第一节:关于模块和类库
使用系统标准库
什么是模块?
可以说,一个 xxx.py 就是一个模块。
什么是类库?
装有很多个模块的文件夹包,可以称为一个类库,更多的时候,这些python文件都是有机关联的。
有了模块和类库,我们可以轻松地站在巨人的肩膀上进行编程,例如我们使用的系统标准库、第三方类库甚至是自己写的类库
- 导入外部模块
从外部导入模块,有导入模块和导入成员两种方式,具体包括:
方式一:import path.module #导入模块
方式二: from path.module import member1,member2,… #导入指定模块下的具体成员
或者 :from path.module import * #导入指定模块下的全部成员
path指代模块所在的路径
module是模块,模块即xxx.py
member可以是变量、函数、类、以及包;
机智的导入:
一个机智式的导入方式为:直写出需要的模块名或成员名,此时系统报语法错误,光标放在报错处,使用【alt】+【enter】快捷键,系统会自动识别和导入;
- 什么是包
含有
_ init _.py的文件夹称之为【包】;
在_ init .py中,我们可以为包中的其它模块做一些全局初始化的工作;
_ init .py可以视为一个【与包名同名的模块】,引入 _init _.py中的成员方式为:
①from 包名 import member
包文件夹中的xxx.py可以视为包模块的成员member,它的导入方式可以是:
①import 包名.xxx,此时包被视为一个普通文件夹路径
②from 包名 import xxx,此时包被视为一个模块,xxx.py被视为一个成员
- 路径path
path是相对路径: 相对于【系统库标准库根目录】或【第三方库根目录】或【当前工程根目录】;
系统标准库根目录所在的位置为:解释器安装目录/Lib/
例如:C:\Python36\Lib;
第三方库根目录所在位置为:解释器安装目录/Lib/site-packages/
例如:C:\Python36\Lib\site-packages;
如果是导入工程内的模块,则相对路径的根目录为当前工程目录;
- 回归测式
回归测试的作用是避免自动触发外部模块的业务逻辑
当我们导入一个自定义模块的时候,如果这个模块在成员定义以外,还包含一定的业务逻辑代码,则这些代码必须被写在【回归测试】中;
如果模块的业务逻辑不写在回归测试中,则外界在将其导入时(无论是导入模块还是导入成员),这些业务逻辑都会被自动触发;
我们通常会在回归测试中,测试一下自己写的函数和类是否正确
回归测试的写法:
if __name__ == '__main__':
# 一些业务逻辑
pass
安装第三方库
系统标准库是安装Python解释器时,自带安装的一些最基本最常用的的Python类库,它们的位置是:解释器安装目录/Lib/;
光有系统标准库是远远不能满足多样化的开发需求的,我们还常常要使用到一些【第三方类库】,它们的位置是:解释器安装目录/Lib/site-packages/;
- 安装第三方类库:
Python解释器自带一个包管理工具
pip.exe,它的位置是:解释器安装目录/Scripts/,通常我们在安装解释器时都选择将这个目录放到系统的环境变量中;
安装方式一:自动化安装第三方类库最简单的方式是在【控制台】中输入:
pip install 包名
包管理器
pip会自动寻找和安装xxx及其所依赖的其它类库
安装方式二:在pip.exe同目录下还存在easy_install.exe,我们同样可以在【控制台】中输入:
easy_install 包名
pip和easy_install二者的区别是:pip 改善了不少 easy_install 的缺点,因此通常pip是一个更好的选择,除非某些类库指定使用easy_install进行安裝
pip的常用命令
安装类库:pip install 包名
更新类库:pip install -U 包名
卸载类库:pip uninstall 包名
检索类库:pip search 包名
查看帮助:pip help
以上命令也都有对应的easy_install版本,其功能是相同的
方式三:使用PyCharm安装和管理类库
打开IDE的
设置,在工程解释器栏目中,我们可以通过点击如图所示的“+”和“-”来执行类库的安装与卸载;
点击“+”后,在弹出的搜索框中输入类库名称,在检索成功后点击install按钮,即可自动化完成安装;
还更多图形化功能,如蓝色升级箭头实现升级、安装时勾选安装到用户的第三方路径等
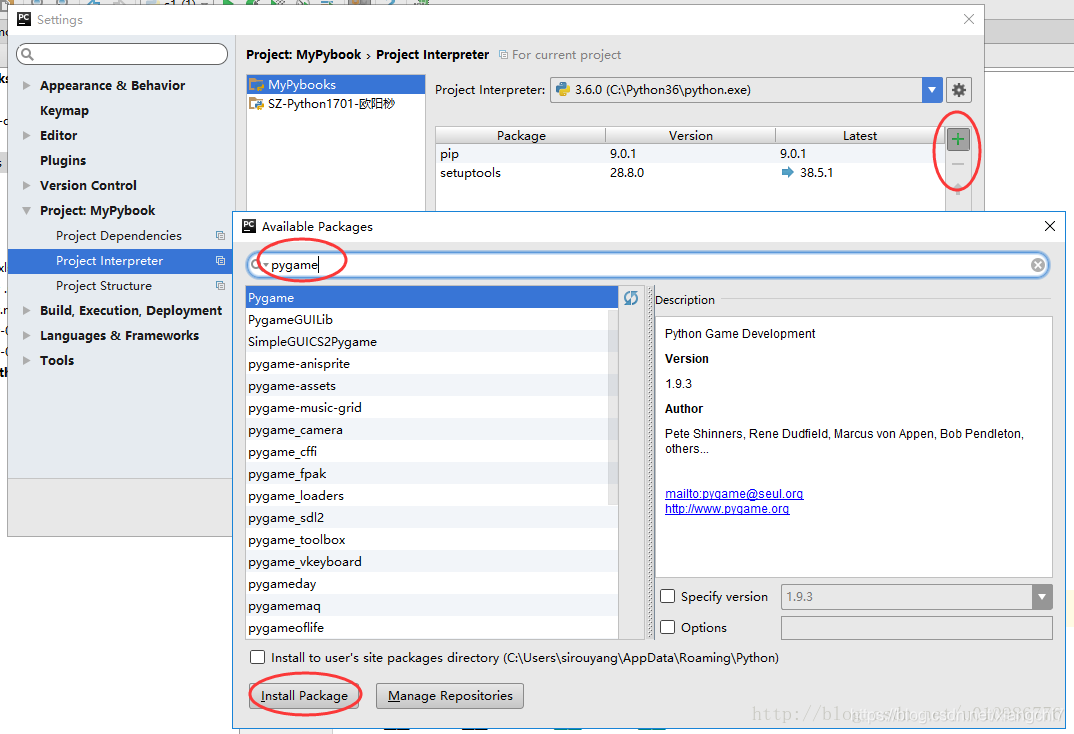
无论使用哪一种方式进行第三式库的安装,安装效果是一样的,安装成功后pycharm就可以简单使用了
使用自己写的类库
- 将模块和包持久化为类库
一个复用率很高的本地的源码目录,我们可以考虑将其持久化为类库,这样就可以在所有工程中进行导入和使用;
持久化的方式很简单,就是将这个文件夹拷贝到【系统库标准库根目录】或【第三方库根目录】中,通常如无特殊必要,我们选择放在【第三方库根目录】中,即解释器安装目录/Lib/site-packages/;
以后就可以像导入系统标准库或安装的第三方类库一样,使用我们自己定义的类库了;
当然,如果愿意共享,以后还可以选择将这部分代码,附带一些说明文档,共享到开源代码管理平台如github上去,供全世界的程序员使用;
第二节:关于时间模块
time模块
- Epoch与Unix时间戳
【Epoch】 是计算机元年,指的是一个特定的时间:
1970-01-01 00:00:00**
【Unix时间戳】 是指从元年到某个时间点所经历的秒数
- 时间占位符
| 占位符 | 格式化意义 | 占位符 | 格式化意义 |
|---|---|---|---|
| %Y: | 表示年份 | %U: | 周,在当年的周数当年的第几周 |
| %m: | 表示月份([01,12]) | %c: | 日期时间的字符串表示。 |
| %d: | 在这个月中的天数 | %x: | 日期字符串(如:04/07/10) |
| %a | 星期的简写 | %X: | 时间字符串(如:10:43:39) |
| %A | 星期的全写 | %w: | 今天在这周的天数,范围为[0, 6],6表示周日 |
| %b | 月份的简写。 | %W: | 周,(当年的第几周) |
| %B | 月份的全写。 | %j: | 在年中的天数 [001,366] |
| %M: | 分钟([00,59]) | %S: | 秒(范围为[00,61],不是0-59) |
| %p: | AM或者PM | %f: | 微秒范,围[0,999999 |
| %H: | 小时(24小时制,[0, 23]) | %z: | 与utc时间的间隔(本地时间,返回空字符串) |
| %I: | 小时(12小时制,[0, 11]) | %Z: | 时区名称(本地时间,返回空字符串) |
- 时间操作的几个常用API
time.time()—— 元年距今时间戳
time.sleep(s)—— 睡眠
time.localtime(s)—— 当地时间
time.asctime(tuple)—— 将时间元组转为美式的时间字符串
time.ctime(s)—— 将时间戳转为时间字符串
time.strftime(foramt, tuple)—— 格式化时间
time.strptime(string,format)—— 将时间字符串转换为时间元组
time.mktime(tuple)—— 将时间元组转换为时间戳
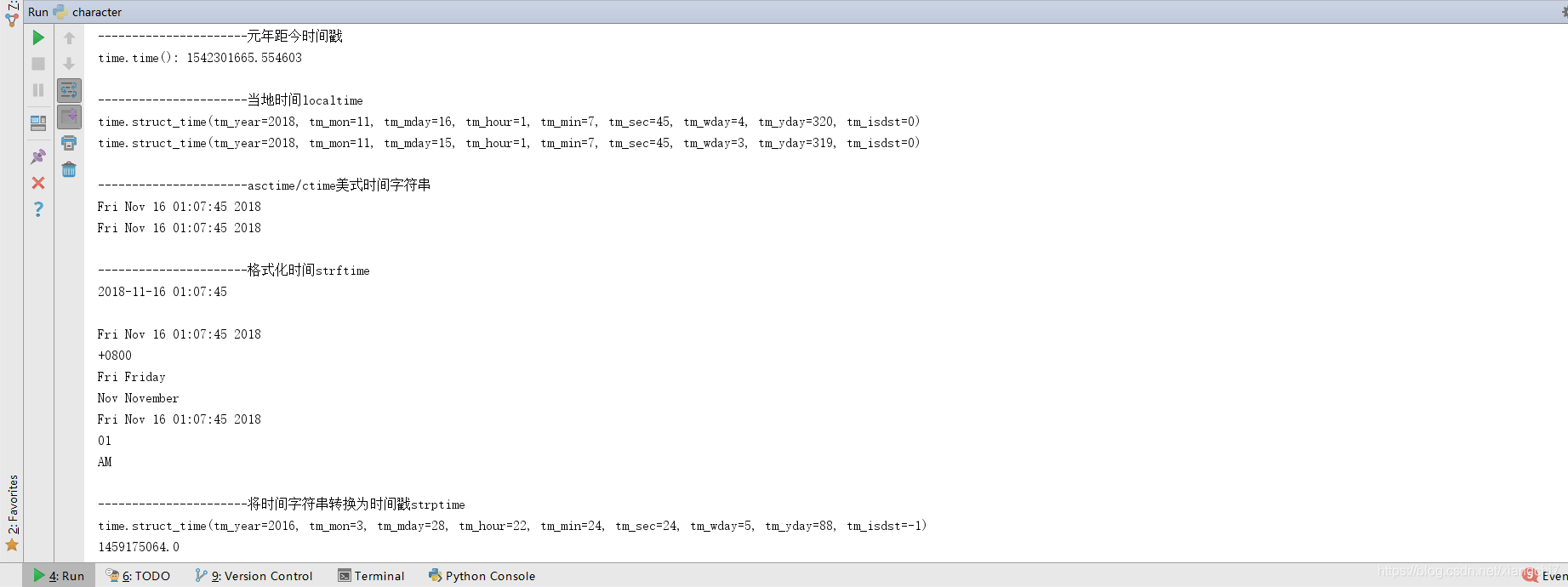
例:
import time
# 元年距今时间戳
print('time.time():',time.time())
# 当地时间localtime,不传参默认当前时间戳,返回结构化时间(时间元组)
print(time.localtime())
# 昨日此刻时间
print(time.localtime(time.time()-24*3600))
# 美式化时间asctime,将时间元组转为时间字符串
print(time.asctime(time.localtime()))
# 美式化时间ctime,将时间戳转为时间字符串
print(time.ctime())
# 格式化成2016-03-20 11:45:39形式
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) # 2018-03-22 21:10:48
# 格式化成Sat Mar 28 22:24:24 2016形式
print(time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()))
print(time.strftime("%z", time.localtime()))
print(time.strftime("%a %A", time.localtime()))
print(time.strftime("%b %B", time.localtime()))
print(time.strftime("%c", time.localtime()))
print(time.strftime("%I", time.localtime()))
print(time.strftime("%p", time.localtime()))
a = "Sat Mar 28 22:24:24 2016"
# 将时间字符串转换为时间元组
print(time.strptime(a, "%a %b %d %H:%M:%S %Y"))
# 将时间元组转换为时间戳
print(time.mktime(time.strptime(a, "%a %b %d %H:%M:%S %Y")))
执行结果:
datetime模块
time模块提供的功能是更加接近于操作系统层面的。通读文档可知,time 模块是围绕着 Unix Timestamp 进行的。time模块表述的日期范围被限定在 1970 - 2038 之间,如果你写的代码需要处理在前面所述范围之外的日期,那可能需要考虑使用datetime模块更好。
在系统的标准库里面,有个模块名为datetime,而datetime模块里还有一个类,也名为datetime,平时导入的时候应注意,导入的应是模块,而不是类,
- datetime的几个常用API
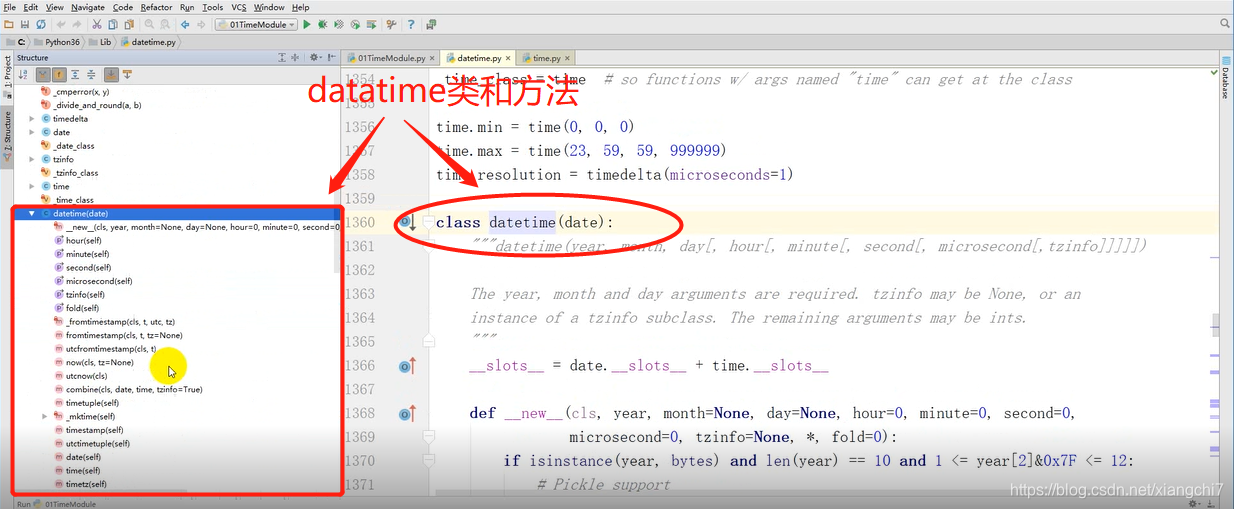
在标准库的datetime模块里有很多方法,这里主要介绍datetime.datetime的方法
datetime.datetime.now()—— 当前的日期和时间
datetime.datetime.now().year—— 当前的年份
datetime.datetime.now().month—— 当前的月份
datetime.datetime.now().day—— 当前的日期
datetime.datetime.now().hour—— 当前小时
datetime.datetime.now().minute—— 当前分钟
datetime.datetime.now().second—— 当前秒
相对于time模块来说,datetime 比 time 高级了不少,也更简洁,返回值也更友好一些。可以理解为 datetime 基于 time 进行了封装,提供了更多实用的函数。
例:
import datetime
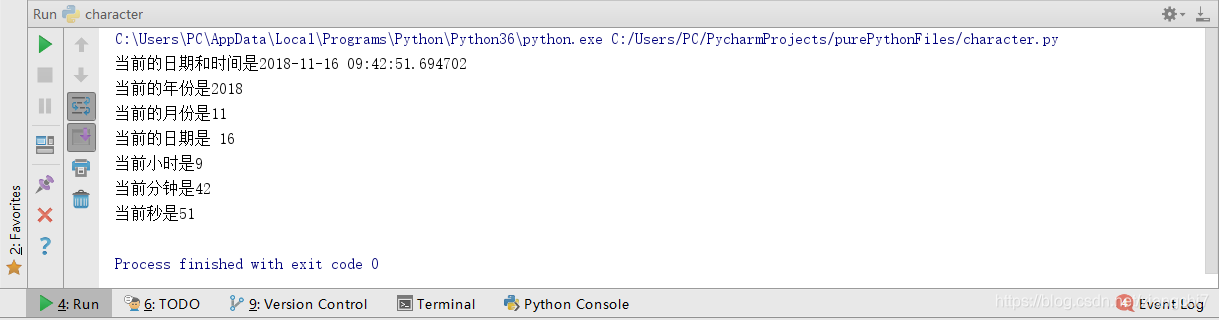
now = datetime.datetime.now()
print("当前的日期和时间是%s" % now)
print("当前的年份是%s" % now.year)
print("当前的月份是%s" % now.month)
print("当前的日期是 %s" % now.day)
print("当前小时是%s" % now.hour)
print("当前分钟是%s" % now.minute)
print("当前秒是%s" % now.second)
执行结果:
calendar日历模块
- 日历模块的几个API
calendar.isleap(year)—— 判断某年是否闰年
calendar.leapdays(fromYear, toYear)—— 判断某段时间的闰年数
calendar.weekday(year, month, day)—— 指定日期的星期
calendar.monthrange(year, month)—— 当月第一天的星期和当月天数
calendar.Calendar()—— 日历对象
calendar.Calendar().itermonthdates(year, month)—— 具体日期的日历生成器
calendar.setfirstweekday(weekNb)—— # 设置一周的起始星期
calendar.month(year, month)—— 指定年月的日历表
例:
import calendar
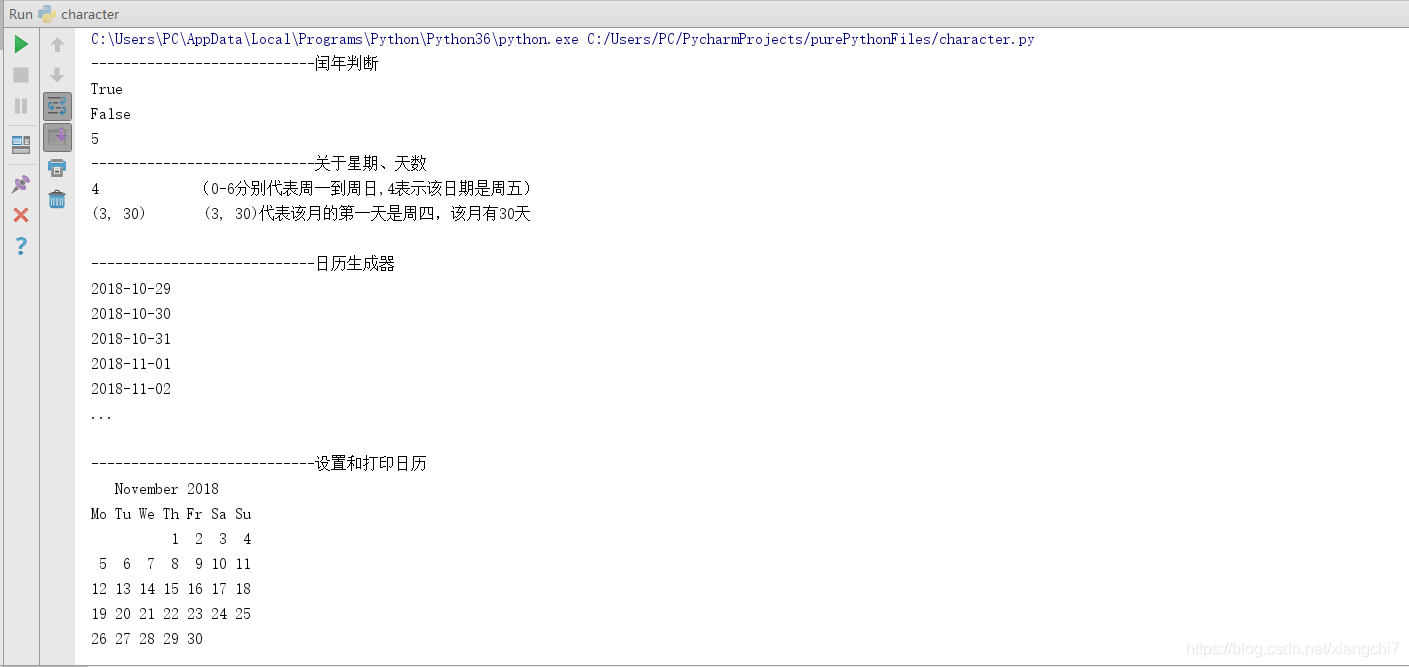
# 闰年判断
print(calendar.isleap(2000))
print(calendar.isleap(2018))
print(calendar.leapdays(2000, 2019)) # 判断2000-2018年之间闰年数
# 返回指定日期的星期(0-6分别代表周一到周日)
print(calendar.weekday(2018, 11, 16))
# 返回当月第一天的星期和当月天数
print(calendar.monthrange(2018, 11))
# 日历生成器
c = calendar.Calendar() # 创建日历对象
monthGenerator = c.itermonthdates(2018, 11) # 获得2018年11月的日历生成器
while True:
try:
print(next(monthGenerator)) #该生成器会从该月第一天所在星期开始生成日期
except StopIteration:
break
# 设置和打印日历
calendar.setfirstweekday(0) # 设置周是以星期一开始
mydate = calendar.month(2018, 11) # 打印2018年11月的日历
print(mydate)
执行结果:
第三节:关于 os 文件模块
使用os模块的操作
os模块是系统标准库模块;
os模块常用的文件操作包括:
1、创建单级或多层级的文件夹、
2、删除单级或多层级空文件夹、
3、删除文件;
os模块中的path子模块常用文件操作:
1、判断路径是否存在
2、判断路径是否是文件/文件夹;
3、删除有内容的文件夹,这时要使用另一个标准库模块:shutil.rmtree(path);
- 相对路径和绝对路径
【绝对路径】是从具体盘符出发的路径;
【相对路径】是从当前py文件位置出发的路径;
相对路径中以一个点“./”代表当前位置,两个点“../”代表上一级文件夹路径;
顺斜线“/”是Linux和Windows下通用的路径分隔符,反斜线则只适用于Windows;
在使用反斜线作为路径分隔符时,通常在路径前面加一个“r”代表所有的反斜线都不是转义字符;
- 文件操作
os.mkdir()—— 创建单级文件夹
os.makedirs()—— 创建层级文件夹
os.rmdir()—— 删除空文件夹
shutil.rmtree()—— 删除有内容的文件夹
os.remove()—— 删除文件
os.removedirs()—— 删除文件夹
例:
import os
import shutil
# 创建单级文件夹(在当前的上一层文件夹位置创建)
os.mkdir(r"../res")
os.mkdir(r"../res/doc")
# 创建层级文件夹(在当前的上一层文件夹位置创建)
os.makedirs(r"../res/img/large")
# 删除空文件夹(在当前的上一层文件夹位置删除)
os.rmdir(r"../res/img")
# 删除有内容的文件夹
shutil.rmtree(r"../res/img")
# 删除文件或文件夹
os.remove(r"../res/doc/1.txt")
os.removedirs(r"../res/doc") # 删除一整条空路径
除了创建和删除文件,还能对文件进行判断
os.path.exists()——判断路径是否存在
os.path.isfile()—— 判断路径是否是文件
os.path.isdir()—— 判断路径是否是文件夹
例:
import os
# 判断路径是否存在
fileExists = os.path.exists(r"./mg.py")
print(fileExists)
# 判断路径是否是文件/文件夹
isFile = os.path.isfile(r"./mg.py")
isDir = os.path.isdir(r"./mg.py")
print(isFile)
print(isDir)
执行结果:

第四节:文件操作
文件指针
一、文件指针类似于光标位置;
二、不同点在于:光标每次移动的是一个字符,而文件指针每次移动一个字节;
三、通过file.tell()可以获取当前文件指针位置;
四、通过file.seek(n)可以将文件指针移动到任意位置;
五、文件的读写都是从当前指针位置向后进行的;
六、在file.truncate(size)中,则是丢弃文件指针以后的内容,进行断尾式的截取;
七、在不同字符集中,每个字符所占的字节数是不同的;
例:utf-8编码下的每个字符占用文件指针位数(也就是字节数):
____1、对于字母和数字,每字符指针移动1位(即占用1字节)
____2、对于空格,每字符指针移动1位(即占用1字节)
____3、对于\n,每字符指针移动2位 (即占用2字节)
____4、对于汉字,每字符指针移动3位 (即占用3字节)
文件的基本读写模式 r、w、a、x
通过系统内建函数
open()我们可以打开一个文件,得到文件流对象file(后文所有file均指文件流对象);
位置参数name代表文件路径,可以是绝对路径或相对路径;
encoding参数指定文件的编码方式,默认为utf-8,编码错误会导致乱码;
mode参数代表以什么模式打开文件,如果打开的是字符流文件,那么有四种基本模式;
1、r(只读模式)
2、w(覆写模式)
3、a(追加模式)
4、x(创写模式);
注意文件夹路径必须是存在的,否则会报FileNotFoundError错误;
注意:读写操作结束,记得关闭已打开的文件流,以释放资源;
- 只读模式 r
open()通过定义参数只读模式
r打开的文件,表示该文件只能读不能写,强写会抛异常;
以只读模式打开的文件,文件指针(暂时可以简单理解为光标)在文件开头位置;
通过file.read(n)可以读入指定数量的字符,n不写默认为读入全部;
在读入的过程中,文件指针会相应的向后移动n个字符位置;
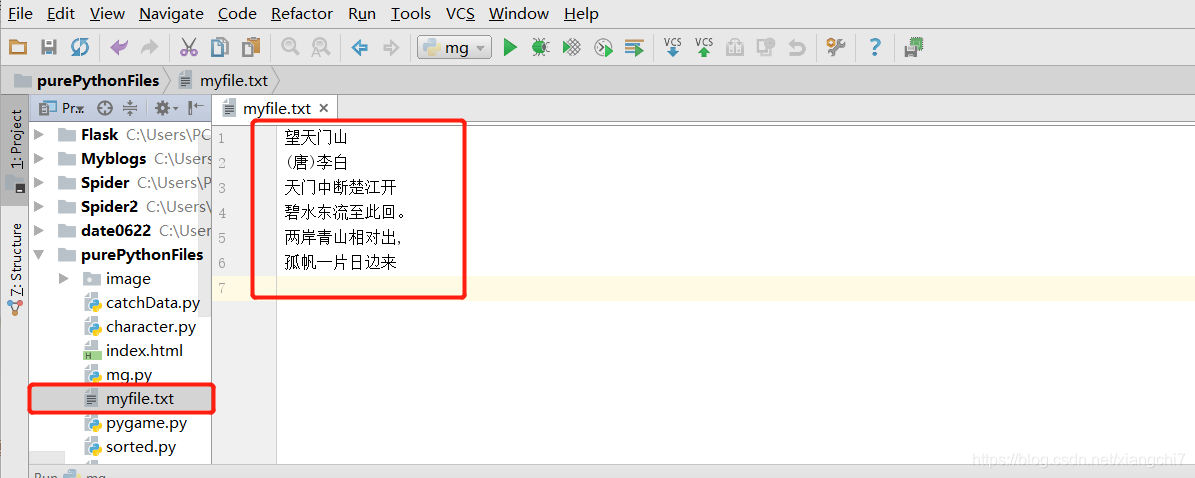
例:在当前目录下创建了一个myfile.txt文件,并写下了一首诗,现在以只读模式打开
# 以只读模式打开文件
file = open(r"./myfile.txt", "r", encoding="utf-8")
# file的类型
print(type(file))
# 读入文件内容
content = file.read(4) # 读入4个字符
# content = file.read()#不写参数表示读入全部
print(content)
# 尝试写入数据(只读模式无法写入,会报错)
# file.write("2018年11月13日") #io.UnsupportedOperation: not writable
# 关闭文件流,注意每次打开操作后一定要关闭
file.close()
执行结果:

- 覆写模式 w
1、以覆写模式
w打开的文件,在文件打开的一刹那文件内容将被清空;
2、使用file.write(text)向文件中写入一个字符串;
3、使用file.writelines(strlist)向文件中写入一个字符串列表,每个字符串元素单独占据一行;
注意:以覆写模式打开的文件是不可读的,强读会抛异常;
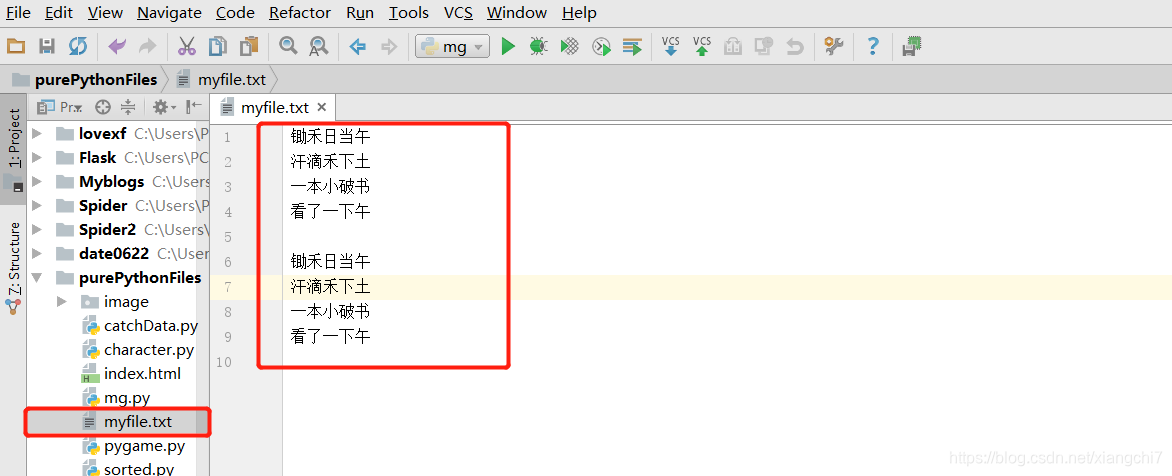
例:同样以上面的file.txt为例,此时里面已经有一首诗《望天门山》
# 以覆写模式打开文件,会清空文件内容(请谨慎)
file = open(r"./myfile.txt", mode="w", encoding="utf-8")
# 写入内容(一个字符串)
file.write("锄禾日当午\n汗滴禾下土\n一本小破书\n看了一下午\n\n")
# 写入内容(一个字符串列表)
file.writelines(["锄禾日当午\n", "汗滴禾下土\n", "一本小破书\n", "看了一下午\n"])
# 尝试读入文件(不可读)
# file.read() #io.UnsupportedOperation: not readable
# 关闭文件流
file.close()
执行完再次手动打开myfile.txt,发现原本内容已清空,并写入了两首诗
- 追加模式 a
已追加模式a打开的文件,文件指针位于
文件的末尾;
此时向文件中写入内容,将以追加的方式写入,原来的内容不会被删除;
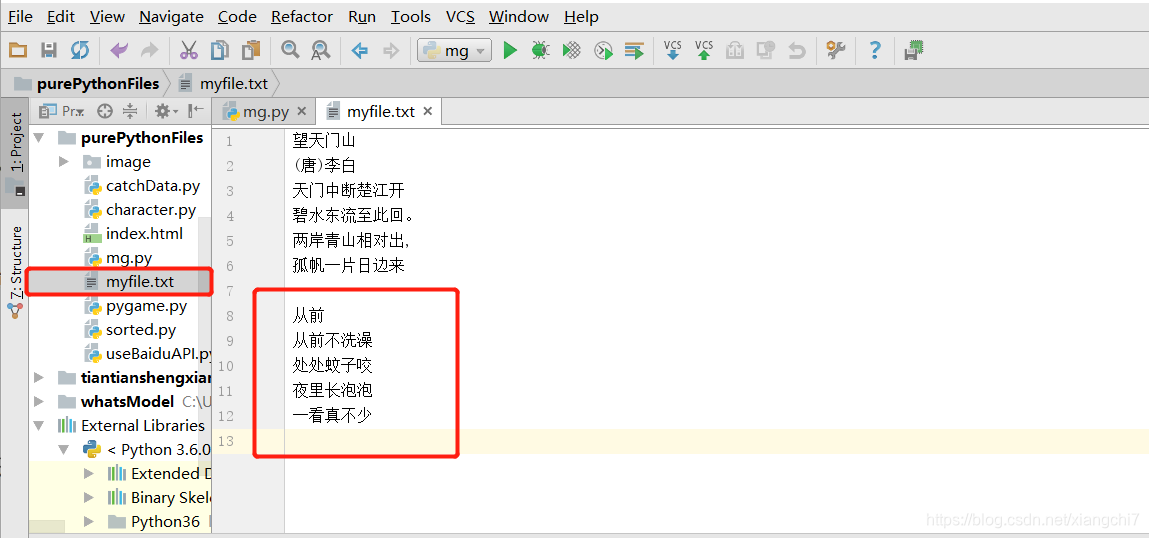
例:以之前写入了《望天门山》的myfile.txt为例,以追加模式,只是向下继续增加内容
# 追加模式打开文件
file = open(r"./myfile.txt", "a", encoding="utf-8")
# 追加一个字符串
file.write("\n从前\n从前不洗澡\n处处蚊子咬\n夜里长泡泡\n一看真不少\n")
# 关闭文件流
file.close()
执行完再次手动打开myfile.txt,发现原本内容不变,并往下新添加了一首诗
- 创写模式 x
以创写模式
x打开的文件必须是一个不存在的文件;
如果文件已经存在会报FileExistsError异常;
使用创写模式结合try…except…我们可以保证打开的都是不存在的文件,而不会覆盖已有的文件;
这里还要提一个
file.flush()的方法:
这是一个保证数据完整性的方法,一般的文件流操作都包含缓冲机制,write方法并不直接将数据写入文件,而是先写入内存中特定的缓冲区。
flush方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区。
正常情况下缓冲区满时,操作系统会自动将缓冲数据写入到文件中。
至于close方法,原理是内部先调用flush方法来刷新缓冲区,再执行关闭操作,这样即使缓冲区数据未满也能保证数据的完整性。
如果进程意外退出或正常退出时而未执行文件的close方法,缓冲区中的内容将会丢失。
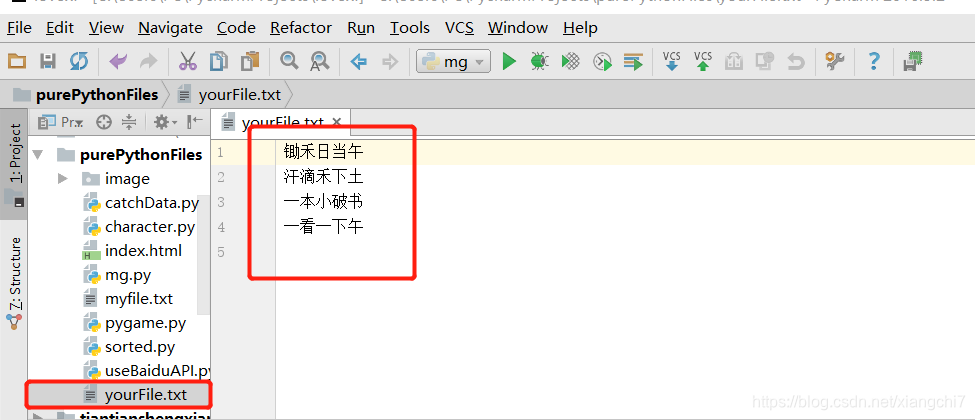
例:
# 以创写模式打开一个并不存在的文件
file = open(r"./yourFile.txt", "x", encoding="utf-8")
# 向文档中写入数据
file.write("锄禾日当午\n汗滴禾下土\n一本小破书\n一看一下午\n")
# 让写入(缓存在缓冲区中)立刻生效
file.flush()
# 关闭文件流
file.close()
执行结果:自动生成文件yourFile.txt,并写入了内容
文件的字节读写模式 rb,wb,ab,xb
- 字节流文件的读写
通过基本读写模式(只读r,覆写w,追加a,创写x)我们可以方便地操作字符流文件的读写;
对于【字节流文件】(一切非字符型文件,包括媒体文件、可执行文件、压缩包、等等),我们则需要使用字节读写模式来进行相应的读写操作;
与基本读写模式对应,字节读写模式有四种:rb,wb,ab,xb,分别对应字节只读、字节覆写、字节追加、字节创写;
字节读写模式与普通读写模式所不同的,仅仅在于读入和写出的内容都是字节形式,而非以字符串形式;
首先打开文件,看看文件的字节流
例:
# 以字节只读模式打开一张图片文件
myFile = open(r"./image/timg.jpg", "rb")
myBytes = myFile.read()
print(myBytes)
执行结果:
例:拷贝图片
图片属于媒体文件,不论读写都应以相应的字节模式来操作;
我们以字节只读方式打开被拷贝的文件,以字节创写模式创建并打开一个要拷贝到的目标文件;
通过file.read(size)我们可以读出指定字节数的内容,默认为读出全部;
通过file.write(content)我们可以写入指定的内容(字符字节都可以);
最终记得关闭本体和目标两个文件;
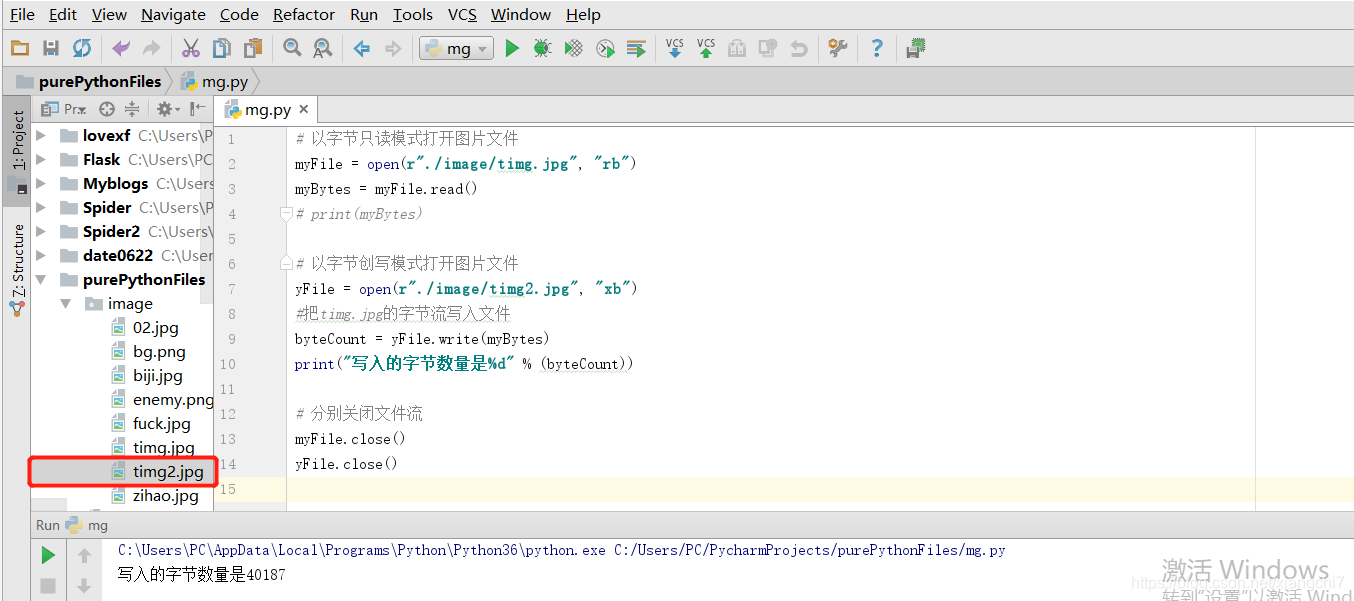
# 以字节只读模式打开图片文件
myFile = open(r"./image/timg.jpg", "rb")
myBytes = myFile.read()
# print(myBytes)
# 以字节创写模式打开图片文件
yFile = open(r"./image/timg2.jpg", "xb")
#把timg.jpg的字节流写入文件
byteCount = yFile.write(myBytes)
print("写入的字节数量是%d" % (byteCount))
# 分别关闭文件流
myFile.close()
yFile.close()
执行结果:成功地复制了一张图片
文件的加强读写模式 r+、w+、a+
字符流文件的四种基本读写模式:r/w/a/x,都是只能读或只能写的,强读强写会报错
接下来要介绍的【加强读写模式】则是全部是可读可写的;
它们分别是:
1、读优先的r+,
2、覆写优先的w+,
3、追加优先的a+;
它们之间的区别在于文件打开时,文件指针的位置在哪;
- 读优先的加强模式 r+
文件打开时,文件指针位于
0的位置,便于从头开始读取文件;
因此我们称它是读优先的;
例:
file = open(r"./myfile.txt", "r+", encoding="utf-8")
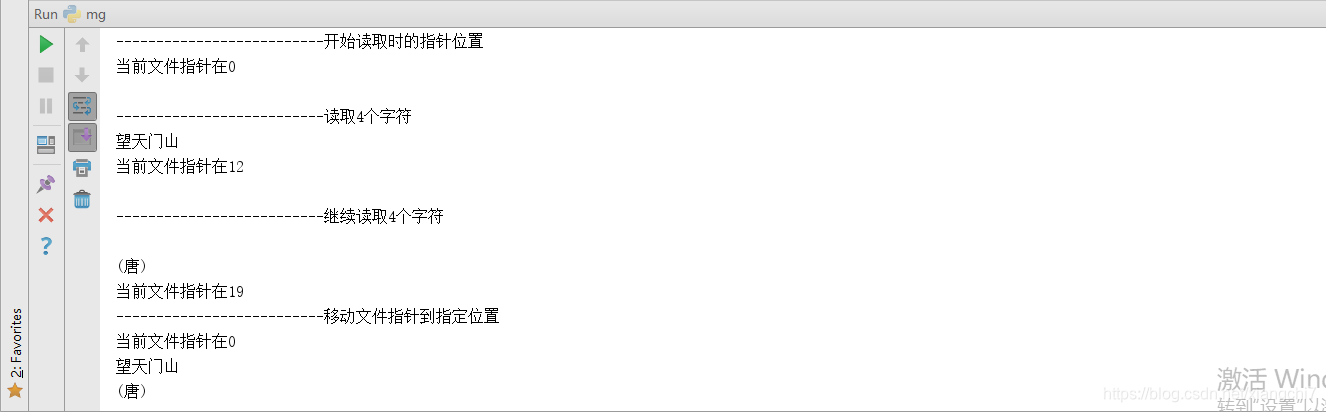
# 开始读取时的指针位置'
print("当前文件指针在%d" % (file.tell()))
# 读取4个字符。对于ASCII字符,每字符指针移动1位,对于汉字,每字符指针移动3位
print(file.read(4))
print("当前文件指针在%d" % (file.tell()))
# 继续读取4个字符
print(file.read(4))
print("当前文件指针在%d" % (file.tell()))
# 继续移动文件指针到指定位置
file.seek(0)
print("当前文件指针在%d" % (file.tell()))
print(file.read(8))
# 写入内容
# 写入之前应明确地seek到指定位置,否则会追加在末尾,但是指定位置也有缺点,就是会覆盖后面的文字
#此处移动到倒数第二个文字之后
file.seek(196)
file.write("唐诗三百首")
#关闭文件流
file.close()
执行结果:
 文件内容执行后结果:我们发现,最后一个字被覆盖了。
文件内容执行后结果:我们发现,最后一个字被覆盖了。
我们发现,最后一个字被覆盖了。当然也可以不seek到指定位置,此时就会把内容追加在末尾
- 覆写优先的加强模式 w+
文件以w+打开时,内容会被
清空,自然文件指针也就位于0的位置;
这种模式先清空内容以便覆写,因此我们称它是覆写优先的;
例:
file = open(r"./myfile.txt", "w+", encoding="utf-8")
# 可读可写,打开文件时内容被清空
print('此时指针在:',file.tell())
print('内容是:',file.read())
# 写入内容
file.write("别人笑我太疯癫,我笑他人看不穿")
print('写入内容后指针在:',file.tell())
# 移动指针
file.seek(0)
print('此时指针在:',file.tell())
print('内容是:',file.read())
print('读取内容后指针在:',file.tell())
# 半闭文件流
file.close()
执行结果:

- 追加优先的加强模式 a+
文件以a+模式打开时,文件指针位于
末尾的位置,便于我们追加内容;因此我们称它是追加优先的;
例:
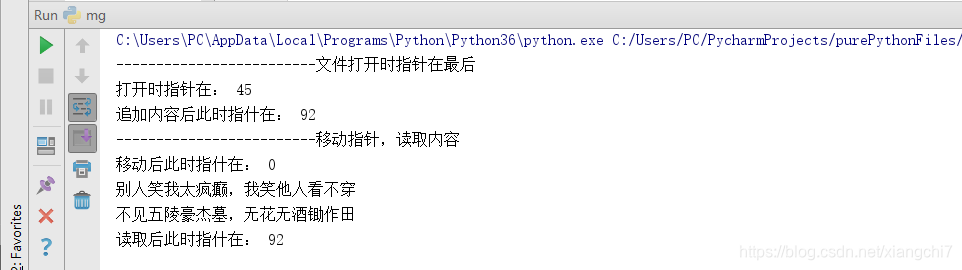
file = open(r"./myfile.txt", "a+", encoding="utf-8")
# 文件打开时指针在最后
print('打开时指针在:',file.tell())
# 追加文字
file.write("\n不见五陵豪杰墓,无花无酒锄作田")
print('追加内容后此时指什在:',file.tell())
# 移动指针,读取内容(一定要移动指针到0,才可以读取内容,读取原则是读取指针后面的内容)
file.seek(0)
print('移动后此时指什在:',file.tell())
print(file.read())
print('读取后此时指什在:',file.tell())
# 关闭文件流
file.close()
执行结果:
文档的遍历和截取
- 文档的遍历
文档的遍历常用的有三种方式:
1、逐行readliine()读取,
2、readlines()拿到所有行的列表,
3、迭代器式遍历;
例:在myfile.txt内写下了4行诗句,对此文档进行遍历。
方式1:通过file.readline()逐行读取
file = open(r"./myfile.txt", "r", encoding="utf-8")
#一个file.readline(),就读取一行
print(file.readline())
print(file.readline())
print(file.readline())
print(file.readline())
# 关闭文件流
file.close()
执行结果:
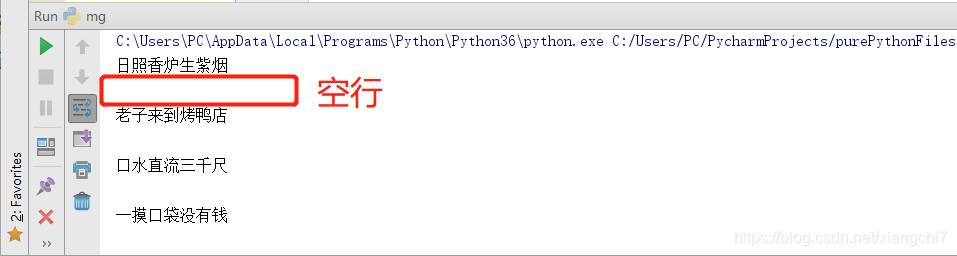
使用此方法,可以一行一行读取,一个file.readline()就能读取一行,读取后会自动生成一行空行(不会对原文产生更改),如果文档的篇幅很长,此方法将过于累人。
方式2:通过file.readlines()得到所有行形成的列表,再对列表进行遍历
file = open(r"./myfile.txt", "r", encoding="utf-8")
# 把得到的所有行形成的列表lineList
lineList = file.readlines()
#对列表进行遍历
for line in lineList:
print(line, end="")
file.close()
执行结果:
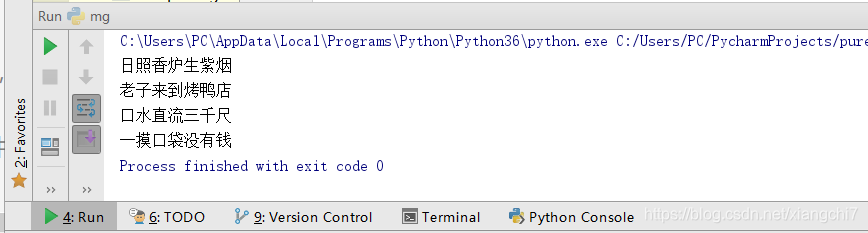
对列表遍历出来的元素line,系统会默认给它加上一个换行符,如果不想每遍历一行又多出一行,需加上end=’ ’
方式3:将文件作为一个迭代器进行遍历,其中的每一个元素为一行文本
file = open(r"./myfile.txt", "r", encoding="utf-8")
# 把文档file 当作一个可迭代对象进行遍历
for line in file:
# 和方式二一样,每个元素系统都会默认添加一个换行符,需用end=''替换
print(line, end="")
file.close()
- 文档的截取
file.truncate(size)函数表示对文档进行断尾式截取(即丢弃当前文件指针以后的部分);
size参数为文件指针位置,不传时默认从当前文件指针位置进行断尾截取;
当传递一个整型size时,直接将文件指针size以后的部分丢弃
file = open(r"./myfile.txt", "r+", encoding="utf-8")
# 不带参数时,从当前指针位置断尾
print('文件打开时指针在:',file.tell())
# 移动指针
file.seek(46)
file.truncate()
file.seek(0)
print('在指针46处截取后内容:')
print(file.read())
# 带有指针参数时,无视指针位置,直接从0截取23个字节
file.truncate(23)
file.seek(0)
print('带参数截取后内容:')
print(file.read())
file.close()
执行结果:
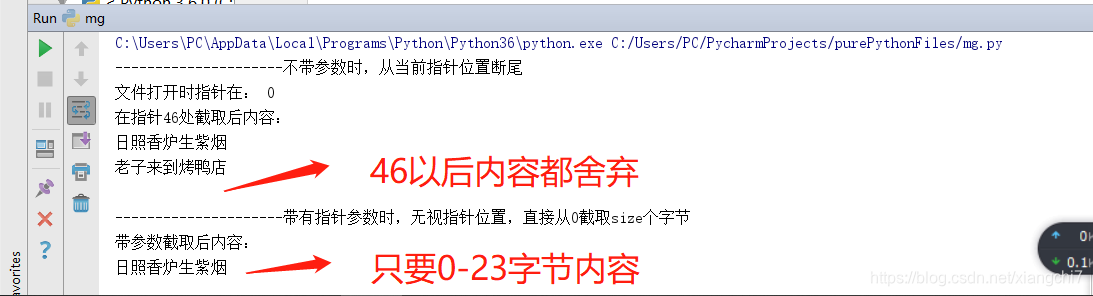 注意:截取过程结束后,对原文档myfile.txt的内容也是有相同的影响的。
注意:截取过程结束后,对原文档myfile.txt的内容也是有相同的影响的。
使用pickle进行二进制IO
通常的文件读写要么是读入/写出字符,要么是读入/写出字节;
【二进制IO】是指直接是读入/写出Python数据类型的值;
二进制IO可以给小规模的数据读写带来极大的便利;其底层原理,仍是某种形式的对象到字节的“编码”,以及字节到对象的“解码”;
对文件进行二进制IO时,文件的打开方模式必须是字节读写模式;我们习惯上将存储二进制IO数据的文件以.dat后缀命名;
pickle是系统标准库所提供的二进制IO模块;
通过pickle.dump(data,outfile)和pickle.load(infile)我们可以方便地写出和读入Python对象;
- 序列化 (卸载)
在二进制IO中,写出称为序列化(即将Pytho对象转为字节),又称为卸载;
例:向.dat文档中写入整型、浮点型、布尔型、以及列表类型的Python数据对象:
import pickle
# 卸载,序列化
outfile = open(r"./myPickle.dat","wb")
pickle.dump(123,outfile)
pickle.dump(45.6,outfile)
pickle.dump(True,outfile)
pickle.dump(["fuck","shit","welcome"],outfile)
outfile.close()
- 反序列化 (加载)
在二进制IO中,读入称为反序列化(即将字节转为Pytho对象),又称为加载;
file.load(infile)每次加载一条当初写出的数据,能够load的次数和当初dump的次数是相等的;
例:从.dat文档中读入刚刚写的Python数据对象:
import pickle
# 加载,反序列化
infile = open(r"./myPickle.dat", "rb")
print(pickle.load(infile))
print(pickle.load(infile))
print(pickle.load(infile))
print(pickle.load(infile))
infile.close()
执行结果:
- EOFError
全称为
End Of File Error,即文件末尾错误;
对于一个二进制IO写出的文件,写的时候进行了几次dump,则读入时就只能对应几次load的动作;如果load次数已经达到当初dump写出的次数,再继续load系统就会抛出EOFError;
当然为了保证load完所有数据,保证程序不崩溃,结合死循环和try...except来编码就可以了
例:运用上面读入文件内容(反序列化 )的例子,此时可变为
import pickle
# 运用try...exceptf进行加载,反序列化 ,保证运行
infile = open(r"./myPickle.dat", "rb")
try:
while True:
# 只要还有数据就加载内容
print(pickle.load(infile))
except EOFError:
print('对不起,已经没有了,就这么多数据')
infile.close()
使用tkinter定位本地文件
我们发现,每次打开文件时硬编码写下路径,不但是痛苦的,而且是欠灵活的;这时我们可以试着使用系统标准
GUI库tkinter,那我们就可以很轻松的实现可视化的文件路径选择;
- API
tkinter.filedialog下的
askopenfilename()和asksaveasfilename(),操作系统会弹出文件选择对话框,让用户选择一个要打开或另存为的地址
两个API所返回的都是字符串型的文件路径,到底是“打开”还是“另存为”完全取决于业务逻辑;
tkinter.filedialog.askopenfilename() ————从路径选择对话框中选择要打开的文件位置
tkinter.filedialog.asksaveasfilename() ————从文件路径对话框中选择要保存的位置
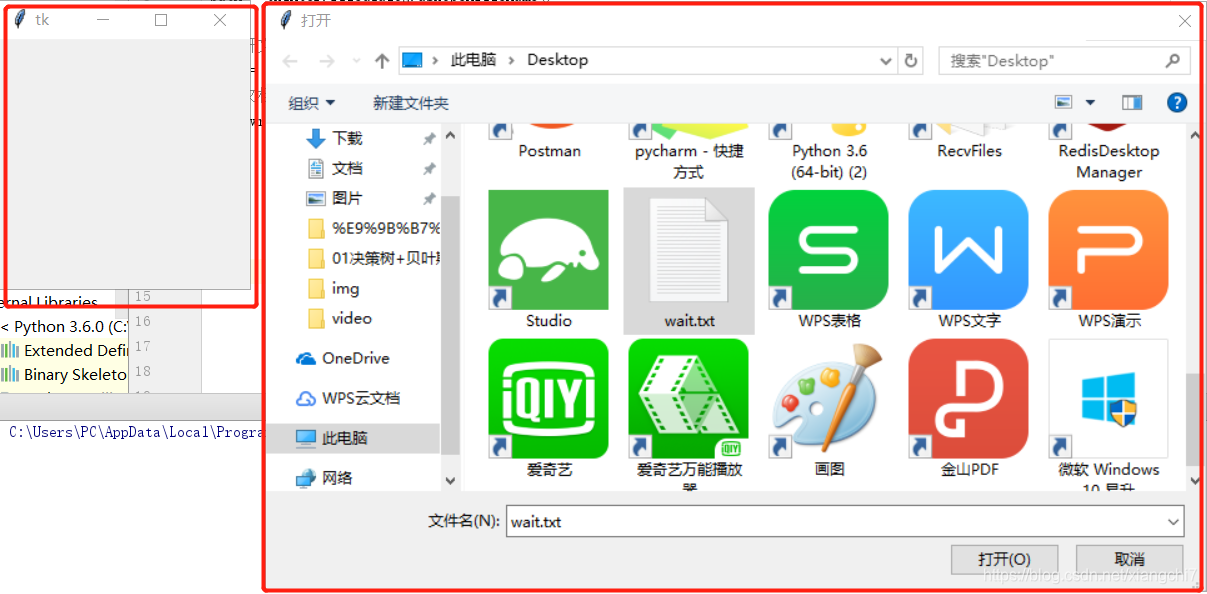
例:桌面有一个wait.txt文件
import tkinter.filedialog
# 从路径选择对话框中选择要打开的文件位置
path = tkinter.filedialog.askopenfilename()
# 以覆写模式打开文件
file = open(path, "w", encoding="utf-8")
# 向文档中写入数据
file.write("锄禾日当午\n汗滴禾下土\n一本小破书\n一看一下午\n")
# 关闭文件流
file.close()
执行结果:直接对话框中选择要打开的文件
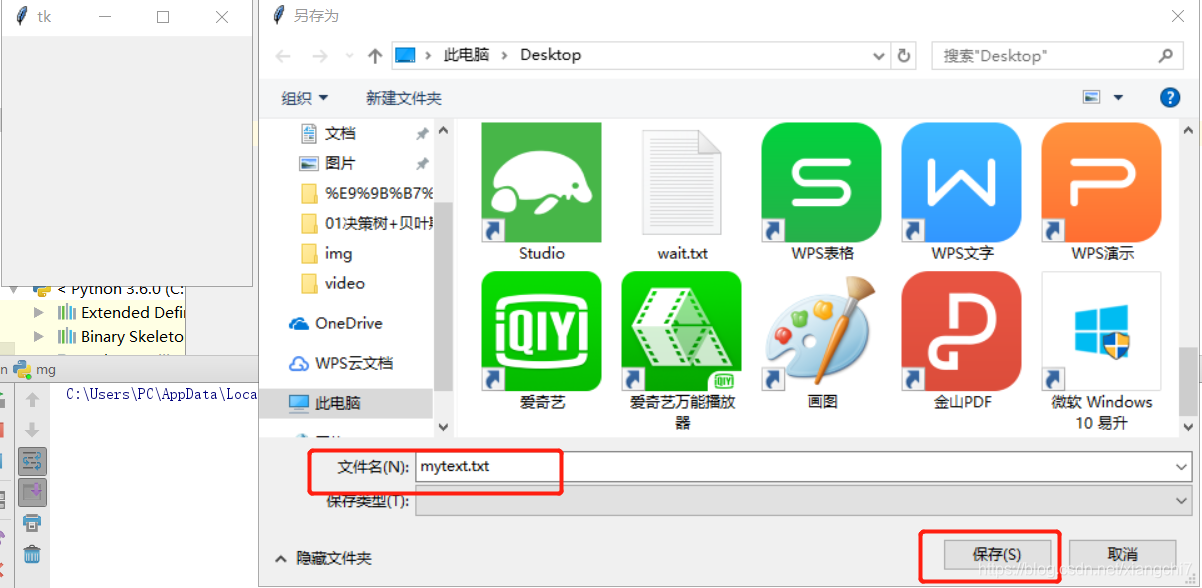
例:在桌面上创写一个mytext.txt文件
import tkinter.filedialog
#从文件路径对话框中选择要保存的位置
path = tkinter.filedialog.asksaveasfilename()
# 以创写模式打开文件
file = open(path, "x", encoding="utf-8")
# 向文档中写入数据
file.write("我随便写入了一些数据")
# 关闭文件流
file.close()
执行结果:直接对话框中选择要保存的位置和定义文件名
CSV文件读写
CSV是一种常见的、轻量的、表格样式的、文档文件类型;
CSV在数据挖掘和机器学习中使用广泛;
在手写时可以逐行写入值,值之间用英文逗号分隔;
打开时可以使用文本文档或Excel打开;
csv.writer(file)—— CSV的写入对象
csv.reader(file)——CSV的读取对象
csv.writer(file).writerow([value, value, value])—— 一次写入一行信息
csv.writer(file).writerows(lines)——同时写入多行信息
创写CSV文件
例:
import csv
import random
# 写入CSV文件
#以文档覆写模式(w,a,x)打开文件,newline=""表示行与行之间没有特殊分隔
with open("./test.csv", mode="w", encoding="utf-8", newline="") as file:
# 创建基于文件的writer
csvWriter = csv.writer(file)
# 写入一行数据
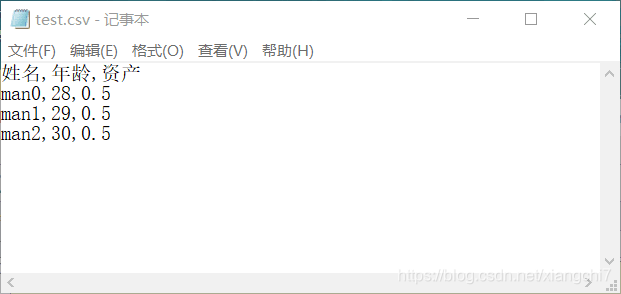
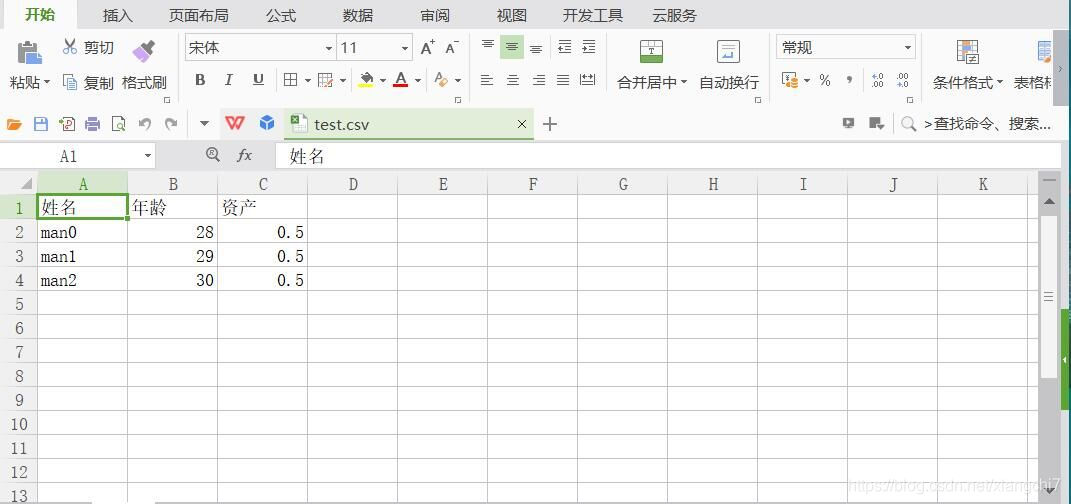
csvWriter.writerow(["姓名", "年龄", "资产"])
# 写入3行数据
for i in range(3):
csvWriter.writerow(["man%d" % (i), random.randint(20, 30), 0.5])
print("第%s行写入成功!"%i)
执行结果:生成CSV文件
打开CSV文件
- 1、以文本文档打开
- 2、用Excel打开
读取CSV文件内容
例:
import csv
# 以只读模式打开文件
with open("./test.csv", mode="r", encoding="utf-8") as file:
# 创建基于文件的reader
csvReader = csv.reader(file)
# 遍历所有行
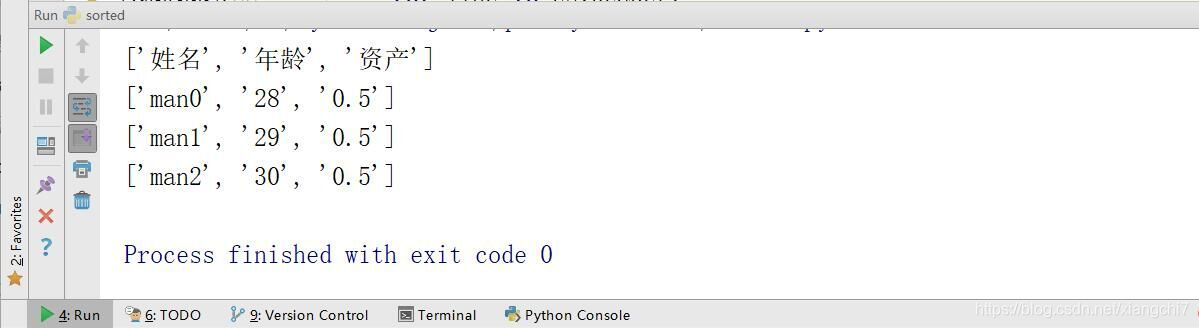
for line in csvReader:
print(line)
执行结果:
JSON文件的读写
json是一种轻量级的结构化数据存储标准;其结构直观、体积小(便于网络传输)、编码和解码方便,应用领域十分广泛;
json对数据的描述,是使用{}表示对象,使用[]表示集合,使用键值对表示属性和值;
这种数据描述方式与Python语言中的字典、列表十分相似,因此转化也十分方便;
Python标准库提供了专用的json解析模块,其名称也叫json;
json.dumps(data, ensure_ascii=False)—— 把py内容转为json字符串
json.loads(jsonStr, encoding="utf-8")—— 把json字符串转为py内容
json.dump(data, file, ensure_ascii=False)—— 把py内容写入json文件
json.load(file)—— 把json文件读出py内容
Python数据和json字符串的相互转化
例:
import json
# 定义一个待转化的Python对象,可以是字典或列表
data = {"name": "张三疯", "age": 120, "hobby": ["修道", "养生", "练太极"]}
# data = [
# {"name": "张四疯", "age": 120, "hobby": ["修道", "养生", "练太极"]},
# {"name": "张五疯", "age": 120, "hobby": ["修道", "养生", "练太极"]}
# ]
# 将Python数据(字典或列表)转换为json字符串,注意ensure_ascii默认是为True的
jsonStr = json.dumps(data, ensure_ascii=False)
print(type(jsonStr), jsonStr)
# 将json字符串读入为Python数据(字典或列表)
pyData = json.loads(jsonStr, encoding="utf-8")
print(type(pyData),pyData)
执行结果:

Python数据和json文件的相互转化
例:
import json
# 定义一个待转化的Python对象,可以是字典或列表
data = {"name": "张三疯", "age": 120, "hobby": ["修道", "养生", "练太极"]}
# data = [
# {"name": "张四疯", "age": 120, "hobby": ["修道", "养生", "练太极"]},
# {"name": "张五疯", "age": 120, "hobby": ["修道", "养生", "练太极"]}
# ]
# 将Python数据(列表或字典)写出到json文件
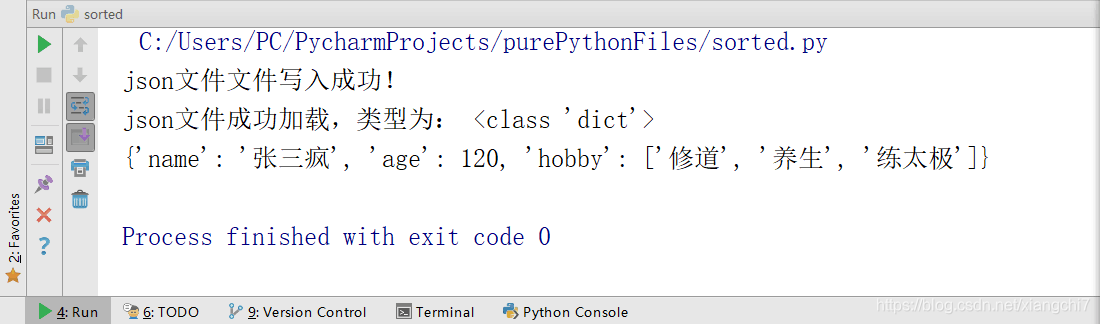
with open("./mydata.json", "w", encoding="utf-8") as file:
json.dump(data, file, ensure_ascii=False)
print("json文件文件写入成功!")
# 将json文件读入为Python数据(列表或字典)
with open("./mydata.json", "r", encoding="utf-8") as file:
data = json.load(file)
print("json文件成功加载,类型为:",type(data))
print(data)
执行结果:
文件模块常用API汇总
open(filepath, mode='r', encoding=None) ————打开文件,得到文件流对象
file.close() ————关闭文件
file.tell() ————返回文件指针位置
file.seek(n) ————移动文件指针
file.read(n) ————读入n个字符,返回读到的内容
file.readline() ————读取一行文本,返回读入的文本
file.readlines() ————读入文本的所有行,返回一个列表
file.write(content) ————向文件中写入内容,可以是字符或字节,返回写出的字节数
file.writelines(mlist) ————向文件中写入一个文本行的列表
file.flush() ————立即将缓冲区的内容写入文件
file.truncate() ————从当前文件指针位置断尾截取文件
file.truncate(n) ————从指定的文件指针位置断尾截取文件