在上一篇目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN 之 RCNN中,我讲了 RCNN 算法,似乎它的表现不太好,所以这次我们讲讲它的进化版 —— Fast RCNN 和 Faster RCNN。
1. Fast RCNN
先看看 Fast RCNN,RCNN 的时间花费主要来自于计算量的巨大。Fast RCNN 在时间花费的提升,就是因为减少了很多的计算量。比较一下,在 RCNN 上,我们在 CNN 上对一张图片跑 2000 次(因为一张图片会用 Selective Search 生成 2000 个建议区域),但是在 Fast RCNN 上我们对每一张图片只跑一次,然后就可以得到所有的区域,这些区域会在后面放到一个 映射(map) 上面,就可以一次生成了。(后面看到图可能会比较直观。)
RCNN 的作者 Ross Girshick 应用一种方法来让 2000 个区域共享 CNN 中的计算。所以在 Fast RCNN 中把输入图片放到 CNN 中,它会生成卷积特征映射。建议区域就会被提取到这个映射上面。然后使用一个 RoI 池化层(RoI pooling layer) 来把所有的建议区域转换成适合的尺寸,这样就可以输进后面的 全连接层(fully connnected network) 了。
分步来看看会比较清晰,这一步我直接把每一步的图片加上去,有助于理解:
-
首先是输入图片,这与之前的 RCNN 差不多:

-
图片通过 卷积网络(ConvNet) 得到 RoI:

-
然后应用 RoI 池化层来改变所提取的感兴趣区域的大小,也就是 RoI 的大小,来确保所有的区域都是相同的尺寸,这是为了后面可以输入到全连接层上。所以这里的 RoI Pooling 是 Fast RCNN 的另一份新方法:

-
最后这些区域就输入到全连接层来对它们进行分类,同时会使用 softmax 和 线性回归层(linear regression layers) 来输出 bounding boxes:
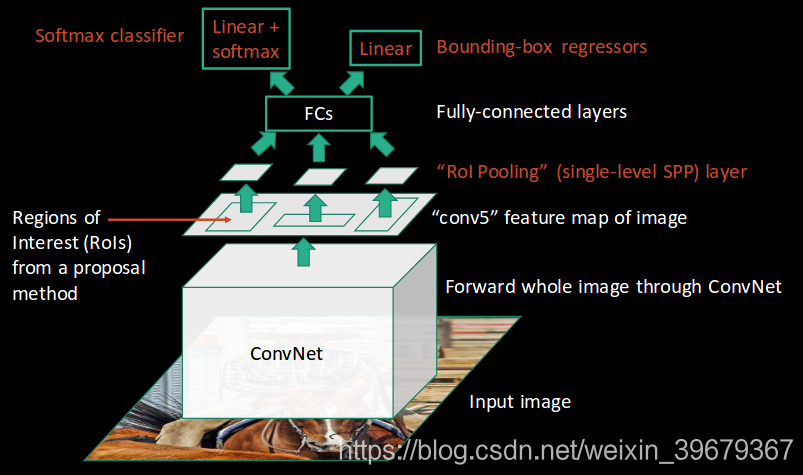
我们来看看两个网络的差别。在 RCNN 上 2000 个区域都是独立的,没有生成映射,而在 Fast RCNN 上,生成的映射就相当于一个区域;在特征提取、分类和生成选框上,前者使用了三个模型,而后者把三个模型集合到一个模型中,这样一来就省下了很多的时间。
2. Fast RCNN 的不足
Fast RCNN 没有解决的一个问题就是,它依然在使用选择性搜索来作为寻找 RoI 的区域建议方法,因为它依然很慢。每张图片话费 2 秒的时间吧,虽然这和 RCNN 比起来好很多了。但是依然不能够在大量数据上使用。
3. Faster RCNN 横空出世
Faster RCNN 与 Fast RCNN 最大的不同就是:Faster RCNN(以下称为 Faster)使用了一个全新的网络 —— Region Proposal Network,也就是「区域建议网络」,简称 RPN。RPN 把图片特征 map 作为输入,生成一系列的带目标分数的建议。也就是说,不再是单纯地只输出建议,而是把建议中是否有物体的分数也预测了。分数越高,代表区域包含物体的可能性越高。
还是来看看图文步骤:
- 把图片作为输入放进卷积网络中去,返回的是一个特征映射(feature map);
- RPN 处理这些 map,返回带分数的物体建议;
- 接下来的 RoI pooling 把这些建议都 reshape 成相同的尺寸;
- 最后,放到含有 softmax 层和线性回归层的全连接层上,来分类和输出 bounding boxes。
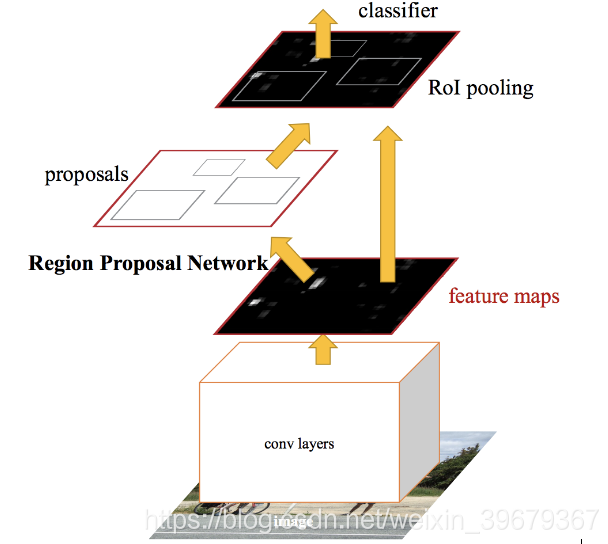
这里 RPN 被集成在了网络里面,等于从区域建议到最后的分类回归都在同一个网络,实现了端到端。即我们给这个网络输入一张图片,网络就会输出 bounding boxes 和分数。RPN 是 Faster 的重点,来看看里面怎么运作的。
从上图看到,Faster 从 CNN(图中 conv layers)里得到 feature map,然后输入到 RPN 里。在 RPN 在这个 map 上使用一个滑动窗口(sliding window),在每个窗口中都会生成 k 个不同形状和大小的 Anchor boxes。在论文中他们使用的是 9 个 Anchor。
Anchor 就是在图片中有不同形状和大小的但具有固定尺寸的边界框。什么意思呢?就是每一个 Anchor 都是固定的大小,比如有 3*3、6*6、3*6、6*3 这些,他们和最后的 bounding boxes 不一样,anchor 的尺寸都是固定的。就像上图红色的框,而旁边的蓝色的框代表了其不同形状和大小的框。
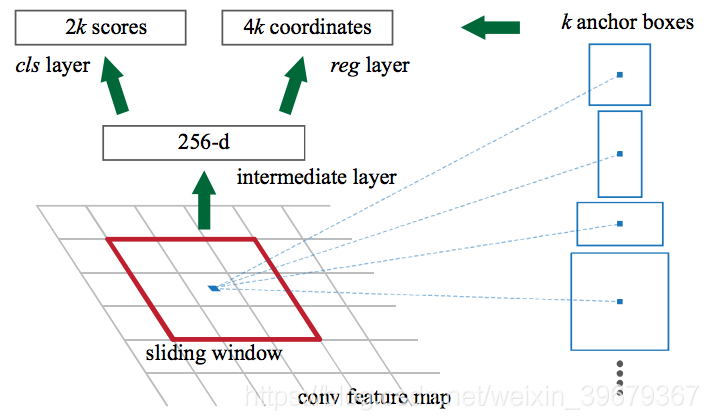
对于 anchor,RPN 会做两件事:
- 第一件就是预测 anchor 框出的部分属于物体的可能性;
- 第二就是这个 anchor 对于最后应该生成的 bounding box 的回归,或者说怎么去调节这个 anchor 能使它更加好的框出物体。
在 RPN 之后我们会得到不同形状大小的 bounding boxes,再输入到 RoI 池化层中。在这一步,虽然知道 boxes 里面是一个物体了,但其实是不知道它属于哪个类别的。就好像是,它知道这个东西是个物体,但是不知道是猫是狗还是人。RoI 池化层的作用就是提取每个 anchor 的固定大小的 feature map:
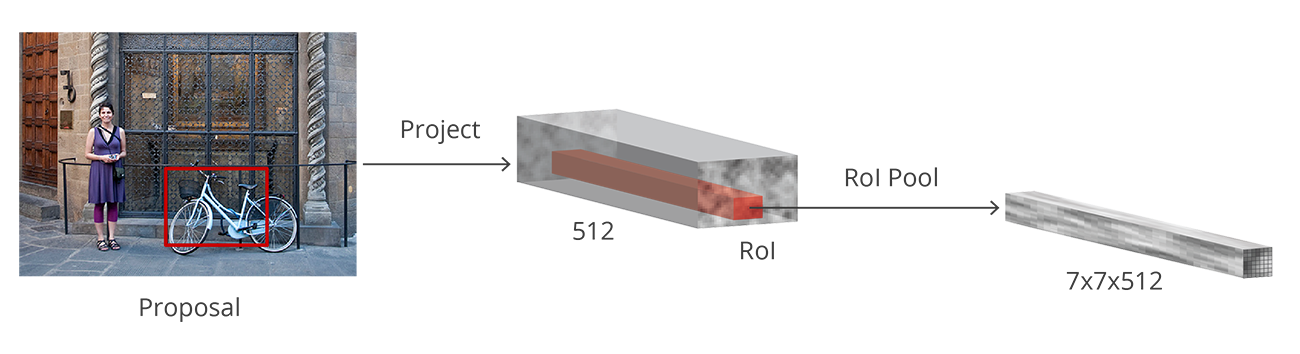
这些 feature map 最后就被送到全连接层里去做 softmax 分类和线性回归。最后就会得到分类好的又有 bounding box 的物体了。
4. Faster RCNN 的不足
虽然是 Faster 了,但是其实还是存在不足的。但是在我看来,它表现得已经很好了,但是我们的目标总是想往着更好去的不是吗?
从 RCNN 到 Faster 算法,所有的这些都是使用区域建议来识别物体的。这些网络不是看一张图片的整体的,而是集中关注它的某一部分,这样就造成了两个问题:
- 网络需要对一张图片的每一部分都处理,以此来保证能够检测出所有的物体;
- 网络中的每一部分都接在上一部分的后面,所以后面系统的表现就依赖于前面系统了。
5. 各种算法的比较:
| 算法 | 特点 | 平均时间花费(秒) | 限制性 |
|---|---|---|---|
| CNN | 把图片分为多个区域然后对各个区域进行分类 | — | 需要大量地区域才能使得预测变精确,但是这样做会带来很大的计算量 |
| RCNN | 使用选择性搜索生成区域,每张图片抽取 2000 个区域。 | 45 - 50 | 由于每个区域都输入到 CNN 上,而且使用了三个独立的模型,计算时间很长 |
| Fast RCNN | 每张图片由 CNN 抽取 feature maps,然后由选择性搜索来生成预测区域;把 RCNN 的三个模型集成为一个 | 2 | 因为选择性搜索本身就很慢,再加上计算量依旧没减,时间花费还是挺高 |
| Faster RCNN | 用**区域建议网络(RPN)**来代替选择性搜索,使得算法变得快了很多 | 0.2 | 因为不同的系统使用串联的方式连接,目标建议依旧是时间花费的主要原因,而且每层系统的表现受到上层系统的制约 |
6. 结语
我们介绍了 RCNN 的历史。但这仅仅是目标检测算法的开始,还有许许多多的算法,我们会陆续为你介绍。目标检测是一个很吸引人的领域。RCNN 算是其中的一个经典,但是还有其他表现得比它好的算法,例如:YOLO、RetinaNet、Master RCNN 等。我们会继续讲解介绍这些网络,期待着吧!
如果你想了解更多关于人工智能的资讯,欢迎扫码关注微信公众号以及知乎专栏 「译智社」,我们为大家提供优质的人工智能文章、国外优质博客和论文等资讯哟!
