Scala
Scala字符串
Scala中字符串也是分为两种: 可变长度的StringBuilder和不可变长度的String, 其操作用法与Java几乎一致.
接下来, 通过代码来查看常用方法
//定义字符串
val str1 = "Hello Scala"
var str2 = "Hello Scala"
var str2_1 = "hello scala"
//字符串比较
println(str1 == str2)
println(str1.equals(str2))
println(str1.equalsIgnoreCase(str2_1))
//上述三个比较全部返回true
//按字典顺序比较两个字符串
println(str1.compareTo(str3))
//按字典顺序比较两个字符串,不考虑大小写
println(str1.compareToIgnoreCase(str3))
//从0开始返回指定位置的字符
println(str1.charAt(6))
//追加
println(str2.concat(" Language"))
//是否以指定的后缀结束
println(str1.endsWith("la"))
//使用默认字符集将String编码为 byte 序列
println(str1.getBytes)
//哈希码
println(str1.hashCode)
//指定子字符串在此字符串中第一次出现处的索引
println(str1.indexOf("ca"))
//字符串对象的规范化表示形式
println(str1.intern())
//指定子字符串在此字符串中最后一次出现处的索引
println(str1.lastIndexOf("al"))
//长度
println(str1.length)
//匹配正则表达式
println(str1.matches("d+"))
//替换字符
println(str1.replace('a','o'))
//根据字符切割, 需要注意Scala中从数组中取元素使用小括号
println(str1.split(" ")(1))
//是否以指定字符串开始
println(str1.startsWith("Hel"))
//截取子字符串
println(str1.substring(3))
println(str1.substring(3,7))
//大小写
println(str1.toLowerCase())
println(str1.toUpperCase())
//去空格
println(str1.trim)
//使用StringBuilder
val strBuilder = new StringBuilder
//拼接字符串
strBuilder.append("Hello ")
strBuilder.append("Scala")
println(strBuilder)
//反转
println(strBuilder.reverse)
//返回容量
println(strBuilder.capacity)
//指定位置插入
println(strBuilder.insert(6,"Spark "))
Scala 集合
1. 数组
Java中使用 new String[10]的形式可以创建数组, 但Scala中创建数组需要用到Array关键词, 用[ ]指定数组中元素的泛型, 取值使用小括号(index).
//创建Int类型的数组, 默认值为0
val nums = new Array[Int](10)
//创建String类型的数组, 默认值为null
val strs = new Array[String](10)
//创建Boolean类型的数组, 默认值为false
val bools = new Array[Boolean](10)
//通过索引遍历数组,给元素赋值
for (index <- 0 until nums.length) nums(index) = index + 1
//数组遍历,编码的逐步简化
nums.foreach ( (x: Int) => print(x + " ") )
println()
nums.foreach ( (x => print(x + " ")) )
println()
nums.foreach(print(_))
println()
nums.foreach(print)
foreach函数传入一个函数参数, 由于Scala支持类型推测, 可以将参数函数的参数类型省略; 在参数函数中, 该函数的参数只出现一次, 因为可以使用下划线_代替(如果有多个可以使用_.1/_.2); 最后由于Scala语言的灵活性, 只需传入print这个函数也会遍历打印整个集合.
创建二维数组分两步: 创建一个泛型为数组的数组, 然后对这个数组遍历,
val secArray = new Array[Array[String]](5)
for (index <- 0 until secArray.length){
secArray(index) = new Array[String](5)
}
//填充数据
for (i <- 0 until secArray.length;j <- 0 until secArray(i).length) {
secArray(i)(j) = i * j + ""
}
secArray.foreach(array => array.foreach(println))
2. list
Scala中列表的定义使用List关键词. List集合是一个不可变的集合. 下面来看创建List已经list调用的方法.
//创建列表
val list = List(1,2,3,4,5)
//对列表遍历
list.foreach(println)
//contains判断是否包含某个元素
println(list.contains(6))
//反序,返回一个新的List
list.reverse.foreach(println)
//去前n个元素,返回一个新的List
list.take(3).foreach(println)
//删除前n个元素,返回一个新的List
list.drop(2).foreach(println)
//判断集合中是否有元素满足判断条件
println(list.exists(_ > 4))
//把List中的元素用设置的字符(串)进行拼接
list.mkString("==").foreach(print)
/*map是一个高阶函数,需要一个函数参数
返回值是That,意思是谁调用的map返回的类型跟调用map方法的对象的类型一致
这里map返回的仍然是list,因此在map中可对每一个元素进行相同操作
map返回的list的泛型由编码传入的函数返回类型决定,如下(_ * 100)返回的list的泛型就是Int
*/
list.map(println)
list.map(_ * 100).foreach(println)
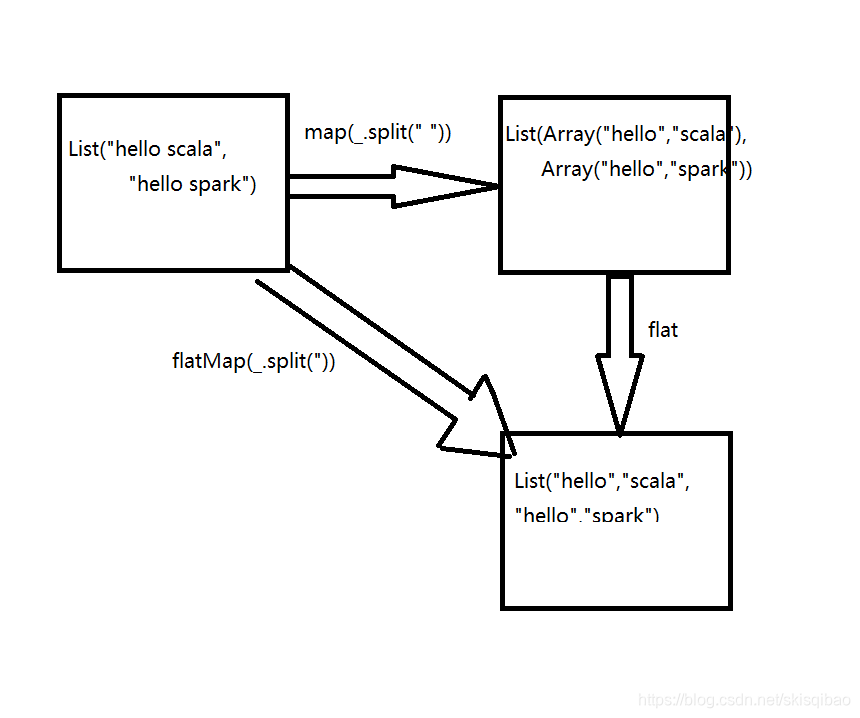
val logList = List("Hello Scala" , "Hello Spark")
/*由上述介绍可知,split()返回一个数组,因此map返回的类型是泛型为数组类型的list
需要对返回的list进行两次遍历,第一次遍历得到Array,第二次遍历拿到String
*/
logList.map(_.split(" ")).foreach(_.foreach(println))
/*
如果想直接拿到String,需要:
扁平操作
用到的函数是flatMap,flatMap返回的类型也是调用该方法的类型,但它可以直接得到String类型的单词
*/
logList.flatMap(_.split(" ")).foreach(println)
对map和flatMap的理解可参考下图:
Nil创建一个空List
Nil.foreach(println)
//::操作可用来添加元素
val list1 = 1::2::Nil
list1.foreach(println)
需要注意的是, 上述创建的list均为不可变长度的list, 即list中的元素只有在创建时才能添加. 创建可变长度的list, 需要用到ListBuffer, 看代码:
//创建一个ListBuffer,需要导包scala.collection.mutable.ListBuffer
val listBuffer = new ListBuffer[String]
//使用+=添加元素
listBuffer.+=("hello")
listBuffer.+=("Scala")
listBuffer.foreach(println)
//使用-=去除元素
listBuffer.-=("hello")
3. set
Scala中使用Set关键词定义无重复项的集合.
Set常用方法展示:
//创建Set集合,Scala中会自动去除重复的元素
val set1 = Set(1,1,1,2,2,3)
//遍历Set即可使用foreach也可使用for循环
set1.foreach(x => print( x + "\t"))
val set2 = Set(1,2,3,5,7)
//求两个集合的交集
set1.intersect(set2).foreach(println)
set1.&(set2).foreach(println)
//求差集
set2.diff(set1).foreach(println)
set2.&~(set1).foreach(println)
//求子集,如果set1中包含set2,则返回true.注意是set1包含set2返回true
println(set2.subsetOf(set1))
//求最大值
println(set1.max)
//求最小值
println(set1.min)
//转成List类型
set1.toList.map(println)
//转成字符串类型
set1.mkString("-").foreach(print)
4. Map
Scala中使用Map关键字创建KV键值对格式的数据类型.
4.1 创建map集合
val map = Map(
"1" -> "Hello",
2 -> "Scala",
3 -> "Spark"
)
创建Map时, 使用->来分隔key和value, KV类型可不相同, 中间使用逗号进行分隔.
4.2 map遍历
遍历map有三种方式, 即可使用foreach, 也可使用与Java中相同用法的迭代器, 还可使用for循环.
- 方式一: foreach
map.foreach(println)
此时, 打印的是一个个二元组类型的数据, 关于元组我们后文中会详细介绍, 此处只展示一下二元组的样子: (1,Hello); (2,Scala); (3,Spark).
- 方式二: 迭代器
val keyIterator = map.keys.iterator
while (keyIterator.hasNext){
val key = keyIterator.next()
println(key + "--" + map.get(key).get)
}
此时需注意:
map.get(key)返回值, 返回提示:
an option value containing the value associated with key in this map, or None if none exists.
即返回的是一个Option类型的对象, 如果能够获取到值, 则返回的是一个Some(Option的子类)类型的数据, 例如打印会输出Some(Hello), 再通过get方法就可以获取到其值;
如果没有值会返回一个None(Option的子类)类型的数据, 该类型不能使用get方法获取值(本来就无值, 强行取值当然要出异常)
看get方法的提示(如下), 元素必须存在, 否则抛出NoSuchElementException的异常.
Returns the option's value. Note: The option must be nonEmpty.
Throws:
Predef.NoSuchElementException - if the option is empty.
既然这样, 对于None类型的数据就不能使用get了, 而是使用getOrElse(“default”)方法, 该方法会先去map集合中查找数据, 如果找不到会返回参数中设置的默认值. 例如,
//在上述map定义的情况下执行下述代码,会在终端打印default
println(map.get(4).getOrElse("default"))
- 方式三: for循环
for(k <- map) println(k._1 + "--" + k._2)
此处, 将map中的每一对KV以二元组(1, Hello)的形式赋给k这一循环变量. 可通过k._1来获取第一个位置的值, k._2获取第二个位置的值.
4.3 Map合并
//合并map
val map1 = Map(
(1,"a"),
(2,"b"),
(3,"c")
)
val map2 = Map(
(1,"aa"),
(2,"bb"),
(2,90),
(4,22),
(4,"dd")
)
map1.++:(map2).foreach(println)
++和++:的区别
| 函数 | 调用 | 含义 |
|---|---|---|
| ++ | map1.++(map2) | map1中加入map2 |
| ++: | map1.++:(map2) | map2中加入map1 |
注意:map在合并时会将相同key的value替换
4.4 Map其他常见方法
//filter过滤,虑去不符合条件的记录
map.filter(x => {
Integer.parseInt(x._1 + "") >= 2
}).foreach(println)
//count对符合条件的记录计数
val count = map.count(x => {
Integer.parseInt(x._1 + "") >= 2
})
println(count);
/* 对于filter和count中条件设置使用Integer.parseInt(x._1 + "")是因为:
* 定义map时,第一个key使用的是String类型,但在传入函数时每一个KV转化为一个二元组(Any,String)类型,x._1获取Any类型的值,+""将Any转化为String,最后再获取Int值进行判断.
*/
//contains判断是否包含某个key
println(map.contains(2))
//exist判断是否包含符合条件的记录
println(map.exists(x =>{
x._2.equals("Scala")
}))
5. 元组
元组是Scala中很特殊的一种集合, 可以创建二元组, 三元组, 四元组等等, 所有元组都是由一对小括号包裹, 元素之间使用逗号分隔.
元组与List的区别: list创建时如果指定好泛型, 那么list中的元素必须是这个泛型的元素; 元组创建后, 可以包含任意类型的元素.
创建元组即可使用关键字Tuple, 也可直接用小括号创建, 可以加 “new” 关键字, 也可不加. 取值时使用 "tuple._XX"获取元组中的值.
- 元组的创建和使用
//创建元组
val tuple = new Tuple1(1)
val tuple2 = Tuple2("zhangsan",2)
val tuple3 = Tuple3(1,2.0,true)
val tuple4 = (1,2,3,4)
val tuple18 = (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18)
//注意:使用Tuple关键字最多支持22个元素
val tuple22 = Tuple22(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)
//使用
println(tuple2._1 + "\t" + tuple2._2)
//元组中嵌套元组
val t = Tuple2((1,2),("zhangsan","lisi"))
println(t._1._2)
- 元组的遍历
//tuple.productIterator可以得到迭代器, 然后用来遍历
val tupleIterator = tuple22.productIterator
while(tupleIterator.hasNext){
println(tupleIterator.next())
}
- toString, swap方法
//toString, 将元组中的所有元素拼接成一个字符串
println(tuple3.toString())
//swap翻转,只对二元组有效
println(tuple2.swap)
trait特性
Scala中的trait特性相对于Java而言就是接口. 虽然从功能上两者极其相似, 但trait比接口还要强大许多: trait中可以定义属性和方法的实现, 这点又有点像抽象类; Scala的类可以支持继承多个trait, 从结果来看即实现多继承.
Scala中定义trait特性与类相似, 不同在于需要使用"trait"关键字. 其他注意点在代码注释中做出说明:
trait Read {
val readType = "Read"
val gender = "m"
//实现trait中方法
def read(name:String){
println(name+" is reading")
}
}
trait Listen {
val listenType = "Listen"
val gender = "m"
//实现trait中方法
def listen(name:String){
println(name + " is listenning")
}
}
//继承trait使用extends关键字,多个trait之间使用with连接
class Person extends Read with Listen{
//继承多个trait时,如果有同名方法或属性,必须使用“override”重新定义
override val gender = "f"
}
object test {
def main(args: Array[String]): Unit = {
val person = new Person()
person.read("zhangsan")
person.listen("lisi")
println(person.listenType)
println(person.readType)
println(person.gender)
}
}
object Lesson_Trait2 {
def main(args: Array[String]): Unit = {
val p1 = new Point(1,2)
val p2 = new Point(1,3)
println(p1.isEqule(p2))
println(p1.isNotEqule(p2))
}
}
trait Equle{
//不实现trait中方法
def isEqule(x:Any) :Boolean
//实现trait中方法
def isNotEqule(x : Any) = {
!isEqule(x)
}
}
class Point(x:Int, y:Int) extends Equle {
val xx = x
val yy = y
def isEqule(p:Any) = {
/*
* isInstanceOf:判断是否为指定类型
* asInstanceOf:转换为指定类型
*/
p.isInstanceOf[Point] && p.asInstanceOf[Point].xx==xx
}
}
模式匹配match-case
Scala中的模式匹配match-case就相当于Java中的switch-case. Scala 提供强大的模式匹配机制, 即可匹配值又可匹配类型. 一个模式匹配包含一系列备选项, 每个备选项都以case关键字开始. 并且每个备选项都包含了一个模式以及一到多个表达式, 箭头符号 => 隔开了模式和表达式。
object Lesson_Match {
def main(args: Array[String]): Unit = {
val tuple = Tuple7(1,2,3f,4,"abc",55d,true)
val tupleIterator = tuple.productIterator
while(tupleIterator.hasNext){
matchTest(tupleIterator.next())
}
}
/**
* 注意
* 1.模式匹配不仅可以匹配值,还可以匹配类型
* 2.模式匹配中,如果匹配到对应的类型或值,就不再继续往下匹配
* 3.模式匹配中,都匹配不上时,会匹配到case _ ,相当于default
*/
def matchTest(x:Any) ={
x match {
//匹配值
case 1 => println("result is 1")
case 2 => println("result is 2")
case 3 => println("result is 3")
//匹配类型
case x:Int => println("type is Int")
case x:String => println("type is String")
case x :Double => println("type is Double")
case _ => println("no match")
}
}
}
由于匹配到对应的类型或值时, 就不再继续往下匹配, 所有在编写备选项时要将范围小的放在前面, 否则就会失去意义. 这就类似于try-catch中处理异常时, 也要先从小范围开始.
样例类case classes
使用case关键字定义的类就是样例类(case classes), 样例类实现类构造参数的getter方法 (构造参数默认被声明为val) , 当构造参数类型声明为var时, 样例类会实现参数的setter和getter方法.
样例类默认实现toString, equals, copy和hashCode等方法. 样例类在创建对象时可new, 也可不new.
//使用case关键字定义样例类
case class Person(name:String, age:Int)
object Lesson_CaseClass {
def main(args: Array[String]): Unit = {
//创建样例类对象,可new可不new
val p1 = new Person("zhangsan",18)
val p2 = Person("lisi",20)
val p3 = Person("wangwu",22)
val list = List(p1,p2,p3)
list.foreach { x => {
x match {
case Person("zhangsan",18) => println("zhs")
case Person("lisi",20) => println("lisi")
case p:Person => println("is a person")
case _ => println("no match")
}
} }
}
}
并发 Actor Model
Actor Model相当于Java中的Thread, Actor Model用来编写并行计算或分布式系统的高层次抽象. Actor不需要担心多线程模式下共享锁的问题, 可用性极高.
Actors将状态和行为封装在一个轻量级的进程/线程中, 但它不和其他Actors分享状态, 每个Actors有自己的世界观, 当需要和其他Actors交互时, 通过发送异步的, 非堵塞的(fire-and-forget)事件和消息来交互. 发送消息后不必等另外Actors回复, 也不必暂停, 每个Actors有自己的消息队列, 进来的消息按先来后到排列, 这就有很好的并发策略和可伸缩性, 可以建立性能良好的事件驱动系统.
Actor的特征:
- ActorModel是消息传递模型,基本特征就是消息传递
- 消息发送是异步的,非阻塞的
- 消息一旦发送成功,不能修改 (类似发邮件)
- Actor之间传递时,自己决定决定去检查消息,而不是一直等待,是异步非阻塞的
定义Actor需要继承Actor这一trait, 实现act这一方法, 并且使用感叹号! 来发送消息.
一个简单实例:
import scala.actors.Actor
//自定义Actor
class myActor extends Actor{
def act(){
while(true){
receive {
case x:String => println("save String ="+ x)
case x:Int => println("save Int")
case _ => println("save default")
}
}
}
}
object Lesson_Actor {
def main(args: Array[String]): Unit = {
//创建actor的消息接收和传递
val actor =new myActor()
//启动
actor.start()
//发送消息写法
actor ! "Hello Scala Actor !"
}
}
Actor与Actor之间通信:
//创建样例类,用来发送
case class Message(actor:Actor,msg:Any)
class Actor1 extends Actor{
def act(){
while(true){
//对接收的消息进行模式匹配
receive{
case msg :Message => {
println("i sava msg! = "+ msg.msg)
//回复消息
msg.actor!"i love you too !"
}
case msg :String => println(msg)
case _ => println("default msg!")
}
}
}
}
//为了实现Actor中的通信,需要拿到另一个Actor的对象
class Actor2(actor :Actor) extends Actor{
//发送消息
actor ! Message(this,"i love you !")
def act(){
while(true){
receive{
case msg :String => {
if(msg.equals("i love you too !")){
println(msg)
actor! "could we have a date !"
}
}
case _ => println("default msg!")
}
}
}
}
object Lesson_Actor2 {
def main(args: Array[String]): Unit = {
val actor1 = new Actor1()
actor1.start()
val actor2 = new Actor2(actor1)
actor2.start()
}
}
Scala隐式转换系统
隐式转换是指在编写程序时, 尽量少的去编写代码, 让编译器去尝试在编译期间自动推导出某些信息来, 这就类似于在Scala中定义变量时不需要指定变量类型. 这种特性可以极大的减少代码量, 提高代码质量.
Scala中提供强大的隐式转换系统, 分别为: 隐式值, 隐式视图和隐式类.
- 隐式值
先来看一个隐式值的Demo:
object Lesson_Implicit1 {
def main(args: Array[String]): Unit = {
implicit val name = "Scala Study"
sayName
}
def sayName(implicit name:String) = {
println("say love to " + name)
}
}
这里将name变量声明为implicit, 编译器在执行sayName方法时发现缺少一个String类型的参数, 此时会搜索作用域内类型为String的隐式值, 并将搜索到的隐式值作为sayName的参数值进行传递.
需要注意:
- 隐式转换必须满足无歧义规则, 否则会报错:
ambiguous implicit values: both value a of type String and value name of type String match expected type String - 在同一个作用域禁止声明两个类型一致的变量,防止在搜索的时候会犹豫不决
- 声明隐式参数的类型最好是自定义的数据类型,一般不要使用Int,String这些常用类型,防止碰巧冲突.
- 隐式视图
隐式视图就是把一种类型自动转换为另一种类型. 还是先来看代码:
object Lesson_Implicit2 {
def main(args: Array[String]): Unit = {
//声明隐式视图
implicit def stringToInt(num:String) = Integer.parseInt(num)
println(addNum("1000"))
}
def addNum(num:Int) = { num + 1000 }
}
这里addNum方法参数是String类型, 不符合定义要求, 此时编译器搜索作用域发现有个隐式方法, 正好这个方法的参数是String, 返回是Int. 然后就会调用这个隐式方法, 返回一个Int值并将它传给addNum方法.
- 隐式类
隐式类是指把一个对象自动转换为另一种类型的对象, 转换后可以调用原来不存在的方法.
package com.qb.scala
object Lesson_Implicit3 {
def main(args: Array[String]): Unit = {
//导入隐式类所在的包
import com.qb.scala.Util.StringLength
println("qwer".getLength())
}
}
object Util {
//定义一个隐式类,使用implicit关键字修饰
implicit class StringLength(val s : String){
def getLength() = s.length
}
}
这里编译器在qwer对象调用getLength方法时, 发现该对象并没有getLength方法, 此时编译器发现在作用域范围内有隐式实体. 发现有符合的隐式类可以用来转换成带有getLength方法的Util类, 进而就可调用getLength方法.
需要注意:
- 隐式类所带的构造参数有且只能有一个
- 必须在类, 伴生对象和包对象中定义隐式类
- 隐式类不能是case class(样例类), case class 在定义时会自动生成伴生对象.
- 作用域中不能有与隐式类同名的标识符