分析:
- 要想实现数据的拷贝,肯定要通过流的方式来完成,因为我们并不知道是文字数据还是什么类型的数据,所以我们采用字节流
- 在进行拷贝的时候:开辟一个固定大小的字节数组,每次读入字节数组大小的数据,然后把这些数据写入另一个目标文件中,直至将目标文件的数据读取完毕。在while这其实也就是边读边写的过程。
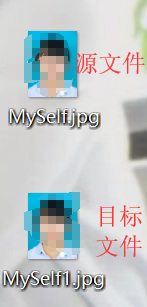
例如:将桌面上的一个图片文件进行拷贝,也拷贝到桌面上
package www.java.test;
import java.io.*;
public class Test{
public static void main(String[] args) throws Exception{
//源文件路径
String sourceFilePath = "C:"+File.separator+"Users"+File.separator+"Calm"+File.separator+"Desktop"+File.separator+"MySelf.jpg";
//目标文件路径
String destFilePath = "C:"+File.separator+"Users"+File.separator+"Calm"+File.separator+"Desktop"+File.separator+"MySelf1.jpg";
boolean result = copyFile(sourceFilePath, destFilePath);
System.out.println(result);
}
public static boolean copyFile(String sourceFilePath, String destFilePath) throws Exception{
//取得File对象
File sourceFile = new File(sourceFilePath);
File destFile = new File(destFilePath);
//取得源文件的输入流
InputStream in = new FileInputStream(sourceFile);
//取得目标文件的输出流
OutputStream out = new FileOutputStream(destFile);
//创建一个字节数组,用来存储读入的数据,相当于是一个缓冲区,一次性读入多个数据
byte[] data = new byte[1024];
int len = 0;
while((len = in.read(data)) != -1){//当源文件数据没读取完时,不断读取数据到data数组中
out.write(data, 0, len);//把data中数据写入目标文件中,这里len代表的是真正读取数据个数,
// 因为最终读取到的数据个数不一定就是字节数组大小,所以,只需要将所有读入的数据写出就好
}
return true;
}
}
这段代码运行完之后,你就会发现桌面上会出现两张一模一样的图片文件,只是名字不同。
至于len的具体含义,可以参考我的这篇博客https://mp.csdn.net/mdeditor/84673911#
还有一种就是初期的文件拷贝模型,那种是没有缓冲区的,一次只读取一个数据,速度比较慢,所以我们一般采用上边的那种模型。
我们可以看看初期文件拷贝的代码:
package www.java.test;
import java.io.*;
public class Test{
public static void main(String[] args) throws Exception{
//源文件路径
String sourceFilePath = "C:"+File.separator+"Users"+File.separator+"Calm"+File.separator+"Desktop"+File.separator+"MySelf.jpg";
//目标文件路径
String destFilePath = "C:"+File.separator+"Users"+File.separator+"Calm"+File.separator+"Desktop"+File.separator+"MySelf1.jpg";
boolean result = copyFile(sourceFilePath, destFilePath);
System.out.println(result);
}
public static boolean copyFile(String sourceFilePath, String destFilePath) throws Exception{
long start = System.currentTimeMillis();
//取得File对象
File sourceFile = new File(sourceFilePath);
File destFile = new File(destFilePath);
//取得源文件的输入流
InputStream in = new FileInputStream(sourceFile);
//取得目标文件的输出流
OutputStream out = new FileOutputStream(destFile);
int len = 0;
while((len = in.read()) != -1){//当源文件数据没读取完时,不断读取数据到data数组中,一次只能读取一个数据
out.write(len);//将读取到的数据写到目标文件中,但一次只能写入一个数据
}
long end = System.currentTimeMillis();
System.out.println("文件拷贝花费的时间为:"+ (end-start));
return true;
}
}
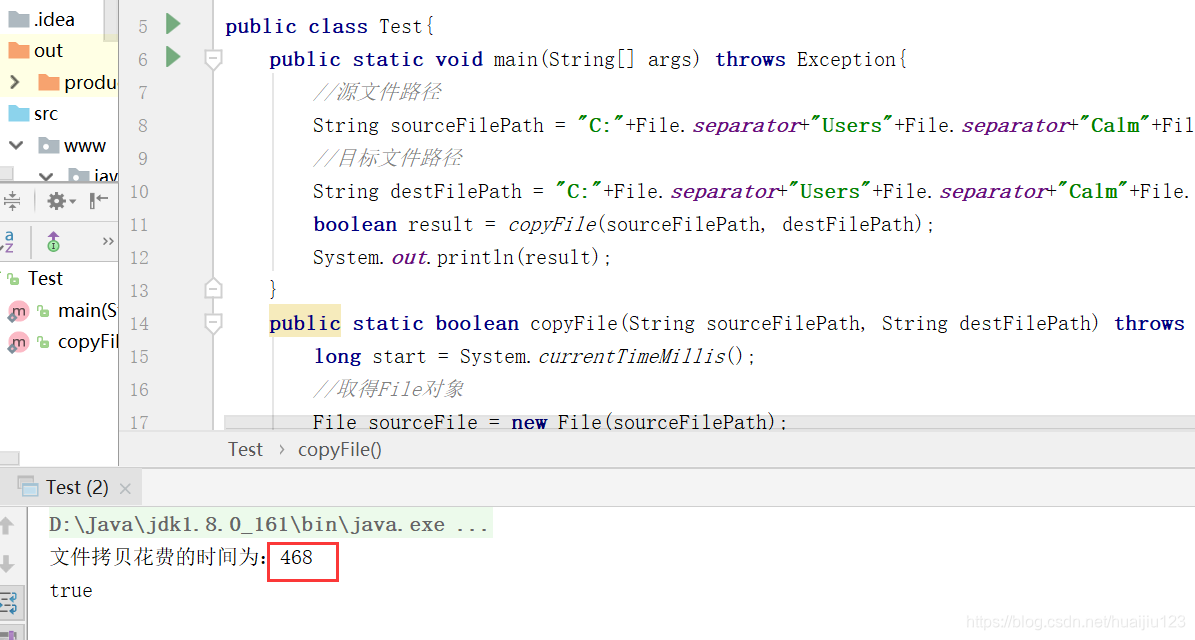
我们通过时间的对比就可以发现一次只读写一个数据用的时间比有缓冲区读写的速度慢的多。