这个问题花费了我将近两天的时间,经过多次是错和尝试,现在想分享给大家来解决此问题避免大家入坑,以前都是在局域网上搭建的hadoop集群,并且是局域网访问的,没遇见此问题。
因为阿里云上搭建的hadoop集群,需要配置映射集群经过内网访问,也就是局域网的ip地址。
如果配置为公网IP地址,就会出现集群启动不了,namenode和secondarynamenode启动不了,如果将主机的映射文件配置为内网IP集群就可以正常启动了。但通过eclipse开发工具访问
会出错,显示了阿里云内网的ip地址来访问datanode,这肯定访问不了啊,这问题真实醉了,就这样想了找了好久一致没有思路。
最终发现需要在hdfs-site.xml中修改配置项dfs.client.use.datanode.hostname设置为true,就是说客户端访问datanode的时候是通过主机域名访问,就不会出现通过内网IP来访问了
最初查看日志发现:
一、查看日志
1. less hadoop-hadoop-namenode-master.log

2.less hadoop-hadoop-secondarynamenode-master.log

二、解决集群访问问题
1.查看hosts映射文件

上面是公网IP需要替换为内网IP

然后正常搭建hadoop集群
2.core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/BigData/hadoop-2.7.3/data</value>
</property>
3.hadoop-env.sh 修改export JAVA_HOME值
export JAVA_HOME=/home/hadoop/BigData/jdk1.8
4.hdfs-site.xml 注意:添加一个dfs.client.use.datanode.hostname配置
<!-- 指定namenode的http通信地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- 如果是通过公网IP访问阿里云上内网搭建的集群 -->
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
<description>only cofig in clients</description>
</property>
5.mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- jobhistory的address -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- jobhistory的webapp.address -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
6. yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
7.hadoop namenode -format格式化,然后启动start-all.sh
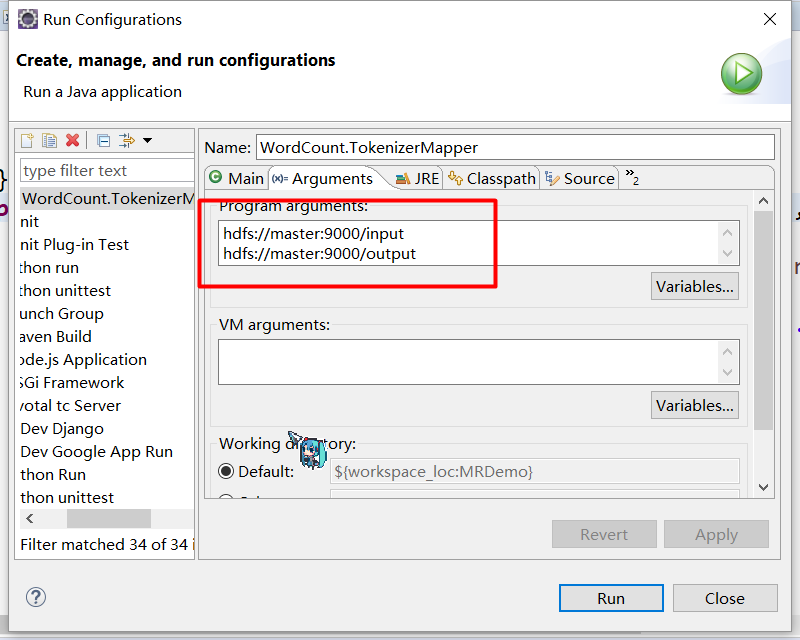
8.在本地IDE环境中编写单词统计测试集群访问
public class WordCount {
public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text,IntWritable>{
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int sum = 0;
for(IntWritable item:values) {
sum += item.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>....] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length -1; i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileSystem fs = FileSystem.get(conf);
Path output = new Path(otherArgs[otherArgs.length - 1]);
if(fs.exists(output)) {
fs.delete(output, true);
System.out.println("output directory existed! deleted!");
}
FileOutputFormat.setOutputPath(job, output);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
}
9.运行的时候配置一个数据的存放路径和数据的输出路径位置