代理和cookie操作
一.基于requests模块的cookie操作
引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们想要的目的,例如:
cookie会话跟踪技术,服务端产生发给客户端保存,再次访问服务器,浏览器就携带这个cookie,让服务器识别客户端浏览器
爬取张三用户的豆瓣网的个人主页页面数据--没有测试成功
- cookie:基于用户的用户数据
- 需求:爬取张三用户的豆瓣网的个人主页页面数据
- cookie作用:服务器使用cookie来记录客户端的状态信息
实现流程:
1.执行登录操作(获取cookie)
2.发起个人主页请求时,需要将cookie携带到该请求中
注意:session对象
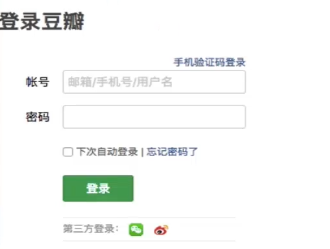

import requests session = requests.session() # 1.发起登录请求:将cookie获取,切换存储到session对象中 login_url = 'https://accounts.douban.com/login' # post 请求 ---data参数 data = { 'source':'movie', 'redir':'https://movie.douban.com/', 'form_email':'', 'form_password':'', 'login':'登录', } headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} # 使用session发起请求 login_response = session.post(url=login_url,data=data,headers=headers) # 2.发起个人主页请求(session(cookie)),获取响应页面数据 url = 'https://www.douban.com/people/188197188/' response = session.get(url=url,headers=headers) page_text = response.text with open('./douban110.html','w',encoding='utf-8')as f: f.write(page_text)
代理操作
- 1.代理:第三方代理本体执行相关的事务。生活:代购
- 2.为什么要使用代理
- 反爬操作,非正常访问的ip禁止
- 反反爬手段--设置爬虫的代理ip
- 3.分类:
- 正向代理:代替客户端获取数据--爬虫客户端程序-正向代理
- 反向代理:代理服务器端提供数据
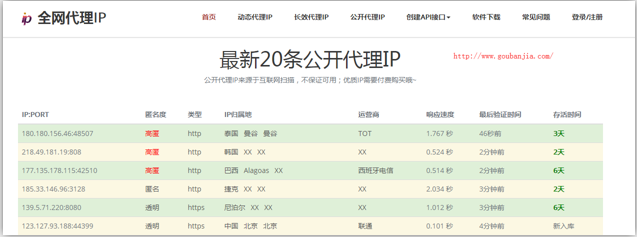
- 4.免费代理ip的网站提供商
- www.goubanjia.com 推荐
- 快代理
- 西祠代理
- 5.代码
----------------------------------------------------------
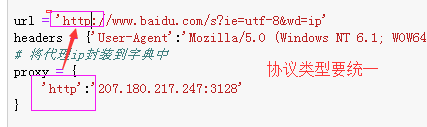
import requests url = 'http://www.baidu.com/s?ie=utf-8&wd=ip' headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} # 将代理ip封装到字典中 proxy = { 'http':'112.25.6.26:80' } # 更换网络ip,发起请求之前 response = requests.get( url=url,proxies=proxy,headers=headers) with open('./daili.html','w',encoding='utf-8')as f: f.write(response.text)
执行后结果:

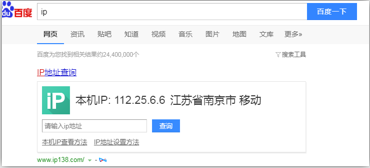
验证处理--打码平台
登陆的次数过多就会出现验证码