Java虚拟机(Java virtual machine)实现了Java语言最终要得特征:即平台无关性。
平台无关性原理:编译后得Java程序(.class)文件由JVM执行。JVM屏蔽了与具体平台相关的信息,使程序可以在多种平台上不加修改的运行。JVM在执行字节码的时候,把字节码解释成具体平台上的机器指令执行。因此实现Java平台无关性。
一. JVM结构图
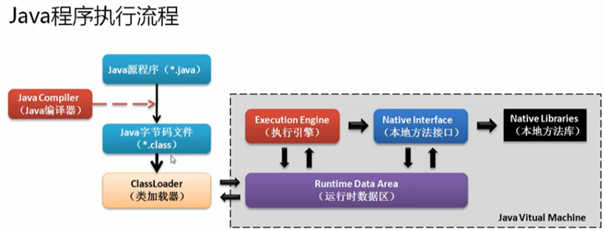
1. Java程序的执行流程
所有的Java程序代码必须保存在*.java文件中,这些称为源代码。这些源代码并不能够直接运行,必须通过javac.exe命令将它们编译成*.class文件,而后用java.exe命令在JVM进程中解释此流程。
实际上当JVM将所需要的*.class文件加载到JVM进程之中,那么这个过程就需要一个类加载器(ClassLoader)。有类加载器的好处在于:可以随意指定程序*.class文件的所在路径。
2. JVM
JVM = 类加载器 classloader+ 执行引擎 execution engine + 运行时数据区域 runtime data area
首先Java源代码文件被Java编译器编译为字节码文件,然后JVM中的类加载器加载完毕之后,交由JVM执行引擎执行。在整个程序执行过程中,JVM中的运行时数据区(内存)会用来存储程序执行期间需要用到的数据和相关信息。
JVM会提供本地方法接口和本地方法库供JAVA程序调用,前面这些都是程序运行的辅助手段,而最终程序的运行是在运行时数据区里面。
因此,在Java中我们常常说到的内存管理就是针对这段空间(运行时数据区域)进行管理(如何分配和回收内存空间)。
(1)ClassLoader
ClassLoader把硬盘上的class文件加载到JVM中的运行时数据区域,但是它不负责这个类文件能否执行,这是执行引擎负责的。
(2)执行引擎
作用就是来执行字节码,或者执行本地方法
(3)运行时数据区
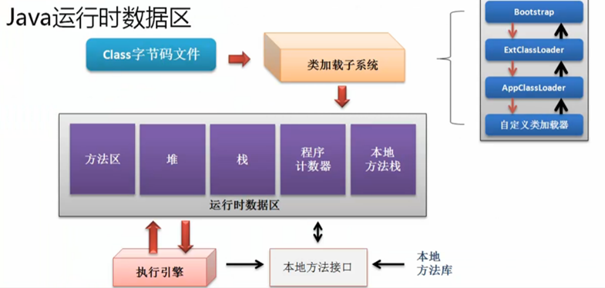
JVM在运行期间,在运行时数据区对JVM内存空间的划分和分配,划分为了一以下5个区域来处理:
1)方法区(共享区)----1.7之后放在了堆中
它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译期编译后的代码等数据;由于使用反射机制的原因,虚拟机很难推测哪个类信息不再使用,因此这块区域的回收很难!
同样当方法区无法满足内存需求时,会抛出OOM错误。
2)堆内存(共享区)
保存所有引用数据类型的真实信息。
对于大多数应用来说,Java堆是Jvm所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在jvm启动时候创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常。
3)栈内存(私有的)
(也就是虚拟机栈,或者说是虚拟机栈中局部变量表部分):局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其它与此对象相关的位置)和returnAddress类型(指向了一条字节码指令的地址)。
- JVM栈是私有的,并且生命周期与线程相同。当线程运行完毕后,相应内存也就会被自动回收。
- 栈里面存放的元素叫栈帧,每个方法从调用到执行结束,其实是对应一个栈帧的入栈和出栈。
- 这个区域可能有两种异常:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常(如:将一个函数反复递归自己,最终会出现这种异常)。如果JVM栈可以动态扩展(大部分JVM是可以的),当扩展时无法申请到足够内存则抛出OutOfMemoryError异常。
4)程序计数器(私有的)
是一个非常小的内存空间,小到可以忽略。主要是用来指向下一个将要执行的指令代码。如该线程正在执行一个Java方法,则计数器记录的是正在执行的虚拟机字节码地址,如执行native方法,则计数器值为空。比如下面“4”的提示正是它的一个表现;
1 public class Test 2 public static void main(String args[]){ 3 String str=null; 4 str.length(); 5 } 6 }
运行后,会在第4行的时候抛出空指针异常:
Exception in thread "main" java.lang.NullPointerException at Test.main(Test.java:4)
为了线程切换后能够恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各个线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
5)本地方法栈(私有的)
每一次执行递归的方法处理的时候,实际上都会将上一个方法入栈;
本地方法栈VS 虚拟机栈(栈内存):前者是为JVM使用到的Native方法服务,而后者是为JVM执行Java方法(也就是字节码)服务。本地方法栈也会抛出StackOverflowError和OutofMemoryError异常。
比如:下面就会出现栈溢出的错误:
public class Test { public static void main(String args[]) { f(); } public static void f() { f(); } }
Exception in thread "main" java.lang.StackOverflowError at mytest2.Test.f(Test.java:8) at mytest2.Test.f(Test.java:8) at mytest2.Test.f(Test.java:8) at mytest2.Test.f(Test.java:8) at mytest2.Test.f(Test.java:8) at mytest2.Test.f(Test.java:8) at mytest2.Test.f(Test.java:8) at mytest2.Test.f(Test.java:8)
方法入栈:如下图:假设方法A调用了B,方法B调用了C,方法C调用了D;首先A会入栈,然后B如栈,然后C,然后D。倘若一致程序在调用,导致栈一致在被占用,就会导致程序不能够往下继续执行了。
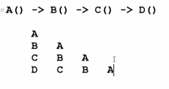
Java内存管理就是指的运行时数据区,Java只能够管理这部分。因此Java中的内存调优,实际上就是调的运行时数据区。
6)运行时常量池
- 存放类中固定的常量信息、方法引用信息等,其空间从方法区域(JDK1.7后为堆空间)中分配。
- Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有就是常量表,用于存放编译期已可知的常量,这部分内容将在类加载后进入方法区(永久代)存放。但是Java语言并不要求常量一定只有编译期预置入Class的常量表的内容才能进入方法区常量池,运行期间也可将新内容放入常量池(最典型的String.intern()方法)。
- 当常量池无法在申请到内存时会抛出OutOfMemoryError异常,上面也分析过了。
3. 堆和栈的区别
这是一个非常常见的面试题,主要从以下几个方面来回答。
(1)各司其职
最主要的区别就是栈内存用来存储局部变量和方法调用信息。
而堆内存用来存储Java中的对象。无论是成员变量、局部变量还是类变量,它们指向的对象都存储在堆内存中。
(2)空间大小
栈的内存要远远小于堆内存,如果你使用递归的话,那么你的栈很快就会充满并产生StackOverFlowError。
(3)独有还是共享
栈内存归属于线程的私有内存,每个线程都会有一个栈内存,其存储的变量只能在其所属线程中可见。
而堆内存中的对象对所有线程可见,可以被所有线程访问。
(4)异常错误
如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常。
如果JVM栈可以动态扩展(大部分JVM是可以的),当扩展时无法申请到足够内存则抛出OutOfMemoryError异常。
而堆内存没有可用的空间存储生成的对象,JVM会抛出java.lang.OutOfMemoryError。
二. JVM的分类
实际上,有三种JVM:
(1) SUN公司最早改良的HOTSPOT
(2) BEA公司的:JRockit
(3) IBM:JVM’s
而Oracle在收购了SUN和BEA公司后,得到了业内的两个虚拟机的版本。它正在试图将这两个虚拟机合并成一个虚拟机,从1.8开始,这个合并已经成功了,这是一个重要的JDK版本。
范例:取得当前的JVM版本(java -version)

所谓的混合模式(mixed mode):指的就是适合于编译和执行。
范例:使用纯解释模式启动:

范例:使用纯编译模式

HOTSPOT这个虚拟机我们是可以进行控制的,但是没有必要。实际上现在的JDK的设计都已经开始为服务器而准备的。对于JVM的启动模式分为两种:
(1)-server:服务器模式,占用的内存大,启动速度慢
(2)-client:本地单机运行程序模式,启动速度快
比如:打开JRE文件夹(安装路径),找到jvm.cfg,这个文件中有如下内容:
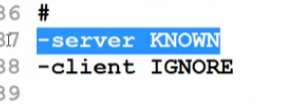
说明clent忽略了。说明JAVA默认启动方式是服务器模式了。
三. Java对象访问模式
Java的引用类型是最为重要的数据处理模型。而整个的引用数据类型处理之中会牵扯到:堆内存、栈内存、方法区。
下面以一个最简单的程序代码为主:“Object obj=new Object()”,实例化了一个Object类对象。
(1) Object obj:描述的是保存在栈内存之中,而保存有堆内存的引用,这个数据会保存在本地变量表中。(这个表中有变量名,栈,堆)
(2) New Object():一个真正的对象,对象保存在堆内存中。
直观思路整个引用的操作:
- 新定义的对象的名称保存在本地变量表,而后在这块区域需要确认要与之对应的栈内存
- 通过变量表中的栈内存地址可以找到堆内存。
- 而后利用对内存的对象进行本地方法的调用(方法区)
对于引用数据类型的访问实际上是存在两种模式的:
1. 第一种:通过句柄访问
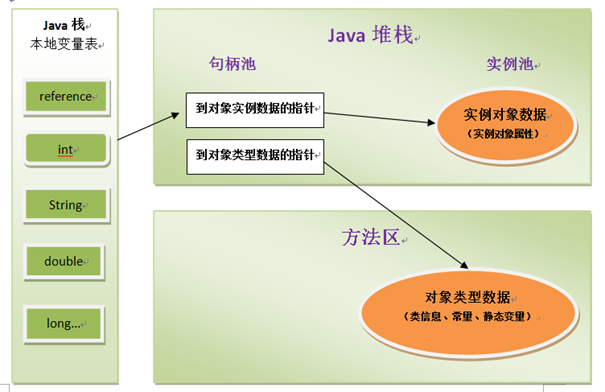
句柄:可以理解为拿着对象的关键因素的东西,我们需要通过这个关键因素去寻找对象。Java堆中将会划分出一块内存来作为句柄池,refenerce中存储的就是对象的句柄的地址,而句柄中包 含了对象实例数据与类型数据各自的具体地址信息。
优点 : 最大的好处就是reference中存储的是稳定的句柄的地址,在对象被移动(垃圾回收时移动对象是很常见的行为)时只会改变句柄中的实例数据的地址,而reference本身不需要修改。
使用:对象不是一次性找到的。需要通过句柄先找到对象实例数据,然后需要通过句柄找到对象类型数据。整个过程很麻烦。确保对象的真实存在。(也就是说,先要通过句柄找到对象在哪,然后通过句柄找到类型信息,最后找到操作符方法)
2. 第二种:通过直接指针访问(对象的保存模式)
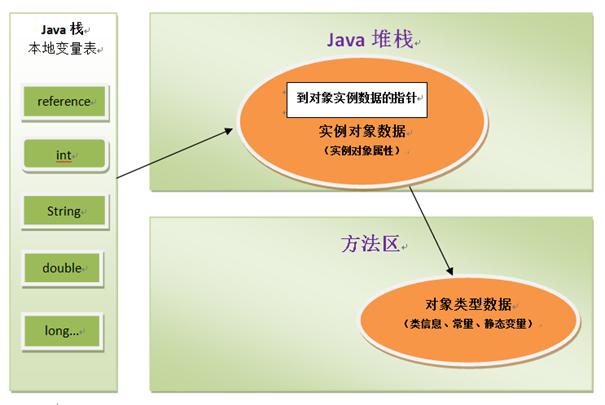
定义 : reference中存储直接对象的地址,但是必须考虑放置访问类型数据的相关信息
优点 : 访问速度快,节省了一次指针定位的时间开销,省略了句柄到对象的查找。
参考文献:
https://blog.csdn.net/SEU_Calvin/article/details/51404589
《深入理解JAVA虚拟机》
李兴华老师的《Java内存模型》