一、工具安装
- 访问官网https://www.elastic.co/downloads/elasticsearch和http://xbib.org/repository/org/xbib/elasticsearch/importer/elasticsearch-jdbc下载版本匹配的es和es-jdbc。如果数据库使用的非MySQL,还需要将相应版本的数据库驱动拷贝到elasticsearch-jdbc的lib下;
- 访问https://github.com/mobz/elasticsearch-head下载es-head插件,即es的控制台。解压后放在elasticsearch\plugins\下新建的head文件夹中,启动es后访问http://localhost:9200/_plugin/head/即可查看控制台界面,在控制台可以查看集群、节点,创建、查看索引,进行数据查询等等;
- 访问https://github.com/medcl/elasticsearch-analysis-ik下载ik分词插件(1.9.4的ik和2.3.4的es匹配,其他版本可参考https://blog.csdn.net/songjinbin/article/details/50781522查看),安装方式同上,新建ik文件夹即可。
二.使用步骤
A. 编写脚本,同步数据并创建索引
- Windows下进入elasticsearch-jdbc/bin新建.bat文件(Linux下为.sh文件),命名无要求。配置elasticsearch.cluster-集群名、host-ip地址、port-端口号;
- 配置statefile-脚本输出文件,schedule-定时刷新时间;
- 配置数据库连接属性、sql语句。sql必须为动态,根据metrics.lastexecutionstart-脚本执行时间和updatetime-数据库时间字段来定时刷入新增和修改的数据(增量同步):
"statement" : "select * from table where updatetime > ?",^
"parameter" : ["$metrics.lastexecutionstart"]^
*这是增量同步的一种方式,当需要同步的数据较多需要写多条sql时,建议使用存储过程做增量同步,可参考A-7的同步脚本和存储过程示例;
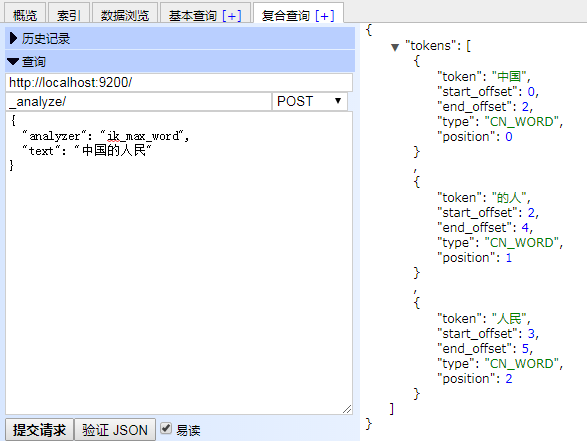
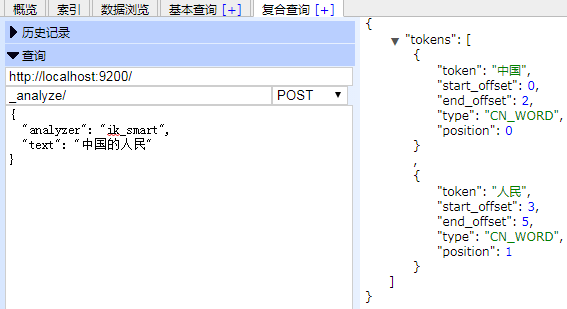
4. ik分词器的使用。ik分词器分为两种分词方法,一种是最大切分,一种是全切分,对应的名字为ik_smart,ik_max_word,分词效果可参考图1图2;
图一:
图二:
5. 其它一些配置。
"term_vector":可获取document中的某个field内的各个term的统计信息,从而对词条进行过滤筛选;
"copy_to":可以自由把一个索引下的一个或以上的字段值复制到另外的一个字段中,在需要查询多个字段时设置一个字段即可;
6. 生成和配置索引、映射、字段可参考如下的生成索引示例。索引相关配置可参考http://www.cnblogs.com/chenmc/p/9516100.html,需要注意的是sql语句中字段名和索引下字段名的一致性;
{ "settings": { "index": { "analysis": { "analyzer": { "ik": { "tokenizer": "ik" } } } } }, "mappings": { "userInfo": { "properties": { "userName": { "type": "string", "analyzer": "ik_smart", "copy_to": "_mixField", "term_vector": "with_positions_offsets" }, "teamName": { "type": "string", "analyzer": "ik_smart", "copy_to": "_mixField", "term_vector": "with_positions_offsets" }, "updateTime": { "type": "string", "index": "not_analyzed", "include_in_all": false } }, "_mixField": { "type": "string", "analyzer": "ik_smart", "term_vector": "with_positions_offsets" } }, "menu": { "properties": { "menuName": { "type": "string", "analyzer": "ik_smart", "copy_to": "_mixField", "term_vector": "with_positions_offsets" }, "updateTime": { "type": "string", "index": "not_analyzed", "include_in_all": false }, "_mixField": { "type": "string", "analyzer": "ik_smart", "term_vector": "with_positions_offsets" } } } } }
7. 同步脚本及其使用的oracle存储过程示例。在实际的应用中,在脚本中通过写多条sql同步多表数据时很难做到增量同步,一般使用如下方法。
@echo off title oracle_to_es set DIR=%~dp0 set LIB=%DIR%..\..\lib\* set BIN=%DIR%..\..\bin echo {^ "type" : "jdbc",^ "jdbc" : {^ "statefile" : "ar01.json",^ "schedule" : "0 0-59 0-23 ? * *",^ "url" : "jdbc:oracle:thin:@192.168.1.117:1521/orcl",^ "user" : "projectmanage",^ "password" : "123456",^ "sql" : [{^ "callable" : true,^ "statement" : "{call es_syncinfo(?,?)}",^ "parameter" : ["001"],^ "register" : {"myOracleProcedureResult" : {"pos" : 2, "type" :"cursor" }}^ }],^ "elasticsearch.cluster":"elasticsearch",^ "elasticsearch" : {^ "host" : "localhost",^ "port" : 9300^ },^ "index" : "myindex",^ "type" : "userInfo"^ }^ }^ | "%JAVA_HOME%\bin\java" -cp "%LIB%" -Dlog4j.configurationFile="%BIN%\log4j2.xml" "org.xbib.tools.Runner" "org.xbib.tools.JDBCImporter"
-- Create table create table T_RT_SYNCINFO ( syncid VARCHAR2(10) not null, indexname VARCHAR2(256), typename VARCHAR2(256), syncsql VARCHAR2(4000), syncsql2 VARCHAR2(4000), lasttimesql VARCHAR2(4000), synctime DATE not null, syncdesc VARCHAR2(1024), isvalid NUMBER(1) ) -- Add comments to the columns comment on column T_RT_SYNCINFO.syncid is '同步id'; comment on column T_RT_SYNCINFO.indexname is '索引名'; comment on column T_RT_SYNCINFO.typename is '类型名'; comment on column T_RT_SYNCINFO.syncsql is '同步sql'; comment on column T_RT_SYNCINFO.syncsql2 is '同步sql2'; comment on column T_RT_SYNCINFO.lasttimesql is '最后一条更新时间sql'; comment on column T_RT_SYNCINFO.synctime is '同步时间'; comment on column T_RT_SYNCINFO.syncdesc is '描述'; comment on column T_RT_SYNCINFO.isvalid is '是否有效(0:有效;1:无效)'; CREATE OR REPLACE PROCEDURE es_syncinfo ( i_syncid in varchar2, --同步id o_result out sys_refcursor --返回码(0成功, 1失败) ) IS v_syncsql VARCHAR2(8000); v_synctime T_RT_SYNCINFO.synctime%type; v_lasttimesql T_RT_SYNCINFO.lasttimesql%type; v_lasttime date; v_ErrCode VARCHAR2(100); v_ErrMsg VARCHAR2(200); BEGIN BEGIN --查询同步时间和同步sql SELECT t.SYNCTIME, t.SYNCSQL||t.SYNCSQL2, t.LASTTIMESQL into v_synctime, v_syncsql, v_lasttimesql FROM T_RT_SYNCINFO t WHERE t.SYNCID = i_syncid AND t.isvalid = 0; EXCEPTION WHEN NO_DATA_FOUND THEN OPEN o_result FOR 'SELECT 1 from dual WHERE 1 = 2'; return; END; IF v_syncsql IS NOT NULL AND v_lasttimesql IS NOT NULL THEN BEGIN v_lasttimesql := REPLACE(v_lasttimesql, '?' , 'to_date(''' || to_char(v_synctime, 'yyyy/mm/dd hh24:mi:ss') || ''', ''yyyy/mm/dd hh24:mi:ss'')'); EXECUTE IMMEDIATE v_lasttimesql INTO v_lasttime; EXCEPTION WHEN NO_DATA_FOUND THEN OPEN o_result FOR 'SELECT 1 from dual WHERE 1 = 2'; return; END; IF v_lasttimesql IS NOT NULL THEN --增量查询所有待同步数据 v_syncsql := REPLACE(v_syncsql, '?' , 'to_date(''' || to_char(v_synctime, 'yyyy/mm/dd hh24:mi:ss') || ''', ''yyyy/mm/dd hh24:mi:ss'')'); OPEN o_result FOR v_syncsql; --更新同步时间 UPDATE T_RT_SYNCINFO t SET t.SYNCTIME = v_lasttime WHERE t.SYNCID = i_syncid; COMMIT; END IF; END IF; EXCEPTION WHEN OTHERS THEN ROLLBACK; OPEN o_result FOR 'SELECT 1 from dual WHERE 1 = 2'; v_ErrCode := SQLCODE; v_ErrMsg := SUBSTRB(SQLERRM, 1, 200); DBMS_OUTPUT.PUT_LINE(v_ErrCode||':'||v_ErrMsg); RAISE; END es_syncinfo;
B. 运行搜索引擎
- 进入elasticsearch/bin下,运行cmd,输入elasticsearch启动es,如果配置了head插件和ik,都会随之启动,可以在启动信息中查看;
- 在es启动成功后(数据库服务也要保持开启状态),进入elasticsearch-jdbc/bin下,执行上一步中配置好的.bat脚本;
- 如果安装了head插件,等脚本执行完毕后,可以在控制台页面看到生成的索引、索引类型以及同步的数据。
C. Java操作es-api查询
1. 添加对应版本的es依赖或者jar包,如果版本不一致,会导致无法连接到es;
2. 连接es的java代码如下所示,需要注意的是在es2.X之后的版本,在连接上有很大的区别,在此不再叙述。在下面的代码中把CLUSTER_NAME,IP,PORT换成自己的即可;
Settings settings = Settings.settingsBuilder() .put("cluster.name", CLUSTER_NAME) .build(); Client client = new TransportClient.Builder().settings(settings).build() .addTransportAddress(new InetSocketTransportAddress (new InetSocketAddress(IP, PORT)));
3. 在执行查询时,主要是使用QueryBuilders核心查询对象,通过该对象可以设置使用es的多种查询方式,详情可参https://blog.csdn.net/alan_liuyue/article/details/78354630;
4. 查询后使用client.close();关闭连接资源;
5. 查询示例。
package com.example.demo.controller; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.Client; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.transport.InetSocketTransportAddress; import org.elasticsearch.index.query.QueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import java.net.InetSocketAddress; import java.util.Iterator; public class ElasticSearch { //连接使用的常量 public static final String CLUSTER_NAME = "elasticsearch"; private static final String IP = "localhost"; private static final int PORT = 9300; //执行查询 public static void main(String[] args) throws Exception { //1.设置要连接的es集群 //2.设置client.transport.sniff为true来使客户端去嗅探整个集群的状态,把集群中其它机器的ip地址自动加到客户端中 //(上述设置需要开启es的远程访问) //(当ES服务器监听(publish_address)使用内网服务器IP,而访问(bound_addresses)使用外网IP时,不要设置) Settings settings = Settings.settingsBuilder() .put("cluster.name", CLUSTER_NAME) .put("client.transport.sniff", true) .build(); //使用上述配置连接es端 Client client = new TransportClient.Builder().settings(settings).build() .addTransportAddress(new InetSocketTransportAddress (new InetSocketAddress(IP, PORT))); //执行查询,其中QueryBuilders(QueryBuilder)是核心查询对象,可设置查询方式和内容 //matchQuery用于文本类型字段的搜索 //boolQuery用于基于条件的组合查询 /* QueryBuilder queryBuilder01 = QueryBuilders.matchQuery("name", "小小"); QueryBuilder queryBuilder02 = QueryBuilders.matchQuery("name", "大"); QueryBuilder queryBuilder03 = QueryBuilders.boolQuery().must(queryBuilder01).mustNot(queryBuilder02);*/ QueryBuilder queryBuilder04 = QueryBuilders.multiMatchQuery("中华的人民", "name", "teamName", "menuName"); SearchResponse searchResponse = client.prepareSearch("myindex").setTypes("userInfo", "menu") .setQuery(queryBuilder04) .get(); //获得查询出的值 SearchHits hits = searchResponse.getHits(); if (hits.totalHits() > 0) { Iterator<SearchHit> iterator = hits.iterator(); while (iterator.hasNext()) { SearchHit next = iterator.next(); System.out.println("查询到:" + next.getSourceAsString() + ",该项匹配度为" + next.getScore()); } } else { System.out.println("没有可匹配的结果。"); } //关闭连接 client.close(); } }
D. 注意事项
1) 默认情况下,elasticsearch只允许本机访问(localhost),如果需要远程访问,可以到config/elasticsearch.yml文件去掉network.host的注释,将它的值改成0.0.0.0,然后重新启动elasticsearch。设置固定ip访问同理;
2) Elasticsearch本身不支持通过存储过程进行数据同步,需要对其进行修改。使用存储过程时,需要注册返回对象来接受查询的结果集,即脚本中的"register" : {"myOracleProcedureResult" : {"pos" : 2, "type" :"cursor" }}^;
3) Elasticsearch无法同步被物理删除的数据,建议在需要同步的数据表中加入删除字段,并在同步sql中加入判断条件进行筛选以保证数据同步性;
4) *索引名称必须小写;
5) elasticsearch自带_all字段,它是所有字段的拼接,如果全字段查询中完全不需要分词,需要对它进行设置"index" : "not_analyzed",对每个字段进行设置是无效的。同理,_all字段默认使用es自带分词器,如需使用其他分词器也要进行单独配置;
6) 拼音分词器:https://github.com/medcl/elasticsearch-analysis-pinyin可以对汉语拼音进行分词,如有需要可以使用。
这次就到这里了,接下来是Elasticsearch在服务器上的部署介绍,敬请期待!