当使用回溯搜索解决CSP时,必须对要分支或实例化的变量以及要给该变量的值做出一系列决策。这些决策称为变量和值排序。已有研究表明,对于许多问题,变量的选择和值的排序对于有效解决问题是至关重要的(如[5,50,55,63])。
变量或值排序可以是静态的(排序在搜索之前是固定的并确定),也可以是动态的(排序在搜索过程中确定)。动态变量排序在文献中得到了广泛的关注。它们早在1965年就提出了[57],现在已经很好地理解了如何将动态排序合并到任意树搜索算法[5]中。
在给定CSP和回溯搜索算法的情况下,如果在找到一个解决方案或表明不存在解决方案时,变量或值排序的搜索结果在所有可能的排序中访问的节点数最少,则称变量或值排序是最优的。(请注意,我也可以使用其他一些抽象度量,例如在每个节点上完成的工作量,而不是访问的节点,但这不会改变基本结果。)毫不奇怪,寻找最优排序是一项计算上困难的任务。Liberatore[87]表明,简单地判断一个变量是否是最优变量排序中的第一个变量,至少与判断CSP是否有解决方案一样困难。寻找最优值排序显然也同样困难,因为如果存在解决方案,可以使用最优值排序来有效地找到解决方案。对于如何找到最优排序或如何构造多项式时间逼近算法——这些算法返回的排序保证接近最优(参见[70,85]),人们知之甚少。约束规划领域目前主要集中在没有形式化保证的启发式上。
启发式既可以是独立于应用程序的(只使用所有csp共同的通用特性),也可以是依赖于应用程序的。在这个调查中,我主要关注独立于应用程序的启发式。这种启发式方法已经非常成功,可以为新应用程序设计启发式提供一个良好的起点。我给出的启发式没有指定在使用tie时选择哪个变量或值,结果取决于实现。这些启发式通常可以通过添加额外的打破关系的特性来显著改进。然而,并没有一种最佳的变量或值排序启发式算法,在这些独立于应用程序的启发式算法不能很好地工作的情况下,仍然存在一些问题,必须设计一种新的启发式算法。
由于要设计一种新的启发式,因此出现了几种备选方案。当然,启发式既可以使用独立于应用程序的特性(请参阅[36]以获得构建启发式所需的许多特性的摘要),也可以使用依赖于应用程序的特性。smith和Cheng[122]举例说明,在对作业车间调度、CSP模型和搜索算法有深入了解的情况下,如何设计一种有效的启发式作业车间调度算法。然而,这种专业知识的结合可能是稀缺的。人为制作启发式的替代方法是自动适应或学习启发式。明顿[98]提出了一种系统,它能自动地从一个库到一个应用程序用启发式将泛型变量和值排序。Epstein et al.[36]提出了一个系统,该系统从应用程序以前的问题搜索经验中学习变量和值排序启发式。启发式是由一组丰富的基本特征组合而成的。Bain, Thornton和Sattar[6]展示了如何使用进化算法学习用于优化问题的变量排序启发式。
最后一种选择是,对于一个问题,如果只能发现相对较弱的启发式,那么已经证明,随机化和重新启动的技术可以提高问题解决的性能(见4.7节)。Cicirello和Smith[27]讨论了在启发式中添加随机化的替代方法以及对搜索效率的影响。Hulubei和O’sullivan[70]研究了变量的强度与值序启发式和重新启动需求之间的关系。
4.6.1 Variable Ordering Heuristics
假设回溯搜索试图扩展节点p。变量排序启发式的任务是选择下一个要分支的变量x。文献中提出并评价了许多变序启发式算法。这些启发式可以分为两类:一类是主要基于变量的域大小的启发式,另一类是基于CSP的结构的启发式。
Variable ordering heuristics based on domain size
当使用回溯搜索和约束传播交叉求解CSP时,使用约束和当前的分支约束集对未分配变量的域进行修剪。许多最重要的变量排序启发式都基于未分配变量的当前域大小。

Golomb和Baumert[57]是第一个提出动态排序启发式算法的人,该算法基于选择在其域中剩余值最少的变量。启发式(以下简称dom)是选择最小化的变量x,rem(x| p), 其中x在所有未赋值变量上取值。当然,无论在搜索过程中执行何种级别的约束传播,启发式都是有意义的。如果算法不执行约束传播,只检查实例化了所有变量的约束,则定义rem(x | p)只包含满足所有相关约束的值。由于我们的回溯搜索算法执行的是约束传播,在实际应用中会是这样,因此可以非常有效地计算dom启发式。dom启发式是由Haralick和Elliott[63]推广开来的,他们证明了dom与forward check算法的有效结合。
为了理解这种简单而有效的启发式,人们付出了大量的努力。有趣的是,Golomb和Baumert[57]在首次提出dom时,从信息理论的角度说明,平均而言,选择域大小最小的变量效率更高,但没有进一步的阐述。Haralick和Elliott[63]分析表明,dom假设CSP的概率模型过于简单,并且假设我们使用正向检查算法搜索所有的解决方案,从而使搜索树的深度最小化。Nudel[105]表明,dom是最优的(它最小化了搜索树中的节点数量),再次假设了正向检查,但使用了稍微精细化的概率模型。Gentetal[52]提出了一种名为kappa的度量方法,其目的是捕捉“约束”,以及首先选择约束最大的变量意味着什么。它们表明dom(和dom+deg,见下文)可以看作是该度量的近似。
Hooker[66]在一篇有影响力的论文中主张通过建立经验模型来支持或反驳启发式背后的直觉,从而对启发式进行科学检验,而不是竞争性检验。Hooker和Vinay[67]将该方法应用于SAT的变量顺序启发式jerolow - wang启发式的研究。令人惊讶的是,他们发现标准的直觉——“(启发式)在创建更容易满足的子问题时表现得更好”——被驳斥了,而一种新发展的直觉——“(启发式)在创建更简单的子问题时表现得更好”——得到了证实。Smith和Grant[120]将该方法应用于dom的研究。Haralick和Elliott[63]提出了一种启发式的直觉,称为“失败第一原则”:“要想成功,首先在最容易失败的地方尝试”。令人惊讶的是,史密斯和格兰特发现,如果像哈里里克和艾略特那样,将失败优先原则与最小化搜索树的深度等同起来,那么这个原则就会遭到驳斥。在后续的工作中,Beck等人发现,如果将故障优先原则等同于搜索树中节点数量最小化,就像Nadel所做的那样,那么该原则就得到了证实。Wallace[132]通过因子分析,发现了变量排序启发式导致搜索效率变化的两个基本因素:即时失效和未来失效。
除了理解dom所付出的努力之外,还有很多努力是为了改进dom。Br´elaz[20],在图着色的背景下,提出了现在广泛使用的泛化dom。设未赋值变量x的程度为包含x和至少另一个未赋值变量的约束的数量。启发式(以下简称dom+deg)是选择域中剩余值最少的变量,并通过选择最高次的变量来打破任何关系。注意,度数信息是动态的,并在实例化变量时更新。静态版本在实践中也使用,其中度信息只在搜索之前计算。
Bessi 'ere和R´egin[17]提出了另一个泛化的dom。启发式(以下简称dom/deg)是将一个变量的域大小除以该变量的度,选择值最小的变量。该启发式算法在随机问题上效果良好。Boussemart et al.[19]提出除以加权程度,后记为dom/wdeg。权重(最初设置为1)与每个约束相关联。每当约束对死端负责时,相关的权重就会增加。加权程度是包含x和至少一个未赋值变量的约束的权值之和。dom/wdeg启发式在许多问题上都能很好地工作。有趣的是,也有经验表明,弧一致性传播加上dom/deg或dom/wdeg启发式可以减少或消除对某些问题的回溯需求[17,84]。
Gent等人建议选择最小化的变量x,

其中C的取值范围包括了所有涉及x和至少一个未赋值变量的约束条件,而tC是不满足约束条件C的赋值的分数。所有这些启发式的一个限制是,随着搜索的进行,需要对每个约束C更新tC估计值。这显然代价高昂,但对于内涵表示的约束和非二进制约束也有问题。同样,乘积项隐含地假设约束失败的概率是独立的,这个假设在实践中可能不成立。
Brown和Purdom[21]建议选择最小化的变量x,

其中y在所有未赋值变量范围内。启发式背后的原理是选择变量x,它是最小的2级子树的根。Brown和Purdom表明,当随机SAT问题变大时,启发式算法比dom算法更有效。然而,启发式算法在硬SAT问题或一般csp中尚未得到全面的评价。
Geelen[49]建议选择最小化的变量x,
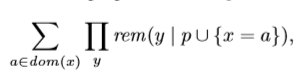
其中y在所有未赋值变量范围内。乘积项可以看作是给定x值a的解的个数的上界,启发式背后的原则是选择最“受约束”的变量。Geelen证明了当约束传播的级别是正向检验时,该启发式算法能很好地解决n-queens问题。Refalo[111]提出了一种类似的启发式算法,并证明它比基于dom的多背包和魔术方块问题启发式算法要好得多。虽然启发式的计算成本很高,但雷法洛的工作表明,在排序中选择第一个或几个变量时,它特别有用。有趣的是,Wallace[132]报告说,在随机和准群体问题上,启发式算法表现不佳。
Freeman[38],在SAT的背景下,建议选择最小化的变量x,

其中y在所有未赋值变量范围内。由于这是一种昂贵的启发式,Freeman建议在选择搜索中的前几个变量时主要使用它。启发式算法的原理是在选择变量的情况下,最大限度地增加传播量和实例化变量的数量,从而简化维护问题。Freeman指出,当约束传播的级别是单位传播(相当于前向检查)时,启发式算法可以很好地解决硬SAT问题,尽管计算成本很高。Malik等[91]表明,截断版本(仅使用dom(x)中的第一个元素)在指令调度问题上非常有效。
Structure-guided variable ordering heuristics
CSP可以用图形表示。这种图形化表示构成了结构导向的变量排序启发式的基础。真正的问题往往包含很多的结构,在这些问题上,结构导向的启发式的优点包括,结构参数可以用来约束回溯算法的最坏情况,结构good和nogood可以被记录下来,并用于修剪搜索空间的大部分。不幸的是,这些启发式目前的一个局限性是,它们在存在全局约束的情况下会崩溃,这在实践中是很常见的。另一个缺点是,一些结构引导的启发式要么是静态的,要么几乎是静态的。
Freuder [40]可能是第一个提出结构引导变量排序启发式的人。 考虑约束图,其中CSP中的每个变量都有一个顶点,如果存在约束C,则两个顶点x和y之间存在边,使得x∈vars(C)和y∈vars(C)。

Definition 4.9 (width). 让约束图中的顶点排序。排序的宽度是排序中从任意顶点v到v之前的顶点的最大边数。约束图的宽度是该图所有排序的最小宽度。
考虑与图中顶点的排序相对应的静态变量排序。Freuder[40]表明,如果强k一致性级别大于排序的宽度,那么静态变量排序是无回溯的。显然,这样的变量排序在优化排序的O(d)因子内,其中d是域的大小。Freuder[40]还表明,如果强一致性级别大于约束图的宽度,则存在无回溯静态变量排序。Freuder[41]将这些结果推广到静态变量排序中,该排序保证了搜索中访问的节点数可以预先有界。
Dechter和Pearl[35]提出了一个变量排序,它首先实例化了在约束图中切割循环的变量。一旦所有的循环被切断,约束图是一个树,可以使用圆弧一致性[40]快速求解。Sabin和Freuder[117]在保持arc一致性的算法中对该方案进行了改进和测试。他们表明,在随机二进制问题上,可变排序的循环削减可以优于dom+deg。
Zabih [136]建议选择width较小的静态变量排序。 让约束图中的n个顶点按1,...,n排序。排序的带宽是排序中由一条边连接的任意两个顶点之间的最大距离。约束图的带宽是该图所有顺序上的最小带宽。直观地说,一个小的带宽排序将确保导致失败的变量将被关闭,从而减少对回跳的需要。然而,目前很少有实证证据表明这是一种有效的启发式方法。
在图的算法设计中,一个著名的技术是使用图分隔符进行分治。

定义4.10(分隔符)。图的分隔符是顶点或边的子集,当这些顶点或边被移除时,这些边将图分离成不相交的子图。
一个图可以递归地分解,通过连续地找到结果不相交子图的分隔符。弗瑞德和奎恩·[42]提出了一个基于这种曲线分解的变量排序算法。其思想是,分隔符(在[42]中称为割集)提供一组变量,一旦实例化,这些变量将分解CSP。Freuder和Quinn还提出了一种特殊目的的回溯算法,在求解独立问题时,可以正确地使用变量排序的加法行为,而不是乘法行为。Huang和Darwiche[69]表明不需要特殊目的回溯算法;我们可以只使用CBJ。因为分隔符是在搜索之前找到的,所以在执行回溯搜索期间,预先建立的变量组不会更改。然而,Huang和Darwiche注意到,在这些分组中,变量排序可以是动态的,并且可以使用任何现有的变量排序启发式。Li和van Beek[86]对这种分而治之的方法提出了一些改进。到目前为止,分而治之的方法已经被证明对SAT难题是有效的[69,86],但是对于一般CSP问题的方法还没有系统的评价。
Moskewicz等[103]在SAT的Chaff求解器中提出,作为最后两种结构导向的启发式方法,变量的选择应该偏向于近期记录的nogoods中出现的变量。J´egou和Terrioux[73]使用tree-decomposition约束图指导变量的排序。
4.6.2 Value Ordering Heuristics
假设回溯搜索试图扩展节点p,而变量排序启发式选择了变量x作为下一个分支。值排序启发式的任务是为x选择下一个值a。许多值排序启发式的设计原则是选择下一个最有可能成功或成为解决方案一部分的值。现有的值排序启发法,往往基于估计解的数量或估计解的概率,对于x的每个值a的选择。 显然,如果我们确切地知道这些属性中的任何一个,那么也可以知道完美的值排序 - 只需选择一个导致解决方案的值并避免不会导致解决方案的值。
Dechter和Pearl[35]提出了一种基于近似每个子问题的解个数的静态值排序启发式。通过对问题形成树松弛,得到解的个数的近似,在树松弛中,约束条件被删除,直到CSP的约束图可以表示为树为止。计算树结构CSP的所有解是多项式的,因此可以精确计算。然后,通过减少对解决方案计数的估计,对这些值进行排序。后续工作[76,94,131]集中于推广动态值排序的方法,并利用贝叶斯网络的最新思想改进解决方案数量的近似(树松弛可以提供对真实解决方案计数的糟糕估计)。这部分工作的一个限制是,当它比较解决方案的数量时,它没有考虑被分支到的子树的大小,也没有考虑搜索子树的困难和成本。
Ginsbergetal [55],在使用填字游戏作为试验台的实验中,提出了以下动态值排序启发式算法。 要实例化x,请选择值a∈dom(x),以最大化剩余域大小的乘积,

其中y的范围包括所有未分配的变量。Ginsberg等人证明了当约束传播的级别是正向检验时,启发式算法在纵横字谜游戏中工作良好。Geelen[49]为这种启发式的有效性提供了进一步的经验证据。Geelen注意到,乘积给出了节点p可能完成的数量,这些完成可以通过两种方式查看。首先,假设每一次完成都有可能是一个解,选择使乘积最大化的值也会使我们分支到包含一个解的子问题的概率最大化。其次,补全可以看作是子问题解的个数的上界。Frost和Dechter[46]建议选择使其余域大小之和最大化的值。然而,Geelen[49]注意到,乘积的微分要比求和好得多。在文献中,产品启发式有时被称为“承诺启发式”,而总和启发式有时被称为“最小冲突启发式”,其灵感来源于明顿等人提出的同名局部搜索启发式[99]。