版权声明:本文为博主原创文章,转载请附上博文链接! https://blog.csdn.net/weixin_38314865/article/details/84638178
方法来自机器之心公众号
首先下载mnist数据集,并将里面四个文件夹解压出来,下载方法见前面的博客
import tensorflow as tf
import numpy as np
import os
dataset_path = r'D:\PycharmProjects\tensorflow\MNIST_data' # 这是我存放mnist数据集的位置
is_training = True
# 定义加载mnist的函数
def load_mnist(path, is_training):
# trX将加载储存所有60000张灰度图
fd = open(os.path.join(path, 'train-images.idx3-ubyte'))
loaded = np.fromfile(file=fd, dtype=np.uint8)
trX = loaded[16:].reshape((60000, 28, 28, 1)).astype(np.float)
fd = open(os.path.join(path, 'train-labels.idx1-ubyte'))
loaded = np.fromfile(file=fd, dtype=np.uint8)
trY = loaded[8:].reshape((60000)).astype(np.float)
#teX将储存所有一万张测试用的图片
fd = open(os.path.join(path, 't10k-images.idx3-ubyte'))
loaded = np.fromfile(file=fd, dtype=np.uint8)
teX = loaded[16:].reshape((10000, 28, 28, 1)).astype(np.float)
fd = open(os.path.join(path, 't10k-labels.idx1-ubyte'))
loaded = np.fromfile(file=fd, dtype=np.uint8)
teY = loaded[8:].reshape((10000)).astype(np.float)
# 将所有训练图片表示为一个4维张量 [60000, 28, 28, 1],其中每个像素值缩放到0和1之间
trX = tf.convert_to_tensor(trX / 255., tf.float32)
# one hot编码为 [num_samples, 10]
trY = tf.one_hot(trY, depth=10, axis=1, dtype=tf.float32)
teY = tf.one_hot(teY, depth=10, axis=1, dtype=tf.float32)
# 训练和测试时返回不同的数据
if is_training:
return trX, trY
else:
return teX / 255., teY
def get_batch_data():
trX, trY = load_mnist(dataset_path, True)
# 每次产生一个切片,每次从一个tensor列表中按顺序或者随机抽取出一个tensor放入文件名队列
data_queues = tf.train.slice_input_producer([trX, trY])
# 对队列中的样本进行乱序处理
X, Y = tf.train.shuffle_batch(data_queues,
batch_size=batch_size,
capacity=batch_size * 64,
min_after_dequeue=batch_size * 32,
allow_smaller_final_batch=False)
return (X, Y)这里为什么要去掉训练集的前16个数字和标签的前8个数字呢?我看了一下,训练集train-images.idx3-ubyte文件确实有47040016个数字,比28*28*60000=47040000多了16个数字,训练集标签train-labels.idx1-ubyte文件下有60008个数字,也多出来8个数字,下面是mnist训练集的样本和标签的数据结构:

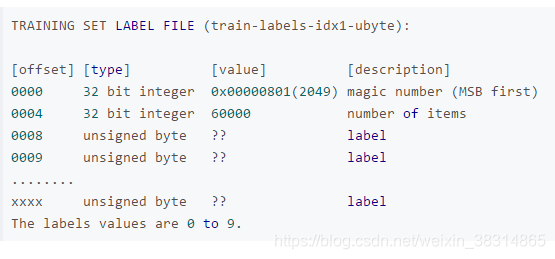
可以看出在train-images.idx3-ubyte中,第一个数为32位的整数(魔数,图片类型的数),第二个数为32位的整数(图片的个数),第三和第四个也是32为的整数(分别代表图片的行数和列数),接下来的都是一个字节的无符号数(即像素,值域为0~255)