在SQL Server数据库中,查询优化器在处理表连接时,通常会使用一下三种连接方式:
-
-
- 嵌套循环连接(Nested Loop Join)
- 合并连接 (Merge Join)
- Hash连接 (Hash Join)
-
充分理解这三种表连接工作原理,可以使我们在优化SQL Server连接方面的代码有据可依,为开展优化工作提供一定的思路。接下来我们来认识下这三种连接。
1. 嵌套循环连接(Nested Loop Join)
该连接方式通常在小数据量并且语句比较简单的场景中使用,也是比较常见的连接方式,比如以下示例:
1: use AdventureWorks2008
2: go
3: SELECT H.*
4: FROM Sales.SalesOrderHeader H
5: JOIN Sales.Sale
1: use AdventureWorks2008
sOrderDetail D
6: ON H.SalesOrderID=D.SalesOrderID
7: WHERE H.SalesOrderID = 43659
AdventureWorks2008数据库是SQL Server的一个sample,你可以在微软官方网站上自由下载。http://msftdbprodsamples.codeplex.com/releases/view/37109
我们在数据库中运行这段代码:

通过执行计划我们可以看到,数据库的优化器使用了嵌套连接(Neasted Loops),上面第一行中的Sales.SalesOrderHeader表因为只有一行数据所以做为外部表使用,SalesOrderDetail有12行数据做为内部表使用。
嵌套循环的工作原理如图所示:
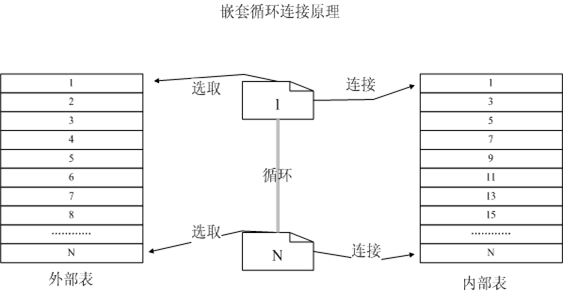
图1 嵌套循环工作原理图
其原理就是根据条件从表中过滤出一个外部链接表,循环的从外部表中读取一行数据,去内部表中进行匹配,伪码如下:
For (i=0;i< Number of outerTable Row;i++)
{
OuterTable[i] connect InnerTable[1,2.....N] To Create New Row
WHERE OuterTable[i].data.value = OuterTable[1,2.....N].data.Value
}
了解嵌套的工作原理后,我们不难发现,这种连接的方式具有一定的局限性的:
1. 因为算法是循环进行的,所以比较适合数据量较小的表进行连接,尤其是外部表的数据。
2. 两张表最好是排序的。表中的条件列和连接列最好有索引,尤其是内部表必须有索引,这样工作效率会成倍增加。
当外部表较小,而内部表较大并且连接字段上有索引的情况下,循环嵌套非常高效。并且嵌套循环是三种方式中唯一支持不等式连接的方式。
2. 合并连接 (Merge Join)
在SQL Server数据库中,如果查询优化器,发现要连接的两张对象表,在连接列上都已经排序并包含索引,那么优化器将会极大可能选择“合并”连接策略。条件是:两个表都是排序的,并且表连接条件中至少有一个等号连接,查询分析器会去选择合并连接。
代码示例:
1: USE AdventureWorks2008
2:
3: GO
4:
5: SELECT P.*
6:
7: FROM Production.ProductModel P
8:
9: JOIN Production.ProductModelProductDescriptionCulture PPMD
10:
11: ON P.ProductModelID = PPMD.ProductModelID
根据执行计划我们可以看到,这次的连接操作使用的合并连接:
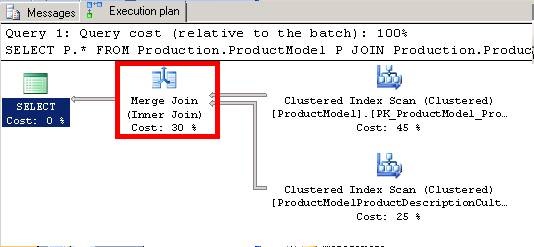
这两张表中,数据量分别为128和762行数据,连接列是表中的主键并且数据是有序的,因此数据库的查询优化器自动选择了合并连接。合并连接的工作原理如下图所示:
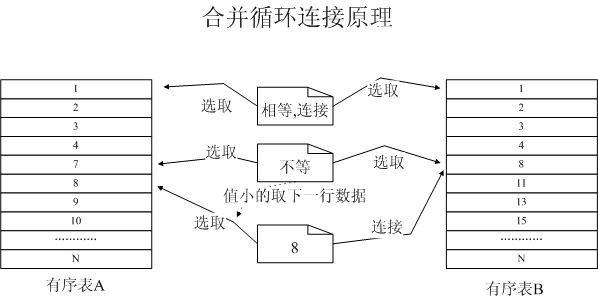
图2 合并连接的工作原理
数据库优化器在决定使用合并连接后,并行的在两个表(术语叫输入集合)中各取第一行数据,进行匹配,匹配则返回匹配行并进行连接。如果不匹配,那么小的那一个表(输入集合),则顺序取下一行数据继续尝试匹配。
通过其工作原理我们可以发现,合并连接可以看成是一个类似于并发工作机制。操作分别在两个表(输入集合)依次获取数据并进行比较,这就要求两张表是有序的,有序的排列会极大的提高工作的效率。
有关表排序的问题,如果连接语句中使用Sort关键字来排序数据表,那么SQL Server的优化器会比较倾向于Hash Join。在合并连接中,并不排斥order by, group by, distinct等关键字,在使用这些语句时,查询优化器也有极大的可能选择合并连接。
当我们使用一些查询限定条件,比如不等式(>,<,>=等)限定条件范围,那么合并连接的效率会有更好。
合并连接的限定条件:
1. 两张表的连接列需要排序
2. 连接列必须有索引
3. 哈希连接(Hash Join)
当我们尝试将两张数据量较大,没有排序和索引的两张表进行连接时,SQL Server的查询优化器会尝试使用Hash Join。
代码示例:
1: SELECT *
2:
3: FROM Production.Product P
4:
5: Join Production.ProductSubcategory SPC
6:
7: on P.ProductSubcategoryID = SPC.ProductSubcategoryID
根据执行计划我们可以看到,这次的连接操作使用的哈希连接:

该连接在处理大量无序的数据时,效率较高,但是对处理器和内存资源的消耗较大。实现过程如下:
Hash Join连接的执行操作分为两个阶段,建立和探测。
建立是指对输入表进行的一系列的操作。首先优化器会将输入表中的每一行数据扫描到系统内存中,然后根据内置的散列算法计算出相应散列值,相同散列值的数据会被分到一个Hash池中。这些散列值和数据地址保存在一个Hash表中,提供给探测使用。通常优化器会选择数据较少的表作为建立输入表。
建立完成后,开始探查工作。另一个连接表(我们叫探查输入)同样会被逐行的扫描、计算,得出一个Hash值。连接操作会使用探查输入的Hash值和建立输入的Hash值列表进行扫描和匹配工作,最终建立连接。
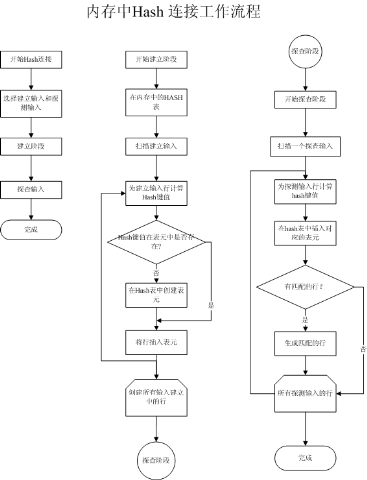
上图是Hash连接的工作流程,接下来我们可以来了解下哈希算法的实现的机制,以下的内容是个人对算法的理解,若有偏颇请指正。
Hash的实际含义是“散列”的意思,它主要的功能就是将一组数据,通过算法,变换成固定长度的输出,这个输出我们就称之为散列值(Hash值),通常在安全领域,如密码学中使用较多。
在SQL Server里面哈希散列函数是黑盒的,没有具体的算法可以参考。实际上很多开发人员在解决海量数据查询的时候,都会采用Hash方式,并且开发适合需求的散列算法。常用的一些算法包括一些取余、MD2、MD4、MD5 和 SHA-1等等。
因为算法,不同的数据可能会生成相同的散列值。它将大量的数据按照规则分散到不同数据堆或者链表中,建立内部的映射关系。我们可以认为他是将数组和链表结合在一起,想要达到一种寻址容易、插入删除方便的数据结构,而Hash表就是一种数据内容和数据存放地址之间的映射关系。
散列函数的选择会决定影响Hash表元数量大小和每个键值包含的数据多少,这个是数学上的问题这里不进行进一步讨论。
说到这里,可能大家还是不太理解,我们这里举例来说明:
比如说有两张表:
表A{A,F,C,D,B,E……}
表B{F,B,E,D,A,F…….}
并且表A的数据量小于表B,这两张表进行Hash连接的过程如下:
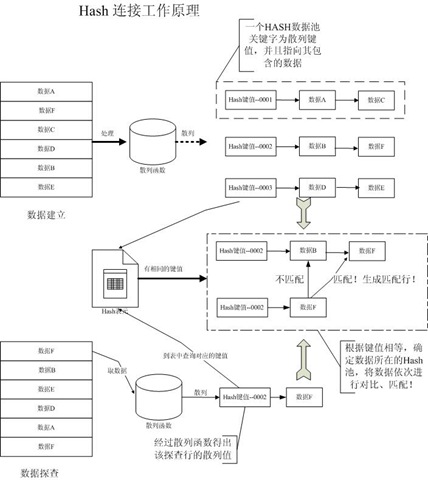
1. 首先数据库会将表A中的所有数据,扫描存入内存中。
2. 内存中的表A的数据,经过散列函数依次得到对应的散列值(Hash值)。
3. 表A中相同散列值(键值)的数据,会统一的放入到一个Hash池中。个人认为Hash池中的数据,就是数组和链表的集合。Hash的键值可以看到是一个数组的下标,而池中的数据以链表的形式连接在数组中。
Hash【键值】-->数据1-->数据2..............
如图中的一组数据,数据A和数据C具有相同的Hash值,值为001,那么他们都被分配到以001命名的Hash池中。
4. 将Hash值和对应的数据,依次存入到一个Hash表中,建立结束。
5. 探测阶段,数据库依次读取扫描表B中的每一行数据,并通过散列函数计算出一个Hash值。
6. 根据Hash值,去Hash表中和表A的键值进行匹配,找到对应的Hash池。
7. 接下来将表B的数据去和对应的Hash池中的每条数据,去对比和匹配。如果匹配成功则进行数据连接。
通过对原理的了解,我们可以看到这种连接方式,需要大量的计算操作,对CPU带来一定的压力。通常Hash 连接操作在内存中进行,如果内存不足,数据库会将数据写入到硬盘中,影响性能。
4.小结
三种连接方式的特点:
| 类型 |
连接列上索引 |
表的大小 |
排序 |
连接子句 |
| 嵌套 |
内部表:必须 外部表:有最好 |
小 |
可选 |
所有类型 |
| 合并 |
内部表:必须 聚簇索引或者覆盖索引 外部表:必须 聚簇索引或者覆盖索引 |
大 |
需要 |
Equi-join |
| HASH |
内部表:不需要 外部表:可选,最好有 小的外部表,大得内部表 |
任意 |
不需要 |
Equi-join |
三种方式对资源的压力:
| 嵌套循环连接 |
合并连接 |
哈希连接 |
|
| CPU |
低 |
低(如果没有显式排序) |
高 |
| 内存 |
低 |
低(如果没有显式排序) |
高 |
| IO |
可能高可能低 |
低 |
可能高可能低 |
以上是个人对三种连接的个人理解,不当之处请指正。
题外话:
其实我们可以把这三种连接比喻成相亲。
嵌套连接就是熟人介绍,亲戚朋友根据你的条件,搜索下周围的资源,然后安排你和几个姑娘见面,看看能不能匹配上。如果你的条件很明确(外部表索引),并且朋友对姑娘比较熟悉,对方的要求也很明确(内部表索引),那么成功率就会比较高。
合并连接就是社区或者网站组织的小型相亲联谊会,比如电影《恋爱33天中》那种8分钟面对面的形式。男女双方面对面进行交谈(匹配判断),每几分钟就换一个人再次交谈,由于大家条件和目的性明确(都有索引),所以整个流程效率会比较高。
Hash连接则就像是万人相亲大会,比如上海的中山公园(条件好的已婚人士慎入)。单身青年的父母,入园后由于各种原因随机的分成各个小群组(经过散列函数分成Hash池)。然后参与者根据自己的判断(确认Hash键值),找到合适小组后(Hash键值相等),依次交谈交换条件和信息(尝试匹配),看看里面有没有合适人选,有就进一步了解(匹配成功,连接)。