1、概述
爬虫,应该称为网络爬虫,也叫网页蜘蛛人,网络蚂蚁等
搜索引擎,就是网络爬虫的应用者
2、爬虫分类
通用爬虫:
常见就是搜索引擎,无差别的收集数据,存储,提交关键字,构建索引库,给用户提供搜索接口
爬取一般流程:
1、初始一批URL,将这些URL放到待爬的队列
2、从队列取出这些URL,通过DNS 解析IP ,对IP 对应的站点下载HTML页面,保存到本地服务器中,爬取完URL放到已经爬取的队列中
3、分析这些网页内筒,找出网页里面的其他关心的URL连接,继续执行第二步,直到爬取条件结束。
搜索引擎如何获取一个新网站的URL
-
-
- 新网站主动提交给搜索引擎
- 通过其他网站页面的外连接
- 搜索引擎和DNS 服务商合作,获取最新收录的网站。
-
聚焦爬虫:
有针对的编写特定领域数据的爬虫程序,针对某些 类别的数据采集的爬虫,是面向主体的爬虫

3、Robots 协议:
指定一个robots.txt 文件,告诉爬虫引擎什么可以爬,什么不可以爬
/ 表示网站根目录, 表示网站的所有目录
Allow:允许, Disallow:不允许
可以使用通配符
例如:淘宝:http://www.taobao.com/robots.txt
 View Code
View Code
这是一个君子协定,爬亦有道
这个协议为了让搜索引擎更有效率的搜索自己内容,提供了如Sitemap 这样的文件
Sitemap 往往死一个XML 文件,提供了网站想让大家爬取的内容的更新信息
这个文件禁止爬取的往往又是我们可能感兴趣的内容,它反而泄露了这些地址。
4、HTTP请求和响应的处理
其实爬取网页就是通过HTTP 协议访问网页, 不过通过浏览器访问往往是认为行为,把这种行为变成程序来访问。
urllib包:
urllib 是标准库,它一个工具包模块,包含下面的模块处理 url
-
-
- urllib.request 用于打开和读写url
- urllib.error 包含了有urllib.request引起的异常。
- urllib.parse 用于解析url
- urllib.robotparser 分析robots.txt 文件
-
Python2 中提供了urlib 和urllib2 ,前者 提供了较为底层的接口,urllib2 对urllib 进行了进一步的封装,P樱桃红3中将urllib合并到饿了urllib中,并更名为标准库urllib包
urllib.request模块
模块定义了在基本和摘要式身份验证,重定向,cookies等应用中打开url(主要是HTTP)的函数和类
urlopen方法:
urlopen(url,data=None)
url 是链接地址字符串,或请求类的实例
data提交的数据,如果data为None,发起的是GET请求,否则发起POST请求,
见 urllib.request.Requset.get_method返回 http.client.HTTPResponse类的响应对象,这是一个类文件对象
1 from urllib.request import urlopen
2 from urllib import request
3
4
5 # 打开一个url返回一个响应对象,类文件对象
6 # 下面的链接,会301 跳转
7 response = urlopen('https://www.bing.com') #GET 方法
8 print(response)-----类文件对象
9 with response:
10 print(1, type(response))
11 print(2, response.status, response.reason)
12 print(3, response.geturl) 13 print(4, response.info()) 14 print(5, response.read()) 15 16 print(response.closed)
打印结果
上面,通过urllib.requset.urlopen 方法,发起一个HTTP的GET请求,web 服务器返回了网页内容,响应的数据被封装到类文件对象中,可以通过read方法,readline方法,readlines方法,获取数据,status,和reason 表示状态码, info方法表示返回header信息等
User-Agent问题
上例的代码非常精简,即可以获得网站的响应数据,但是目前urlopen方法通过url 字符串和data发起HTTP请求
如果想修改HTTP头,例如:useragent 就得借助其他方式
原码中构造的useragent 如下:
1 class OpenerDirector:
2 def __init__(self):
3 client_version = "Python-urllib/%s" % __version__
4 self.addheaders = [('User-agent', client_version)]
5 # self.handlers is retained only for backward compatibility
6 self.handlers = []
7 # manage the individual handlers
8 self.handle_open = {}
9 self.handle_error = {}
10 self.process_response = {} 11 self.process_request = {}
当前显示为 Python-urllib/3.7
有些网站是反爬虫的,所以要把爬虫伪装成浏览器,随便打开一个浏览器,复制浏览器的UA(useragent) 值,用来伪装。
Request类
Request(url, data=None, headers={} )
初始化方法,构造一个请求对象,可添加一个header的字典
data 参数决定是GET 还是POST 请求(data 为None是GET,有数据,就是POST)
add_header(key, val) 为header总增加一个键值对。
1 from urllib.request import Request, urlopen
2
3 # 打开一个url 返回一个Requset 请求对象
4 # url = 'http://movie.douban.com/' 注意尾部的斜杆一定要有
5 url = 'http://www.bing.com/'
6
7 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
8
9 # 构造一个请求对象
10 request = Request(url)
11 request.add_header('User-Agent',ua)
12
13 print(type(request),'=============')
14 print(5,request.get_header('User-Agent'))
15 # 构建响应对象
16 response = urlopen(request, timeout=20) # requset对象或者url 都可以
17
18 print(type(response)) 19 20 21 with response: 22 # getcode本质上返回的就是 status 23 print(1, response.status, response.getcode(),response.reason) 24 # 返回数据的url,如果重定向,这个url和原始url不一样 25 print(2, response.geturl()) 26 # 返回响应头信息 27 print(3, response.info()) 28 # 读取返回的内容 29 print(4, response.read()) 30 31 print(5,request.get_header('User-Agent')) 32 print(6,'user-agent'.capitalize())
打印结果
urllib.parse 模块
该模块可以完成对url的编解码
编码:urlencode函数第一个参数要求是一个字典或者二元组序列
1 from urllib import parse
2
3 u = parse.urlencode({
4 'url':'http://www.magedu.com/python',
5 'p_url':'http:www.magedu.com/python?id=1&name=张三'
6 })
7 print(u)
url=http%3A%2F%2Fwww.magedu.com%2Fpython&p_url=http%3Awww.magedu.com%2Fpython%3Fid%3D1%26name%3D%E5%BC%A0%E4%B8%89
从运行结果来看冒号。斜杆 & 等号,问号都被编码,%之后实际上是单字节十六进制表示的值
一般来说,url中的地址部分,一般不需要使用中文路径,但是参数部分,不管 GET 还是post 方法,提交的数据中,可能有斜杆等符号,这样的字符表示数据,不表示元字符,如果直接发送给服务器端,就会导致接收方无法判断谁是元字符,谁是数据,为了安全,一般会将数据部分的字符串做url 编码,这样就不会有歧义了
,后来可以传送中文,同样会做编码,一般先按照字符集的encoding要求转化成字节序列,每一个字节对应的十六进制字符串前加上百分号即可。
1 '''
2 网页使用utf-8 编码
3 https://www.baidu.com/s?wd=中
4 上面的url编码后,如下:
5 https://www.baidu.com/s?wd=%E4%B8%AD
6 '''
7 from urllib import parse
8
9 u = parse.urlencode({'wd':'中'}) # 编码
10 print(u)
11
12 url = 'https://www.baidu.com/s?{}'.format(u)
13 print(url)
14
15 print('中'.encode('utf-8'))
16 # 解码
17 print(parse.unquote(u)) 18 print(parse.unquote(url))
打印结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt21.py
2 wd=%E4%B8%AD
3 https://www.baidu.com/s?wd=%E4%B8%AD
4 b'\xe4\xb8\xad'
5 wd=中
6 https://www.baidu.com/s?wd=中
7
8 Process finished with exit code 0
5、提交方法method
最常用的HTTP交互 数据的方法是GET ,POST
GET 方法,数据是通过URL 传递的,也就是说数据时候在http 报文的header部分
POST方法,数据是放在http报文的body 部分提交的
数据都是键值对形式,多个参数之间使用&符号链接,
GET方法:
连接 bing 搜索引擎官网,获取一个搜索的URL: http://cn.bing.com/search?q=张三
需求:
请写程序需完成对关键字的bing 搜索, 将返回的结果保存到一个网页文件中。
1 from urllib.request import Request, urlopen
2 from urllib.parse import urlencode
3
4 keyword = input('>>输入关键字')
5
6 data = urlencode({'q':keyword})
7
8 base_url = 'http://cn.bing.com/search'
9
10 url = '{}?{}'.format(base_url, data)
11
12 print(url) 13 14 # 伪装 15 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36' 16 request = Request(url, headers={'User-agent':ua}) 17 response = urlopen(request) 18 19 with response: 20 with open('./bing.html', 'wb') as f: 21 f.write(response.read())
结果:
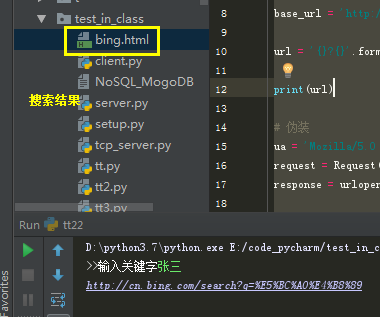
http GET 获取的文本 是字节形式(二进制)
POST 方法:
http://httpbin.org/ 测试网站 像一个echo,你发什么,给你什么
1 from urllib.request import Request, urlopen
2 from urllib.parse import urlencode
3 import simplejson
4
5 request = Request('http://httpbin.org/post')
6
7 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
8
9 request.add_header('User-agent', ua)
10
11 data = urlencode({'name':'张三,@=/&=', 'age':'12'}) 12 13 print(data) 14 15 res = urlopen(request, data=data.encode())# POST f方法 Form提交数据 16 with res: 17 print(res.read().decode())
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt23.py
2 name=%E5%BC%A0%E4%B8%89%2C%40%3D%2F%26%3D&age=12
3 {
4 "args": {},
5 "data": "",
6 "files": {},
7 "form": { 8 "age": "12", 9 "name": "\u5f20\u4e09,@=/&=" 10 }, 11 "headers": { 12 "Accept-Encoding": "identity", 13 "Connection": "close", 14 "Content-Length": "48", 15 "Content-Type": "application/x-www-form-urlencoded", 16 "Host": "httpbin.org", 17 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36" 18 }, 19 "json": null, 20 "origin": "61.149.196.193", 21 "url": "http://httpbin.org/post" 22 } 23 24 25 Process finished with exit code 0
处理JSON数据
查看豆瓣电影,看到最近热门电影的热门

通过分析,我们知道这部分内容,是通过AJAX 从后台拿到的json数据
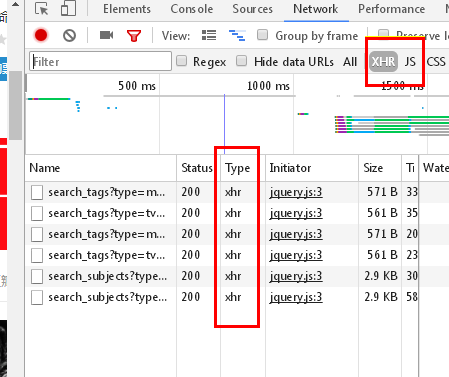
访问ur 是:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=50&page_start=0
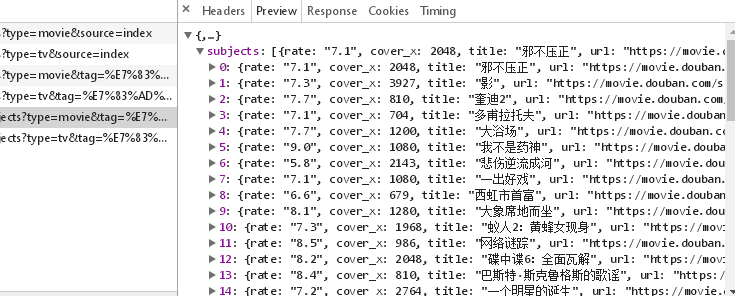
服务器返回的数据如上
1 from urllib import parse
2 将url解码:
3 print(parse.unquote('https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=50&page_start=0'))
4
5 ----------------------------------------------------------------------------------
6 https://movie.douban.com/j/search_subjects?type=movie&tag=热门&page_limit=50&page_start=0
通过代码获取上述截图内容:

6、HTTPS 证书忽略
HTTPS使用SSL 安全套接层协议,在传输层对网路数据进行加密,HTTPS 使用的时候,需要证书,而证书需要cA认证
1 from urllib.request import Request, urlopen
2
3 # 可以访问
4 # request = Request('http://www.12306.cn/mormhweb')
5 # request = Request('https://www.baidu.com')
6
7 request = Request('https://www.12306.cn/mormhweb/')
8
9
10 print(request)
11
12 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
13
14 request.add_header('User-agent', ua)
15
16 with urlopen(request) as res:
17 print(res._method) 18 print(res.read())

忽略证书不安全信息:
1 from urllib.request import Request, urlopen
2 import ssl
3
4 # 可以访问
5 # request = Request('http://www.12306.cn/mormhweb')
6 # request = Request('https://www.baidu.com')
7
8 request = Request('https://www.12306.cn/mormhweb/')
9
10
11 print(request)
12
13 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
14
15 request.add_header('User-agent', ua)
16 # 忽略不信任的证书(不用校验的上下文) 17 context = ssl._create_unverified_context() 18 res = urlopen(request, context=context) 19
20
21 with res: 22 print(res._method) 23 print(res.geturl()) 24 print(res.read().decode())
7、urllib3 库
https:// urllib3.readthedocs.io/en/latest
标准库urllib缺少了一些关键的功能,非标准库的第三方库 urlib3 提供了,比如说连接池管理
安装:pip install urllib3
1 import urllib3
2
3 url = 'http://movie.douban.com/'
4
5 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
6
7 # 连接池管理
8 with urllib3.PoolManager() as http:
9 response = http.request('GET', url, headers={"User-agent":ua})
10 print(1,type(response))
11 print(2,response.status, response.reason)
12 print(3,response.headers) 13 print(4,response.data.decode())
结果:
View Code
8、requests库(开发真正用的库)
requests 使用了 urllib3, 但是 API 更加友好,推荐使用
1 import requests
2
3 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
4
5 url = 'http://movie.douban.com/'
6
7 response = requests.request('GET', url,headers={'User-agent':ua})
8
9 with response:
10 print(type(response))
11 print(response)
12 print(response.url) 13 print((response.status_code)) 14 print(response.request.headers) #请求头 15 print(response.headers) # 响应头 16 print(response.encoding) 17 response.encoding = 'utf-8' 18 print(response.text[:100]) 19 20 with open('./movie.html', 'w', encoding='utf-8') as f: 21 f.write(response.text) # 保存文件
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt25.py
2 <class 'requests.models.Response'>
3 <Response [200]>
4 https://movie.douban.com/
5 200
6 {'User-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
7 {'Date': 'Wed, 05 Dec 2018 03:34:12 GMT', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Keep-Alive': 'timeout=30', 'Vary': 'Accept-Encoding', 'X-Xss-Protection': '1; mode=block', 'X-Douban-Mobileapp': '0', 'Expires': 'Sun, 1 Jan 2006 01:00:00 GMT', 'Pragma': 'no-cache', 'Cache-Control': 'must-revalidate, no-cache, private', 'Set-Cookie': 'll="108288"; path=/; domain=.douban.com; expires=Thu, 05-Dec-2019 03:34:12 GMT, bid=8QfNwA452hU; Expires=Thu, 05-Dec-19 03:34:12 GMT; Domain=.douban.com; Path=/', 'X-DOUBAN-NEWBID': '8QfNwA452hU', 'X-DAE-Node': 'brand15', 'X-DAE-App': 'movie', 'Server': 'dae', 'X-Content-Type-Options': 'nosniff', 'Content-Encoding': 'gzip'}
8 utf-8
9 <!DOCTYPE html>
10 <html lang="zh-cmn-Hans" class="ua-windows ua-webkit">
11 <head>
12 <meta http-equiv="
13
14 Process finished with exit code 0
request默认使用Session 对象,是为了在多次 和服务器交互中保留 会话的信息,例如cookie
否则,每次都要重新发起请求
1 # 直接使用Session
2 import requests
3
4 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
5
6 urls = ['https://www.baidu.com','https://www.baidu.com']
7
8 session = requests.Session()
9 with session:
10 for url in urls:
11 # response = session.get(url, headers={'User-agent':ua})
12 response = requests.request('GET', url, headers={'User-agent':ua}) # 相当于每次都是新的请求,也就是开启了两个浏览器而已
13 print(response) 14 with response: 15 print(response.request.headers) 16 print(response.cookies) 17 print(response.text[:20]) 18 print('----------------------------------------------') 19 ''' 20 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt19.py 21 <Response [200]> 22 {'User-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} 23 <RequestsCookieJar[<Cookie BAIDUID=808F0938C6A9CC144A1F6BEA823FF4F5:FG=1 for .baidu.com/>, <Cookie BIDUPSID=808F0938C6A9CC144A1F6BEA823FF4F5 for .baidu.com/>, <Cookie H_PS_PSSID=1444_21081_27509 for .baidu.com/>, <Cookie PSTM=1543981317 for .baidu.com/>, <Cookie delPer=0 for .baidu.com/>, <Cookie BDSVRTM=0 for www.baidu.com/>, <Cookie BD_HOME=0 for www.baidu.com/>]> 24 <!DOCTYPE html> 25 <!-- 26 ---------------------------------------------- 27 <Response [200]> 28 {'User-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} 29 <RequestsCookieJar[<Cookie BAIDUID=808F0938C6A9CC14FA9EECCB0280B074:FG=1 for .baidu.com/>, <Cookie BIDUPSID=808F0938C6A9CC14FA9EECCB0280B074 for .baidu.com/>, <Cookie H_PS_PSSID=26523_1469_25810_21098_26350_22073 for .baidu.com/>, <Cookie PSTM=1543981317 for .baidu.com/>, <Cookie delPer=0 for .baidu.com/>, <Cookie BDSVRTM=0 for www.baidu.com/>, <Cookie BD_HOME=0 for www.baidu.com/>]> 30 <!DOCTYPE html> 31 <!-- 32 ---------------------------------------------- 33 34 Process finished with exit code 0 35 36 ''' 37 38 with session: 39 for url in urls: 40 response = session.get(url, headers={'User-agent':ua}) 41 # response = requests.request('GET', url, headers={'User-agent':ua}) 42 print(response) 43 with response: 44 print(response.request.headers) 45 print(response.cookies) 46 print(response.text[:20]) 47 print('----------------------------------------------') 48 ''' 49 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt19.py 50 <Response [200]> 51 {'User-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} 52 <RequestsCookieJar[<Cookie BAIDUID=5A320955507582B839E723DB6F55B2BD:FG=1 for .baidu.com/>, <Cookie BIDUPSID=5A320955507582B839E723DB6F55B2BD for .baidu.com/>, <Cookie H_PS_PSSID=1434_21091_18559_27245_27509 for .baidu.com/>, <Cookie PSTM=1543981366 for .baidu.com/>, <Cookie delPer=0 for .baidu.com/>, <Cookie BDSVRTM=0 for www.baidu.com/>, <Cookie BD_HOME=0 for www.baidu.com/>]> 53 <!DOCTYPE html> 54 <!-- 55 ---------------------------------------------- 56 <Response [200]> 第二次访问,带上了cookie 57 {'User-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Cookie': 'BAIDUID=5A320955507582B839E723DB6F55B2BD:FG=1; BIDUPSID=5A320955507582B839E723DB6F55B2BD; H_PS_PSSID=1434_21091_18559_27245_27509; PSTM=1543981366; delPer=0; BDSVRTM=0; BD_HOME=0'} 58 <RequestsCookieJar[<Cookie H_PS_PSSID=1434_21091_18559_27245_27509 for .baidu.com/>, <Cookie delPer=0 for .baidu.com/>, <Cookie BDSVRTM=0 for www.baidu.com/>, <Cookie BD_HOME=0 for www.baidu.com/>]> 59 <!DOCTYPE html> 60 <!-- 61 ---------------------------------------------- 62 63 Process finished with exit code 0 64 65 '''
1、概述
爬虫,应该称为网络爬虫,也叫网页蜘蛛人,网络蚂蚁等
搜索引擎,就是网络爬虫的应用者
2、爬虫分类
通用爬虫:
常见就是搜索引擎,无差别的收集数据,存储,提交关键字,构建索引库,给用户提供搜索接口
爬取一般流程:
1、初始一批URL,将这些URL放到待爬的队列
2、从队列取出这些URL,通过DNS 解析IP ,对IP 对应的站点下载HTML页面,保存到本地服务器中,爬取完URL放到已经爬取的队列中
3、分析这些网页内筒,找出网页里面的其他关心的URL连接,继续执行第二步,直到爬取条件结束。
搜索引擎如何获取一个新网站的URL
-
-
- 新网站主动提交给搜索引擎
- 通过其他网站页面的外连接
- 搜索引擎和DNS 服务商合作,获取最新收录的网站。
-
聚焦爬虫:
有针对的编写特定领域数据的爬虫程序,针对某些 类别的数据采集的爬虫,是面向主体的爬虫
3、Robots 协议:
指定一个robots.txt 文件,告诉爬虫引擎什么可以爬,什么不可以爬
/ 表示网站根目录, 表示网站的所有目录
Allow:允许, Disallow:不允许
可以使用通配符
例如:淘宝:http://www.taobao.com/robots.txt
View Code
这是一个君子协定,爬亦有道
这个协议为了让搜索引擎更有效率的搜索自己内容,提供了如Sitemap 这样的文件
Sitemap 往往死一个XML 文件,提供了网站想让大家爬取的内容的更新信息
这个文件禁止爬取的往往又是我们可能感兴趣的内容,它反而泄露了这些地址。
4、HTTP请求和响应的处理
其实爬取网页就是通过HTTP 协议访问网页, 不过通过浏览器访问往往是认为行为,把这种行为变成程序来访问。
urllib包:
urllib 是标准库,它一个工具包模块,包含下面的模块处理 url
-
-
- urllib.request 用于打开和读写url
- urllib.error 包含了有urllib.request引起的异常。
- urllib.parse 用于解析url
- urllib.robotparser 分析robots.txt 文件
-
Python2 中提供了urlib 和urllib2 ,前者 提供了较为底层的接口,urllib2 对urllib 进行了进一步的封装,P樱桃红3中将urllib合并到饿了urllib中,并更名为标准库urllib包
urllib.request模块
模块定义了在基本和摘要式身份验证,重定向,cookies等应用中打开url(主要是HTTP)的函数和类
urlopen方法:
urlopen(url,data=None)
url 是链接地址字符串,或请求类的实例
data提交的数据,如果data为None,发起的是GET请求,否则发起POST请求,
见 urllib.request.Requset.get_method返回 http.client.HTTPResponse类的响应对象,这是一个类文件对象
1 from urllib.request import urlopen
2 from urllib import request
3
4
5 # 打开一个url返回一个响应对象,类文件对象
6 # 下面的链接,会301 跳转
7 response = urlopen('https://www.bing.com') #GET 方法
8 print(response)-----类文件对象
9 with response:
10 print(1, type(response))
11 print(2, response.status, response.reason)
12 print(3, response.geturl) 13 print(4, response.info()) 14 print(5, response.read()) 15 16 print(response.closed)
打印结果
上面,通过urllib.requset.urlopen 方法,发起一个HTTP的GET请求,web 服务器返回了网页内容,响应的数据被封装到类文件对象中,可以通过read方法,readline方法,readlines方法,获取数据,status,和reason 表示状态码, info方法表示返回header信息等
User-Agent问题
上例的代码非常精简,即可以获得网站的响应数据,但是目前urlopen方法通过url 字符串和data发起HTTP请求
如果想修改HTTP头,例如:useragent 就得借助其他方式
原码中构造的useragent 如下:
1 class OpenerDirector:
2 def __init__(self):
3 client_version = "Python-urllib/%s" % __version__
4 self.addheaders = [('User-agent', client_version)]
5 # self.handlers is retained only for backward compatibility
6 self.handlers = []
7 # manage the individual handlers
8 self.handle_open = {}
9 self.handle_error = {}
10 self.process_response = {} 11 self.process_request = {}
当前显示为 Python-urllib/3.7
有些网站是反爬虫的,所以要把爬虫伪装成浏览器,随便打开一个浏览器,复制浏览器的UA(useragent) 值,用来伪装。
Request类
Request(url, data=None, headers={} )
初始化方法,构造一个请求对象,可添加一个header的字典
data 参数决定是GET 还是POST 请求(data 为None是GET,有数据,就是POST)
add_header(key, val) 为header总增加一个键值对。
1 from urllib.request import Request, urlopen
2
3 # 打开一个url 返回一个Requset 请求对象
4 # url = 'http://movie.douban.com/' 注意尾部的斜杆一定要有
5 url = 'http://www.bing.com/'
6
7 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
8
9 # 构造一个请求对象
10 request = Request(url)
11 request.add_header('User-Agent',ua)
12
13 print(type(request),'=============')
14 print(5,request.get_header('User-Agent'))
15 # 构建响应对象
16 response = urlopen(request, timeout=20) # requset对象或者url 都可以
17
18 print(type(response)) 19 20 21 with response: 22 # getcode本质上返回的就是 status 23 print(1, response.status, response.getcode(),response.reason) 24 # 返回数据的url,如果重定向,这个url和原始url不一样 25 print(2, response.geturl()) 26 # 返回响应头信息 27 print(3, response.info()) 28 # 读取返回的内容 29 print(4, response.read()) 30 31 print(5,request.get_header('User-Agent')) 32 print(6,'user-agent'.capitalize())
打印结果
urllib.parse 模块
该模块可以完成对url的编解码
编码:urlencode函数第一个参数要求是一个字典或者二元组序列
1 from urllib import parse
2
3 u = parse.urlencode({
4 'url':'http://www.magedu.com/python',
5 'p_url':'http:www.magedu.com/python?id=1&name=张三'
6 })
7 print(u)
url=http%3A%2F%2Fwww.magedu.com%2Fpython&p_url=http%3Awww.magedu.com%2Fpython%3Fid%3D1%26name%3D%E5%BC%A0%E4%B8%89
从运行结果来看冒号。斜杆 & 等号,问号都被编码,%之后实际上是单字节十六进制表示的值
一般来说,url中的地址部分,一般不需要使用中文路径,但是参数部分,不管 GET 还是post 方法,提交的数据中,可能有斜杆等符号,这样的字符表示数据,不表示元字符,如果直接发送给服务器端,就会导致接收方无法判断谁是元字符,谁是数据,为了安全,一般会将数据部分的字符串做url 编码,这样就不会有歧义了
,后来可以传送中文,同样会做编码,一般先按照字符集的encoding要求转化成字节序列,每一个字节对应的十六进制字符串前加上百分号即可。
1 '''
2 网页使用utf-8 编码
3 https://www.baidu.com/s?wd=中
4 上面的url编码后,如下:
5 https://www.baidu.com/s?wd=%E4%B8%AD
6 '''
7 from urllib import parse
8
9 u = parse.urlencode({'wd':'中'}) # 编码
10 print(u)
11
12 url = 'https://www.baidu.com/s?{}'.format(u)
13 print(url)
14
15 print('中'.encode('utf-8'))
16 # 解码
17 print(parse.unquote(u)) 18 print(parse.unquote(url))
打印结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt21.py
2 wd=%E4%B8%AD
3 https://www.baidu.com/s?wd=%E4%B8%AD
4 b'\xe4\xb8\xad'
5 wd=中
6 https://www.baidu.com/s?wd=中
7
8 Process finished with exit code 0
5、提交方法method
最常用的HTTP交互 数据的方法是GET ,POST
GET 方法,数据是通过URL 传递的,也就是说数据时候在http 报文的header部分
POST方法,数据是放在http报文的body 部分提交的
数据都是键值对形式,多个参数之间使用&符号链接,
GET方法:
连接 bing 搜索引擎官网,获取一个搜索的URL: http://cn.bing.com/search?q=张三
需求:
请写程序需完成对关键字的bing 搜索, 将返回的结果保存到一个网页文件中。
1 from urllib.request import Request, urlopen
2 from urllib.parse import urlencode
3
4 keyword = input('>>输入关键字')
5
6 data = urlencode({'q':keyword})
7
8 base_url = 'http://cn.bing.com/search'
9
10 url = '{}?{}'.format(base_url, data)
11
12 print(url) 13 14 # 伪装 15 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36' 16 request = Request(url, headers={'User-agent':ua}) 17 response = urlopen(request) 18 19 with response: 20 with open('./bing.html', 'wb') as f: 21 f.write(response.read())
结果:
http GET 获取的文本 是字节形式(二进制)
POST 方法:
http://httpbin.org/ 测试网站 像一个echo,你发什么,给你什么
1 from urllib.request import Request, urlopen
2 from urllib.parse import urlencode
3 import simplejson
4
5 request = Request('http://httpbin.org/post')
6
7 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
8
9 request.add_header('User-agent', ua)
10
11 data = urlencode({'name':'张三,@=/&=', 'age':'12'}) 12 13 print(data) 14 15 res = urlopen(request, data=data.encode())# POST f方法 Form提交数据 16 with res: 17 print(res.read().decode())
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt23.py
2 name=%E5%BC%A0%E4%B8%89%2C%40%3D%2F%26%3D&age=12
3 {
4 "args": {},
5 "data": "",
6 "files": {},
7 "form": { 8 "age": "12", 9 "name": "\u5f20\u4e09,@=/&=" 10 }, 11 "headers": { 12 "Accept-Encoding": "identity", 13 "Connection": "close", 14 "Content-Length": "48", 15 "Content-Type": "application/x-www-form-urlencoded", 16 "Host": "httpbin.org", 17 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36" 18 }, 19 "json": null, 20 "origin": "61.149.196.193", 21 "url": "http://httpbin.org/post" 22 } 23 24 25 Process finished with exit code 0
处理JSON数据
查看豆瓣电影,看到最近热门电影的热门
通过分析,我们知道这部分内容,是通过AJAX 从后台拿到的json数据
访问ur 是:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=50&page_start=0
服务器返回的数据如上
1 from urllib import parse
2 将url解码:
3 print(parse.unquote('https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=50&page_start=0'))
4
5 ----------------------------------------------------------------------------------
6 https://movie.douban.com/j/search_subjects?type=movie&tag=热门&page_limit=50&page_start=0
通过代码获取上述截图内容:
6、HTTPS 证书忽略
HTTPS使用SSL 安全套接层协议,在传输层对网路数据进行加密,HTTPS 使用的时候,需要证书,而证书需要cA认证
1 from urllib.request import Request, urlopen
2
3 # 可以访问
4 # request = Request('http://www.12306.cn/mormhweb')
5 # request = Request('https://www.baidu.com')
6
7 request = Request('https://www.12306.cn/mormhweb/')
8
9
10 print(request)
11
12 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
13
14 request.add_header('User-agent', ua)
15
16 with urlopen(request) as res:
17 print(res._method) 18 print(res.read())
忽略证书不安全信息:
1 from urllib.request import Request, urlopen
2 import ssl
3
4 # 可以访问
5 # request = Request('http://www.12306.cn/mormhweb')
6 # request = Request('https://www.baidu.com')
7
8 request = Request('https://www.12306.cn/mormhweb/')
9
10
11 print(request)
12
13 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
14
15 request.add_header('User-agent', ua)
16 # 忽略不信任的证书(不用校验的上下文) 17 context = ssl._create_unverified_context() 18 res = urlopen(request, context=context) 19
20
21 with res: 22 print(res._method) 23 print(res.geturl()) 24 print(res.read().decode())
7、urllib3 库
https:// urllib3.readthedocs.io/en/latest
标准库urllib缺少了一些关键的功能,非标准库的第三方库 urlib3 提供了,比如说连接池管理
安装:pip install urllib3
1 import urllib3
2
3 url = 'http://movie.douban.com/'
4
5 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
6
7 # 连接池管理
8 with urllib3.PoolManager() as http:
9 response = http.request('GET', url, headers={"User-agent":ua})
10 print(1,type(response))
11 print(2,response.status, response.reason)
12 print(3,response.headers) 13 print(4,response.data.decode())
结果:
View Code
8、requests库(开发真正用的库)
requests 使用了 urllib3, 但是 API 更加友好,推荐使用
1 import requests
2
3 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
4
5 url = 'http://movie.douban.com/'
6
7 response = requests.request('GET', url,headers={'User-agent':ua})
8
9 with response:
10 print(type(response))
11 print(response)
12 print(response.url) 13 print((response.status_code)) 14 print(response.request.headers) #请求头 15 print(response.headers) # 响应头 16 print(response.encoding) 17 response.encoding = 'utf-8' 18 print(response.text[:100]) 19 20 with open('./movie.html', 'w', encoding='utf-8') as f: 21 f.write(response.text) # 保存文件
结果:
1 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt25.py
2 <class 'requests.models.Response'>
3 <Response [200]>
4 https://movie.douban.com/
5 200
6 {'User-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
7 {'Date': 'Wed, 05 Dec 2018 03:34:12 GMT', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Keep-Alive': 'timeout=30', 'Vary': 'Accept-Encoding', 'X-Xss-Protection': '1; mode=block', 'X-Douban-Mobileapp': '0', 'Expires': 'Sun, 1 Jan 2006 01:00:00 GMT', 'Pragma': 'no-cache', 'Cache-Control': 'must-revalidate, no-cache, private', 'Set-Cookie': 'll="108288"; path=/; domain=.douban.com; expires=Thu, 05-Dec-2019 03:34:12 GMT, bid=8QfNwA452hU; Expires=Thu, 05-Dec-19 03:34:12 GMT; Domain=.douban.com; Path=/', 'X-DOUBAN-NEWBID': '8QfNwA452hU', 'X-DAE-Node': 'brand15', 'X-DAE-App': 'movie', 'Server': 'dae', 'X-Content-Type-Options': 'nosniff', 'Content-Encoding': 'gzip'}
8 utf-8
9 <!DOCTYPE html>
10 <html lang="zh-cmn-Hans" class="ua-windows ua-webkit">
11 <head>
12 <meta http-equiv="
13
14 Process finished with exit code 0
request默认使用Session 对象,是为了在多次 和服务器交互中保留 会话的信息,例如cookie
否则,每次都要重新发起请求
1 # 直接使用Session
2 import requests
3
4 ua = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36'
5
6 urls = ['https://www.baidu.com','https://www.baidu.com']
7
8 session = requests.Session()
9 with session:
10 for url in urls:
11 # response = session.get(url, headers={'User-agent':ua})
12 response = requests.request('GET', url, headers={'User-agent':ua}) # 相当于每次都是新的请求,也就是开启了两个浏览器而已
13 print(response) 14 with response: 15 print(response.request.headers) 16 print(response.cookies) 17 print(response.text[:20]) 18 print('----------------------------------------------') 19 ''' 20 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt19.py 21 <Response [200]> 22 {'User-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} 23 <RequestsCookieJar[<Cookie BAIDUID=808F0938C6A9CC144A1F6BEA823FF4F5:FG=1 for .baidu.com/>, <Cookie BIDUPSID=808F0938C6A9CC144A1F6BEA823FF4F5 for .baidu.com/>, <Cookie H_PS_PSSID=1444_21081_27509 for .baidu.com/>, <Cookie PSTM=1543981317 for .baidu.com/>, <Cookie delPer=0 for .baidu.com/>, <Cookie BDSVRTM=0 for www.baidu.com/>, <Cookie BD_HOME=0 for www.baidu.com/>]> 24 <!DOCTYPE html> 25 <!-- 26 ---------------------------------------------- 27 <Response [200]> 28 {'User-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} 29 <RequestsCookieJar[<Cookie BAIDUID=808F0938C6A9CC14FA9EECCB0280B074:FG=1 for .baidu.com/>, <Cookie BIDUPSID=808F0938C6A9CC14FA9EECCB0280B074 for .baidu.com/>, <Cookie H_PS_PSSID=26523_1469_25810_21098_26350_22073 for .baidu.com/>, <Cookie PSTM=1543981317 for .baidu.com/>, <Cookie delPer=0 for .baidu.com/>, <Cookie BDSVRTM=0 for www.baidu.com/>, <Cookie BD_HOME=0 for www.baidu.com/>]> 30 <!DOCTYPE html> 31 <!-- 32 ---------------------------------------------- 33 34 Process finished with exit code 0 35 36 ''' 37 38 with session: 39 for url in urls: 40 response = session.get(url, headers={'User-agent':ua}) 41 # response = requests.request('GET', url, headers={'User-agent':ua}) 42 print(response) 43 with response: 44 print(response.request.headers) 45 print(response.cookies) 46 print(response.text[:20]) 47 print('----------------------------------------------') 48 ''' 49 D:\python3.7\python.exe E:/code_pycharm/test_in_class/tt19.py 50 <Response [200]> 51 {'User-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'} 52 <RequestsCookieJar[<Cookie BAIDUID=5A320955507582B839E723DB6F55B2BD:FG=1 for .baidu.com/>, <Cookie BIDUPSID=5A320955507582B839E723DB6F55B2BD for .baidu.com/>, <Cookie H_PS_PSSID=1434_21091_18559_27245_27509 for .baidu.com/>, <Cookie PSTM=1543981366 for .baidu.com/>, <Cookie delPer=0 for .baidu.com/>, <Cookie BDSVRTM=0 for www.baidu.com/>, <Cookie BD_HOME=0 for www.baidu.com/>]> 53 <!DOCTYPE html> 54 <!-- 55 ---------------------------------------------- 56 <Response [200]> 第二次访问,带上了cookie 57 {'User-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3486.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Cookie': 'BAIDUID=5A320955507582B839E723DB6F55B2BD:FG=1; BIDUPSID=5A320955507582B839E723DB6F55B2BD; H_PS_PSSID=1434_21091_18559_27245_27509; PSTM=1543981366; delPer=0; BDSVRTM=0; BD_HOME=0'} 58 <RequestsCookieJar[<Cookie H_PS_PSSID=1434_21091_18559_27245_27509 for .baidu.com/>, <Cookie delPer=0 for .baidu.com/>, <Cookie BDSVRTM=0 for www.baidu.com/>, <Cookie BD_HOME=0 for www.baidu.com/>]> 59 <!DOCTYPE html> 60 <!-- 61 ---------------------------------------------- 62 63 Process finished with exit code 0 64 65 '''