接到一个小项目,做疲劳驾驶检测(实时),刚开始着手,感觉有点古怪(其实就是难或者自己菜)。
因为项目方给的是视频,首先特征提取和学习(如果有学习)过程和预测应该是要用图片做的。

给定数据为视频,如上,要求是检测四个项目的完成度并提出预警,首先我不认为四个类别全部使用DL或底层的特征分类的其中一种会得到最好的效果,肯定是要尝试。
最先开始做的肯定是最简单的,个人认为不需要ROI,并且可以使用流行的DL模型做的是calling,数据集我展示一小部分。
由于拍摄用的是红外,所以只有calling这一部分是不失真的,完全可以不经预处理直接去训练的。
下面是我的训练过程和结果:(代码就不放了太长了)
首先手动给VGG16加上下面几层:

train_data_dir = 'data_call/train'
validation_data_dir = 'data_call/val'
nb_train_samples = 748
nb_validation_samples = 196
epochs = 40
batch_size = 32
train_datagen = ImageDataGenerator(
# samplewise_center = True,
rotation_range=10,
width_shift_range=0.3,
height_shift_range=0.3,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip= True,
# vertical_flip=True,
rescale=1. / 255
)
imagedatagenerator部分还在求助,是真的看不太懂。
# this is the augmentation configuration we will use for testing:
# only rescaling
validation_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='categorical')
validation_generator = validation_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='categorical')
fit部分:
history = model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=40,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size,
verbose=1,
#callbacks=None)
callbacks=callbacks)
#callbacks=[batch_parms])
训练过程:
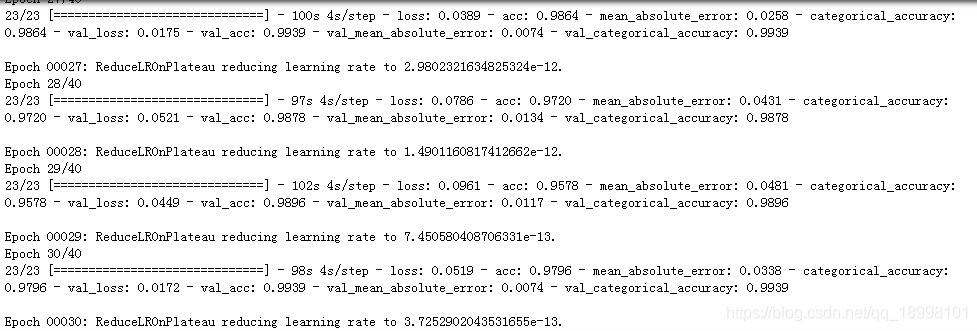
test预处理和预测部分:
#files = glob.glob("validation/P_NG/*")
files = glob.glob("data_call/test/*bmp")
image_list = []
for f in files:
print (f)
image = cv2.imread(f)
if np.all(image ==None):
pass
else:
image = cv2.resize(image,(128,128))
image = image/ 255.
image = np.expand_dims(image,axis=0)
# image_list.append(image)
pre=model.predict(image, verbose=1, batch_size=32)
#pre.append(f)
print(pre)
if pre[0][0]>pre[0][1]:
image_list.append(f)
# image_list = np.array(image_list)
# predictions = model.predict(image_list, verbose=1, batch_size=32)
print(image_list)
预测结果展示:
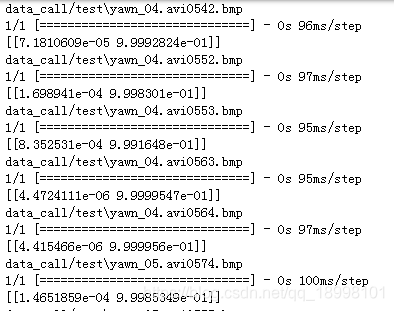
acc和loss:
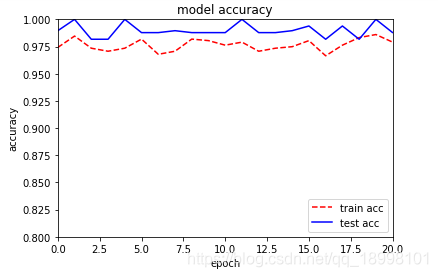
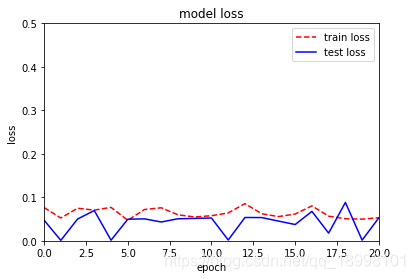
loss是可以轻松做到0.01级别的,我心甚慰。
接下来的工作还是想用不同的方法把四个部分的二分类先做出来,然后根据联动特征组合出疲劳预警;
比如眼部和嘴部可能需要用底层技术解决,使用深度学习效果不一定最好的。