一、类(class)新增的特性
1、default/delete 控制默认函数
在我们没有显式定义类的赋值构造函数和赋值操作符的情况下,编译器会为我们生成默认的这两个函数:默认的赋值函数以内存复制的形式完成对象的复制。
这种机制可以为我们节省很多编写复制构造函数和赋值操作符的时间,但是在某些情况下,比如我们不希望对象被复制,在之前我们需要将复制构造函数和赋值操作符声明为private,现在可以使用delete关键字实现:
class X {
// …
X& operator=(const X&) = delete; // 禁用类的赋值操作符
X(const X&) = delete;
};
显式地使用default关键字声明使用类的默认行为,对于编译器来说明显是多余的,但是对于代码的阅读者来说,使用default显式地定义复制操作,则意味着这个复制操作就是一个普通的默认的复制操作。
2、override/final 强制重写/禁止重写虚函数
派生类中可以不实现基类虚函数,也可以实现,但不使用virtual关键字;这很容易给人造成混淆,有时为了确认某个函数是否是虚函数,我们不得不追溯到基类查看;
C++11引入了两个新的标识符: override和final
override,表示函数应当重写基类中的虚函数。(用于派生类的虚函数中)
final,表示派生类不应当重写这个虚函数。(用于基类中)
struct B {
virtual void f();
virtual void g() const;
virtual void h(char);
void k(); // non-virtual
virtual void m() final;
};
struct D : B {
void f() override; // OK: 重写 B::f()
void g() override; // error: 不同的函数声明,不能重写
virtual void h(char); // 重写 B::h( char ); 可能会有警告
void k() override; // error: B::k() 不是虚函数
virtual void m(); // error: m()在基类中声明禁止重写
};
有了这对兄弟,我们的虚函数用起来更为安全,也更好阅读。
3、委托构造函数 Delegating constructor
在C++98中,如果你想让两个构造函数完成相似的事情,可以写两个大段代码相同的构造函数,或者是另外定义一个init()函数,让两个构造函数都调用这个init()函数。例如:
class X {
int a;
// 实现一个初始化函数
validate(int x) {
if (0<x && x<=max) a=x; else throw bad_X(x);
}
public:
// 三个构造函数都调用validate(),完成初始化工作
X(int x) { validate(x); }
X() { validate(42); }
X(string s) {
int x = lexical_cast<int>(s); validate(x);
}
// …
};
这样的实现方式重复罗嗦,并且容易出错。在C++11中,我们可以在定义一个构造函数时调用另外一个构造函数:
class X {
int a;
public:
X(int x) { if (0<x && x<=max) a=x; else throw bad_X(x); }
// 构造函数X()调用构造函数X(int x)
X() :X{42} { }
// 构造函数X(string s)调用构造函数X(int x)
X(string s) :X{lexical_cast<int>(s)} { }
// …
};
4、继承的构造函数 Inheriting constructor
C++11提供了将构造函数晋级的能力,比如以下这个示例,基类提供一个带参数的构造函数,而派生类没有提供;如果直接使用D1 d(6);将会报错;通过将基类构造函数晋级,派生类中会隐式声明构造函数D1(int);需要注意的是,晋级后的基类构造函数是无法初始化派生类的成员变量的,所以如果派生类中有成员变量,需要使用初始化列表初始化。
struct B1 {
B1(int) { }
};
struct D1 : B1 {
using B1::B1; // 隐式声明构造函数D1(int)
// 注意:在声明的时候x变量已经被初始化
int x{0};
};
void test()
{
D1 d(6); // d.x的值是0
}
5、类内部成员的初始化 Non-static data member initializers
在C++98标准里,只有static const声明的整型成员能在类内部初始化,并且初始化值必须是常量表达式。这些限制确保了初始化操作可以在编译时期进行。
class X {
static const int m1 = 7; // 正确
const int m2 = 7; // 错误:无static
static int m3 = 7; // 错误:无const
static const string m5 = “odd”; //错误:非整型
};
C++11的基本思想是,允许非静态(non-static)数据成员在其声明处(在其所属类内部)进行初始化。这样,在运行时,需要初始值时构造函数可以使用这个初始值。现在,我们可以这么写:
class A {
public:
int a = 7;
};
//它等同于使用初始化列表
class A {
public:
int a;
A() : a(7) {}
};
单纯从代码来看,这样只是省去了一些文字输入,但在有多个构造函数的类中,其好处就很明显了:
class A {
public:
A(): a(7), b(5), hash_algorithm(“MD5″),
s(“Constructor run”) {}
A(int a_val) :
a(a_val), b(5), hash_algorithm(“MD5″),
s(“Constructor run”)
{}
A(D d) : a(7), b(g(d)),
hash_algorithm(“MD5″), s(“Constructor run”)
{}
int a, b;
private:
// 哈希加密函数可应用于类A的所有实例
HashingFunction hash_algorithm;
std::string s; // 用以指明对象正处于生命周期内何种状态的字符串
};
可以简化为:
class A {
public:
A() {}
A(int a_val) : a(a_val) {}
A(D d) : b(g(d)) {}
int a = 7;
int b = 5;
private:
//哈希加密函数可应用于类A的所有实例
HashingFunction hash_algorithm{“MD5″};
//用以指明对象正处于生命周期内何种状态的字符串
std::string s{“Constructor run”};
6、移动构造和移动赋值
在C++98中,我们自定义的类,会默认生成拷贝赋值操作符函数和拷贝赋值函数以及析构函数。
在C++11中,依赖于新增的move语义,默认生成的函数多了2个移动相关的:移动赋值操作符( move assignment )和移动构造函数( move constructor );
所以,如果你显式声明了上述 5 个函数或操作符中的任何一个,你必须考虑其余的 4 个,并且显式地定义你需要的操作,或者使用这个操作的默认行为。
一旦我们显式地指明( 声明 , 定义 , =default , 或者 =delete )了上述五个函数之中的任意一个,编译器将不会默认自动生成move操作。
一旦我们显式地指明( 声明 , 定义 , =default , 或者 =delete )了上述五个函数之中的任意一个,编译器将默认自动生成所有的拷贝操作。但是,我们应该尽量避免这种情况的发生,不要依赖于编译器的默认动作。
如果你声明了上述 5 个默认函数中的任何一个,强烈建议你显式地声明所有这 5 个默认函数。例如:
template<class T>
class Handle {
T* p;
public:
Handle(T* pp) : p{pp} {}
// 用户定义构造函数: 没有隐式的拷贝和移动操作
~Handle() { delete p; }
Handle(Handle&& h) :p{h.p}//移动构造函数
{ h.p=nullptr; }; //传递所有权
Handle& operator=(Handle&& h)//移动赋值操作符
{ delete p; p=h.p; h.p=nullptr; } // 传递所有权
Handle(const Handle&) = delete; // 禁用拷贝构造函数
Handle& operator=(const Handle&) = delete;//禁用赋值操作符
// ...
};
二、移动语义和右值引用
C++11的一个最主要的特性就是可以移动而非拷贝对象的能力。很多情况都会发生对象的拷贝,有时对象拷贝后就立即销毁,在这些情况下,移动而非拷贝对象会大幅度提升性能。
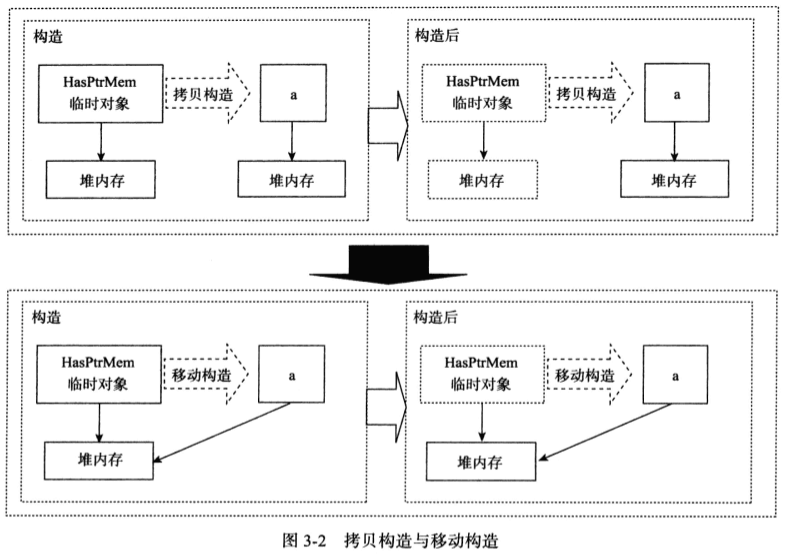
右值与右值引用
为了支持移动操作,新标准引入了一种新的引用类型——右值引用,就是必须绑定到右值的引用。我们通过&&而不是&来获得右值引用。右值引用一个重要的特性就是只能绑定到将要销毁的对象。
左值和右值是表达式的属性,一些表达式生成或要求左值,而另一些则生成或要求右值。一般而言,一个左值表达式表示的是一个对象的身份,而右值表达式表示的是对象的值。(可以取地址的、有名字的就是左值;不能取地址的、没有名字的就是右值。)两者明显的区别就是左值有持久的状态,而右值要么是字面常量,要么是在表达式求值过程中创建的临时对象。
类似于常规引用(左值引用),一个右值引用也不过是某个对象的另一个名字而已。我们不能将左值引用绑定到要求转换的表达式、字面常量或是返回值的表达式,也不能把右值应用直接绑定到一个左值上。但是,常量左值引用可以绑定到非常量左值、常量左值、右值,是一个万能引用类型。不过相比右值引用所引用的右值,常量左值引用所引用的右值是只读的。
int i = 42;
int &r = i; //r引用i
int &r2 = i*2; //错误,i*2是一个右值
int &&rr = i; //错误,不能将一个右值引用绑定到一个左值上
int &&rr2 = i*2; //正确,将rr2绑定到一个乘法结果上
const int &r3 = i*2; //正确,将一个常量左值引用绑定到一个右值上
变量可以看做只有一个运算对象而没有运算符的表达式,是一个左值。我们不能将一个右值引用直接绑定到一个变量上,即使这个变量是右值引用类型。但是,我们可以通过新标准库中的move函数来获得绑定到左值上的右值引用。
int &&rr3 = std::move(rr2);//rr2是一个左值,而rr3是一个右值引用
注意,被转化的左值,其生命周期并没有随着左右至的转化而改变,在转换之后使用左值可能造成运行时错误。因此,调用move就意味着承诺:除了对原左值变量赋值或销毁它外,我们将不再使用它。不过更多的时候,我们需要转换成右值引用的还是一个确实生命周期即将结束的对象。
移动构造函数和移动赋值运算符
为了让自定义类型也支持移动操作,需要为其定义移动构造函数和移动赋值运算符。这两个成员类似对应的拷贝操作,但它们从给定对象窃取资源而不是拷贝资源。类似于拷贝构造函数,移动构造函数的第一个参数是该类类型的一个右值引用,任何额外的参数都必须有默认实参。除了完成资源移动外,移动构造函数还必须确保移后源对象处于有效的、可析构的状态。
#include <iostream>
#include <algorithm>
class MemoryBlock {
public:
// 构造函数
explicit MemoryBlock(size_t length)
: _length(length)
, _data(new int[length])
{}
// 析构函数
~MemoryBlock()
{
if (_data != nullptr) delete[] _data;
}
// 拷贝赋值运算符
MemoryBlock& operator=(const MemoryBlock& other)
{
if (this != &other)
{
delete[] _data;
_length = other._length;
_data = new int[_length];
std::copy(other._data, other._data + _length, _data);
}
return *this;
}
// 拷贝构造函数
MemoryBlock(const MemoryBlock& other)
: _length(0)
, _data(nullptr)
{
*this = other;
}
// 移动赋值运算符,通知标准库该构造函数不抛出任何异常(如果抛出异常会怎么样?)
MemoryBlock& operator=(MemoryBlock&& other) noexcept
{
if (this != &other)
{
delete[] _data;
// 移动资源
_data = other._data;
_length = other._length;
// 使移后源对象处于可销毁状态
other._data = nullptr;
other._length = 0;
}
return *this;
}
// 移动构造函数
MemoryBlock(MemoryBlock&& other) noexcept _data(nullptr) , _length(0)
{
*this = std::move(other);
}
size_t Length() const
{
return _length;
}
private:
size_t _length; // The length of the resource.
int* _data; // The resource.
};
只有当一个类没有定义任何自己版本的拷贝控制成员,且类的每个非static数据成员都可移动时,编译器才会为它合成移动构造函数会移动赋值运算符。编译器可以移动内置类型;如果一个类类型有对应的移动操作,编译器也能移动这个类型的成员。此外,定义了一个移动构造函数或移动赋值运算符的类必须也定义自己的拷贝操作;否则,这些成员默认地定义为删除的。而移动操作则不同,它永远不会隐式定义为删除的。但如果我们显式地要求编译器生成=defualt的移动操作,且编译器不能移动所有成员,则编译器会将移动操作定义为删除的函数。
如果一个类既有移动构造函数又有拷贝构造函数,编译会使用普通的函数匹配规则来确定使用哪个构造函数。但如果只定义了拷贝操作而未定义移动操作,编译器不会合成移动构造函数,此时即使调用move来移动它们,也是调用的拷贝操作。
class Foo
{
public:
Foo() = default;
Foo(const Foo&); // 为定义移动构造函数
};
Foo x;
Foo y(x); //调用拷贝构造函数
Foo z(std::move(x)); //调用拷贝构造函数,因为未定义移动构造函数
三、包装器
C++11提供了多个包装器(wrapper,也叫适配器[adapter])。这些对象用于给其他编程接口提供更一致或更合适的接口;包括模板bind、mem_fn和reference_wrapper以及包装器function,其中模板bind可以替代bind 1st和bind2nd(bind1st和bind2nd使得接受这两个参数的函数能够与这样的STL算法匹配,即它要求将接受一个参数的函数作为参数),当更灵活;模板mem_fn让我们能够将成员函数作为常规函数进行传递;模板reference_wrapper让我们能够创建行为行为像引用当可被复制的对象;而包装器function让我们能够以统一的方式处理多种类似于函数的形式。这里我们重点对函数对象包装器function进行介绍。
函数对象包装器function
function 是一种通用、多态的函数封装,它的实例可以对任何可以调用的目标实体进行存储、复制和调用操作,它也是对 C++中现有的可调用实体的一种类型安全的包裹(相对来说,函数指针的调用不是类型安全的),换句话说,就是函数的容器。当我们有了函数的容器之后便能够更加方便的将函数、函数指针作为对象进行处理。
函数对象包装器的特点:
1.设计通用的函数执行接口,可以设置计数(函数执行次数)和关卡
2.函数包装器依赖于函数模板,实现通用泛型
3.函数代码可以内嵌在函数中
4.原理是函数指针实现的
【示例】
#include<iostream>
#include<functional>
using std::cout;
using std::endl;
using std::cin;
using std::function;
//定义好了一个函数包装器
template < typename T, typename F>
T function_wrapper(T t, F fun)
{
return fun(t);
}
//定义好了一个函数包装器
template < typename T, typename F>
T function_wrapper(T t1, T t2,F fun)
{
static int count = 0;
count++;
cout << "函数包装器执行" << count << "次数" << endl;
return fun(t1,t2);
}
void main()
{
double d_num = 1.1;
//double(double)是声明函数类型
//允许函数内嵌
//本质是函数指针
// [] 标识要开辟一个函数
function<double(double)> square_fun = [](double in_data)
{
return in_data*in_data;
};
//
function<double(double)> cube_fun = [](double in_data)
{
return in_data*in_data*in_data;
};
function<int(int,int )> add_fun = [](int in_data1,int in_data2)
{
return in_data1+in_data2;
};
cout << function_wrapper(d_num, square_fun) << " " << function_wrapper(d_num, cube_fun) << endl;
cout << function_wrapper(1,2,add_fun) << endl;
cin.get();
}