前言:
理解正则, 大致从这几个方面
[ 1: 创建形式 2: 元字符和转义字符 3: 数词量词 4: 分组 5: 修饰符 6: 附加功能 ]
一、创建形式
// case 1: var reg1 = /a/g; // case 2: var reg2 = new RegExp(/a/g); // case 3: let reg3 = new RegExp(/a/,'g'); // es6专用
二、元字符和转义字符 (如果为了理解看本文请不要去记这些琐碎的固定知识点)
.................元字符.................
\t => tab 水平制表符
\v => 垂直制表符 (不太清除干嘛用的, 有研究的朋友可以回复下~)
\n => 换行
\r => 回车换行符 (不太请拿出\r\n的区别, 只知道linux和windows下有些差异, 并且\r是相当于敲了了个回车, \n还记得html中中肿么用的嘛~)
\0 => 空字符 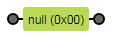
\f => 换页 (没用到过)
\cx =>对应ctrl+x (没用到过)
.................常见转义字符.................

三、数词量词
正则的使用经常伴随着如下模式 / (数词)(量词) / (修饰) 如 var reg = /a{5}/gi;
.................数词.................
case 预定义类型:
\w => 匹配字母或数字或下划线或汉字 等价于 '[^A-Za-z0-9_]'。
\s => 空格
\d => [0-9]
\u{xxxx} => 直接键入unicode编码
case 非预定义类型:
/avenda/ => 对应avenda单词
/1234/ => 对应1234
/\.\\\?\-/ => 对应.\?-
case 类对象 (占一个位置, 内部为所有满足条件的条件):
[\dabc] => 数字或者abc
case 非与或:
(1 | 2 | 3) => 1或2或3 等同于[123] //'或'一般结合分组使用
[^\d] =>非数字 // '非'一般用于类对象中, 如果不是在类对象中则表示以xx开始
case 条件断言(跟在一个正则单元后面判断是否满足条件):
(?= xxx) 例: 'AvendaAvenda2333'.replace(/avenda(?=\d)/ig,'X') 这里是把后面为数字的avenda替换为X字母, i修饰符为忽略大小写
.................量词.................
量词表达出现的数量, 跟在量词后面做循环判定
? => 最多1次 例: /a?/ 最多出现一次a或者没有
+ => 最少1次 例: /a+/ 至少出现1次
* => 任意次数 例: /a*/
{n} 出现n次 例: /a{3}/出现3次
{n, m} 出现n到m次 例: /a{2,3}/出现2或3次
{n, } 至少出现n次 例: /a{2,}/至少出现2次
{0, n} 最多出现n此 例: /a{0,3}/最多出现3次
四、分组 ( '(xxx)' )
为什么要用分组?
一个例子
let reg = /(^|&)age=([^&]*)($|&)/;
reg.exec('name=avenda&age=15');
结果: