单个字符:

数量词:

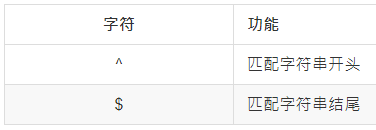
匹配开头、结尾:
匹配分组:


demo.py(正则表达式,match从开头匹配,分组,分组别名):
# coding=utf-8
import re
# 小括号()表示分组 \1表示取出第一个分组中匹配的字符串。
ret = re.match(r"<(\w*)><(\w*)>.*</\2></\1>", "<html><h1>www.baidu.cn</h1></html>") # 正则前的r表示原生字符串,取消字符串中反斜杠\的默认转义作用。
if ret:
print("符合要求....匹配成功的整个字符串是:%s" % ret.group()) # <html><h1>www.baidu.cn</h1></html>
print("第一个分组:%s" % ret.group(1)) # 第一个分组就是第一个小括号()中匹配的字符串。 html
print("第二个分组:%s" % ret.group(2)) # h1
else:
print("不符合要求....")
# ######################################################
# 分组取别名
ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.baidu.cn</h1></html>")
if ret:
print("符合要求....匹配成功的整个字符串是:%s" % ret.group())
print("第一个分组:%s" % ret.group(1)) # 第一个分组就是第一个小括号()中匹配的字符串。
print("第二个分组:%s" % ret.group(2))
else:
print("不符合要求....")