(dict *ht, const void *key) {
return dictGenericDelete(ht,key,1);
}
/* You need to call this function to really free the entry after a call
* to dictUnlink(). It's safe to call this function with 'he' = NULL. */
void dictFreeUnlinkedEntry(dict *d, dictEntry *he) {
if (he == NULL) return;
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
}
Rehash的核心函数:
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
/*Returns 1 if there are still keys to move from the old to the new hash table,
*otherwise 0 is returned*/
// 最大访问空桶数量,进一步减小可能引起阻塞的时间。
int empty_visits = n*10; /* Max number of empty buckets to visit. */
//d->rehashidx == -1时,没有进行rehash时直接返回
if (!dictIsRehashing(d)) return 0;
//n为每次迁移的步长,扩容时,每次只移动 n 个元素,防止 redis 阻塞
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
渐进式rehash,每次进行一步长的rehash:
/* This function performs just a step of rehashing, and only if there are
* no safe iterators bound to our hash table. When we have iterators in the
* middle of a rehashing we can't mess with the two hash tables otherwise
* some element can be missed or duplicated.
*
* This function is called by common lookup or update operations in the
* dictionary so that the hash table automatically migrates from H1 to H2
* while it is actively used. */
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
扩容算法:
/* Note that even when dict_can_resize is set to 0, not all resizes are
* prevented: a hash table is still allowed to grow if the ratio between
* the number of elements and the buckets > dict_force_resize_ratio. */
static int dict_can_resize = 1;
static unsigned int dict_force_resize_ratio = 5;
#define DICT_OK 0
#define DICT_ERR 1
/* Expand the hash table if needed */
//判断是否需要扩容
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
//负载因子>1 && (可以扩容 或者 负载因子>5)
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
//这里的ht[0].used*2 并非是将dict扩容为used*2,真正扩容后dict的大小在_dictNextPower里决定
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
/* Expand or create the hash table */
//为dict的ht[1]开辟空间,准备开始扩容
int dictExpand(dict *d, unsigned long size)
{
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
/* This is the initial size of every hash table */
#define DICT_HT_INITIAL_SIZE 4
/* Our hash table capability is a power of two */
static unsigned long _dictNextPower(unsigned long size)
{
unsigned long i = DICT_HT_INITIAL_SIZE;
if (size >= LONG_MAX) return LONG_MAX + 1LU;
while(1) {
if (i >= size)
return i;
i *= 2;
}
}
//即 将hash表的size扩容为第一个大于等于 `ht[0].used * 2` 的 2^n 幂
获取dict的迭代器:
dictIterator *dictGetIterator(dict *d)
{
dictIterator *iter = zmalloc(sizeof(*iter));
iter->d = d;
iter->table = 0;
iter->index = -1;
iter->safe = 0;
iter->entry = NULL;
iter->nextEntry = NULL;
return iter;
}
获取dict的安全迭代器,仅仅只是把safe字段置为1:
dictIterator *dictGetSafeIterator(dict *d) {
dictIterator *i = dictGetIterator(d);
//safe字段用于标识该迭代器是否为一个安全的迭代器。
//如果是,则可以在迭代过程中使用dictDelete、dictFind等方法;
//如果不是,则只能使用dictNext遍历方法
i->safe = 1;
return i;
}
通过迭代器遍历dict:
dictEntry *dictNext(dictIterator *iter)
{
while (1) {
if (iter->entry == NULL) {
dictht *ht = &iter->d->ht[iter->table];
//如果是初次迭代,则要查看是否是安全迭代器,
//如果是安全迭代器则让其对应的字典对象的iterators自增;
//如果不是则记录当前字典的指纹
if (iter->index == -1 && iter->table == 0) {
if (iter->safe)
iter->d->iterators++;
else
iter->fingerprint = dictFingerprint(iter->d); //fingerprint是字典的指纹
}
iter->index++;
//字典已经处于rehash的中间状态,所以还要遍历ht[1]中的元素
if (iter->index >= (long) ht->size) {
if (dictIsRehashing(iter->d) && iter->table == 0) {
iter->table++;
iter->index = 0;
ht = &iter->d->ht[1];
} else {
break;
}
}
iter->entry = ht->table[iter->index];
} else {
iter->entry = iter->nextEntry;
}
if (iter->entry) {
/* We need to save the 'next' here, the iterator user
* may delete the entry we are returning. */
iter->nextEntry = iter->entry->next;
return iter->entry;
}
}
return NULL;
}
如果是初次迭代,则要查看是否是安全迭代器,如果是安全迭代器则让其对应的字典对象的iterators自增;如果不是则记录当前字典的指纹
如果dictht的table、size和used任意一个有变化,则指纹将被改变。这也就意味着,扩容、锁容、rehash、新增元素和删除元素都会改变指纹(除了修改元素内容)
遍历完成后,要调用下面方法释放迭代器。需要注意的是,如果是安全迭代器,就需要让其指向的字典的iterators自减以还原;如果不是,则需要检测前后字典的指纹是否一致
void dictReleaseIterator(dictIterator *iter)
{
if (!(iter->index == -1 && iter->table == 0)) {
if (iter->safe)
iter->d->iterators--;
else
assert(iter->fingerprint == dictFingerprint(iter->d));
}
zfree(iter);
}
我们探讨下什么是安全迭代器。如果是安全迭代器,则可以在迭代过程中使用dictAdd、dictDelete、dictFind等方法;如果不是,则只能使用dictNext遍历方法。源码中我们看到如果safe为1,则让字典iterators自增,这样dict字典库中的操作就不会触发渐进rehash(if (d->iterators == 0) dictRehash(d,1);),从而在一定程度上(消除rehash影响,但是无法阻止用户删除元素)保证了字典结构的稳定。如果不是安全迭代器,则只能使用dictNext方法遍历元素,而像添加元素的dictAdd方法都不能调用。因为dictAdd底层会调用_dictRehashStep让字典结构发生改变。
如果在不安全的迭代器中进行dictAdd、dictDelete、dictFind等方法,这些方法会判断当前dict是否在rehash(if (dictIsRehashing(d)) _dictRehashStep(d);)来调用一次_dictRehashStep,在不安全的迭代器中dict的iterators属性不会自增,因此为0,if (d->iterators == 0)判断成功,调用 dictRehash(d,1);,然后进行了rehash操作,会导致不可预期的问题,比如遍历重复元素或漏掉元素。也就是说在不安全的迭代器中调用dictAdd、dictDelete、dictFind这些方法会导致rehash,使遍历的元素不可预期。
dictScan
而有一个函数可以在rehash的过程中遍历字典,那就是dictScan,这个函数使用的算法非常精妙
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
dictScanBucketFunction* bucketfn,
void *privdata)
{
dictht *t0, *t1;
const dictEntry *de, *next;
unsigned long m0, m1;
if (dictSize(d) == 0) return 0;
//没有rehash时直接遍历
if (!dictIsRehashing(d)) {
t0 = &(d->ht[0]);
m0 = t0->sizemask;
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t0->table[v & m0]);
//将hash表中cursor索引(table[cursor])指向的链表(dictEntry)都遍历一遍
de = t0->table[v & m0];
while (de) {
next = de->next;
//调用用户提供的fn函数,需要对键值对进行的操作
fn(privdata, de);
de = next;
}
/* Set unmasked bits so incrementing the reversed cursor
* operates on the masked bits */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
//将cursor索引赋值为hash表中下一个要遍历的bucket索引,即table[cursor]指向的下一个要遍历的链表
} else {
//正在进行rehash
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the bigger table */
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
//t0小表, t1大表
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t0->table[v & m0]);
//将小表中cursor索引(table[cursor])指向的链表都遍历一遍
de = t0->table[v & m0];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
//再遍历大表t1中相应的索引指向的链表,这里相应的索引见最后的【注】
do {
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t1->table[v & m1]);
de = t1->table[v & m1];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Increment the reverse cursor not covered by the smaller mask.*/
v |= ~m1;
v = rev(v);
v++;
v = rev(v);
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));
}
return v;
}
该算法使用了游标cursor(v)来遍历字典,它表示本次要访问的bucket(table[cursor])的索引。bucket中保存了一个链表,因此每次迭代都会把该bucket的链表中的所有元素都遍历一遍
第一次迭代时,cursor置为0,dictScan函数的返回值作为下一个cursor再次调用dictScan,最终,dictScan函数返回0表示迭代结束
这里cursor的演变是采用了reverse binary iteration方法,也就是每次是向v的最高位加1,并向低位方向进位。比如1101的下一个数是0011,因为1101的前三个数为110,最高位加1,并且向低位进位就是001,所以最终得到0011
//向v的最高位加1,并向低位方向进位
v |= ~m1;
v = rev(v);
v++;
v = rev(v);
计算一个哈希表节点索引的方法是hashkey & mask,其中,mask的值永远是哈希表大小减1。哈希表长度为8,则mask为111,因此,节点的索引值就取决于hashkey的低三位,假设是abc。如果哈希表长度为16,则mask为1111,同样的节点计算得到的哈希值不变,而索引值是?abc,其中?既可能是0,也可能是1,也就是说,该节点在长度为16的哈希表中,索引是0abc或者1abc。以此类推,如果哈希表长度为32,则该节点的索引是00abc,01abc,10abc或者11abc中的一个
哈希表长度分别为8和16时,cursor变化过程:
000 --> 100 --> 010 --> 110 --> 001 --> 101 --> 011 --> 111 --> 000
0000 --> 1000 --> 0100 --> 1100 --> 0010 --> 1010 --> 0110 --> 1110 --> 0001 --> 1001 --> 0101 --> 1101 --> 0011 --> 1011 --> 0111 --> 1111 --> 0000
哈希表长度为8时,第i个cursor(0 <= i <=7),扩展到长度为16的哈希表中,对应的cursor是2i和2i+1,它们是相邻的,这点很重要
首先是字典扩展的情况,假设当前字典哈希表长度为8,在迭代完索引为010的bucket之后,下一个cursor为110。假设在下一次迭代前,字典哈希表长度扩展成了16,110这个cursor,在长度为16的情况下,就成了0110,因此开始迭代索引为0110的bucket中的节点
在长度为8时,已经迭代过的cursor分别是:000,100,010。哈希表长度扩展到16后,在这些索引的bucket中的节点,分布到新的bucket中,新bucket的索引将会是:0000,1000,0100,1100,0010,1010。而这些,正好是将要迭代的0110之前的索引,从0110开始,按照长度为16的哈希表cursor变化过程迭代下去,这样既不会漏掉节点,也不会迭代重复的节点
再看一下字典哈希表缩小的情况,也就是由16缩小为8。在长度为16时,迭代完0100的cursor之后,下一个cursor为1100,假设此时哈希表长度缩小为8。1100这个cursor,在长度为8的情况下,就成了100。因此开始迭代索引为100的bucket中的节点
在长度为16时,已经迭代过的cursor是:0000,1000,0100,哈希表长度缩小后,这些索引的bucket中的节点,分布到新的bucket中,新bucket的索引将会是:000和100。现在要从索引为100的bucket开始迭代,这样不会漏掉节点,但是之前长度为16时,索引为0100中的节点会被重复迭代,然而,也就仅0100这一个bucket中的节点会重复而已
下图,Cursor 6时发生Resize,扩展为之前的2倍

可以看出,高位序Scan在Dict Rehash时即可以避免重复遍历,又能完整返回原始的所有Key。同理,字典缩容时也一样,字典缩容可以看出是反向扩容。
再看代码中的实现:
如果字典当前没有rehash,则比较简单,直接根据v找到需要迭代的bucket索引,针对该bucket中链表中的所有节点,调用用户提供的fn函数。
如果字典当前正在rehash,则需要先遍历较小的哈希表,然后是较大的哈希表。小表t0中,遍历索引为v&m0的bucket中的所有节点,再其扩展到t1中后,遍历其所有可能的bucket中的节点
【注】例如:若t0长度为8,则m0为111,v&m0就是保留v的低三位,假设为abc。若t1长度为32,则m1为11111,该过程就是:遍历完t0中索引为abc的bucket之后,接着遍历t1中,索引为00abc、10abc、01abc、11abc的bucket中的节点