转 https://blog.csdn.net/qq_31179577/article/details/76585854
PS:文章还在写,目前都是一些概念性质的,想要做拓展的程序猿请过几天再看,Drools会一致做完的~~~
1. 工欲善其事,必先利其器
Drools提供基于eclipse的IDE(这是可选的),但其核心只需要Java 1.5(Java SE)。
1.1 GEF安装
Open the Help→Software updates…→Available Software→Add Site… from the help menu.
Location is:
http://download.eclipse.org/tools/gef/updates/releases/PS:1.需要梯子
2.官方文档给的截图与目前版本差距太大,所以建议全安了吧。。。。
3.挺慢的
2. 简介
2.1 模块功能
Drools被分解成几个模块,下面是组成JBoss Drools的重要库的描述 :
| jar | 作用 |
|---|---|
| knowledge-api.jar | 这提供了接口和工厂。它还有助于清楚地显示什么是用户API,什么是引擎API |
| knowledge-internal-api.jar | 这提供了内部接口和工厂 |
| drools-core.jar | 他是核心引擎,运行时组件。包含RETE引擎和LEAPS引擎。如果您正在预编译规则(并通过包或RuleBase对象进行部署),这是惟一的运行时依赖性。 |
| drools-compiler.jar | 它包含编译器/构建器组件,以获取规则源,并构建可执行的规则库。这通常是应用程序的运行时依赖性,但如果您预先编译了规则,则不必如此。这取决于drools-core。 |
| drools-jsr94.jar | 这是jsr- 4兼容实现,这实质上是drools编译器组件的一个层。注意,由于jsr-94规范的性质,并不是所有特性都很容易通过这个接口公开。在某些情况下,直接使用Drools API比较容易,但是在某些环境中,jsr-94是强制执行的。 |
| drools-decisiontables.jar | 这是决策表的编译器组件,它使用drools编译器组件。这支持excel和CSV输入格式。 |
2.2 依赖文件
Maven pom.xml文件
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-bom</artifactId>
<type>pom</type>
<version>...</version>
<scope>import</scope>
</dependency>
...
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.kie</groupId>
<artifactId>kie-api</artifactId>
</dependency>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-compiler</artifactId>
<scope>runtime</scope>
</dependency>
...
<dependencies>3.what?
3.1 规则执行生命周期
规则引擎优化了对条件的评估,并确保了我们可以以最快的方式确定命中的规则。然而, 除非我们指定,否则规则引擎不会在条件检测时立即执行我们的业务规则 。当我们到达一个点时,我们发现一个规则对一组数据的评估是对的,那么规则和触发数据被添加到列表中。这是一个明确的规则生命周期的一部分,我们在规则评估与和规则执行之间有一个清晰的划分。规则评估将会添加规则操作和触发的数据到一个组件之中。我们称这个组件是Agenda(议程)。规则执行是在命令中执行的。当我们通知规则引擎的时候,它应该会触发我们议程上的所有的规则。
如前所述,我们不控制将要被命中的规则。而是根据我们创建的业务规则和我们为引擎提供的数据来确定这一点,但这其实是引擎的责任。但是,一旦引擎决定了应该命中的业务规则,我们可以控制它们执行命中的事件。这是通过对规则引擎的方法调用完成的。
一旦规则被触发,每条规则将被执行。规则的执行可能会修改我们领域数据,然后这些更改如果引发了与新数据相匹配业务规则,新的规则将会被加入进Agenda(议程)中,或者如果这些修改导致匹配结果不再正确,那么它将被取消。这个完整的循环将继续下去,直到对于可用数据没有更多的规则在议程中可用或规则引擎执行被迫停止。下面的图 显示该工作流是如何执行的:
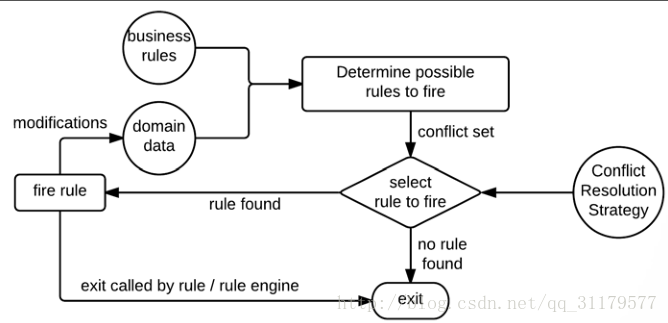
这个执行生命周期将继续执行规则引擎根据决定根据规则的定义和域数据所决定的添加到议程中的所有的所有规则。有些规则可能不会触发,有些规则可能会多次触发。
3.2 why?
对于我们的业务规则的匹配而言。以传统的命令式编码(即我们java代码条件判断等),如果业务规则发生了变化,我们需要重新从头缕逻辑,然后在合适的地方添加/删除、修改我们的条件判断。这带来就是业务逻辑的捆绑以及不可预知的Bug。而Drools提倡的是声明式编程,我们只需要像做流水线一样,单独做自己的业务规则即可,每个业务规则均是独立的,类似的,可以想象为if/else if/else变为了插拔式的多个if判断。
3.3 how?
以领域驱动角度来谈我们的领域层,其实最神秘的是业务逻辑与规则。比如移动的积分制度,保险的保金等等,他们都是与行业有关的知识。作为一个技术精湛的我们,也无法充分想到这些业务规则的边边角角。但是领域专家知道这些业务规则,可惜他们不会编程。
SO.BRMS(业务规则管理系统)就是以友好的方式,来使得领域专家书写规则。
4. 规则引擎的算法、
tell me:业务规则是如何执行的
规则引擎通过特定的算法将我们定义的业务规则转换为可执行决策树。执行树的性能 将取决于算法生成的优化机制。是Drools6框架定义了自己的算法,专注于更高的性能。这个算法被称为PHREAK,由Mark Proctor创建。它是基于一种叫做RETE的预先存在的算法的一系列优化和重新设计的。作为开放源码实现,PHREAK是最高效、最有效的算法之一。
在生成的执行树中,规则中的每个条件都将被转换为树中的一个节点,以及再我们的规则中,不同的条件如何相互连接,将决定这些节点的连接方式。当我们在规则引擎中添加数据时 ,它将被批量评估,通过网络使用最优化的路径。当数据到达代表了被触发的规则的叶子时,执行树完成。这些规则被添加到一个列表中,调用一个命令将会被要求触发所有的规则或一组规则。
每次我们向规则引擎添加更多数据时,它都是通过执行树的根元素引入的。执行树的每一个优化都是根据 以下两个主要焦点:
1.它会试图将所有的条件分解为最小的单位 要尽可能多地重用执行树
2.它将尝试只进行一个操作,以达到下一个级别,直到它得到了一个false的条件评估或者执行到了页节点上,在一个被标记为执行的规则上。
每一个数据都以可能的最有效的方式进行评估。这些评估的优化是规则引擎的主要关注点
4.1 什么时候使用规则
什么样的项目适合将DFrools加入到技术站中??
1.他们定义了一个非常复杂的场景,甚至对于业务专家都很难完全定义
2.他们没有已知的或定义明确的算法解决方案
3.他们有挥发性的要求和需要经常更新
4.他们需要快速做出决定,通常是基于部分数据
其实你会发现,除了已经基本定型收工的项目,我们都可以将Drools加入技术栈
4.2 复杂的场景,简单的规则
每隔一段那时间,我们会发现系统-或者是系统的一部分-组件间的小关系 开始变得越来越多,越来越重要。起先,他们可能看起来是无害的组件,只是依据两三个数据源来做一些业务判定。但是当以后我们再看它的时候,这些关系变得复杂了,而且也很重要。最终,我们可能 发现各部分之间的关系产生了更多的集体行为,甚至业务专家没有意识到可能发生的事情;然而,这仍然是有意义的。这些系统被称为复杂系统,它们是商业规则提供巨大帮助的地方之一。
复杂的场景通常由小的语句来定义。这个完整图,涉及到完全定义场景所需的每一个组合、聚合或抽象,通常是超出我们最初的理解。因此,这类系统开始通过部分解释来定义是很常见的。系统中的每个小关系都被定义为不同的 要求。当我们分析这些要求的每一个,把它们分开 在最基本的元素中,我们发现自己定义了业务规则。
每个业务规则有助于定义复杂场景中的每一个小组件。随着越来越多的规则被添加到系统中,越来越多的这些关系可以以一种简单的方式来处理。没一个规则都变为了系统在执行复杂场景时需要执行的每一个小的决策服务的自解释的手册。
复杂应用程序的例子可以非常多种多样,如下所示:
Fraud detection systems欺诈检测系统
为客户定制零售优惠券:
信用评分的软件
4.3 不断变化的场景
参与做出一个特定的决定的要素往往会发生频繁的变化,业务规则对于管理系统行为的这种波动,可以是一个很好的解决方案。
业务规则在规则引擎中表示为数据树。同样地,我们可以修改列表的元素,我们可以从业务规则里移除或者新加业务规则。这可以实现不重启项目和重新发布部署任何组件。Drools内部机制可以自动的更新规则。Drools 6提供的工具也准备为业务规则提供来自用户友好编辑器的更新机制。Drools 6 API的完整架构是基于尽可能的自适应的。
如果我们发现一个系统,需求可能经常发生变化,即使是在每天或每小时的频率,业务规则可能是最适合这些需求的,由于它的更新能力,而不管系统的复杂性。
4.4 网上商店example
首先,我们将定义我们的eShop系统的模型。该模型将包含所有与我们的申请有关的决策。 其中一些对象如下所示:
| Domain | 业务知识 |
|---|---|
| Product | 我们店里想要出售不同种类的项目.每种类型都将由一个产品对象来表示,其中包含特定项目的详细信息。 |
| Stock | 这是我们储存的每一种产品的数量。 |
| Provider | 我们的产品来自不同的供应商。每一个供应商以特定的交付能力,为eShop提供特定种类的产品。 |
| Provider Request | 当我们的运行了一段时间,某些商品已经过时或者昆村不够时候,我们需要创建请求,来让为提供商填充我们的库存 |
| Client | 当客户在我们的eShop中喜欢一个或多个产品时,他们可以订购并支付他们。订单有不同的状态,取决于是否客户成功地收到了它。他们也有关于具体产品它的信息及其数量。 |
| Discount | 网店提供不同的折扣,取决于购买的类型 |
| Sales channel | 我们将模拟的eShop可以使用多个网站,每个站点都被视为不同的销售渠道。每个销售渠道将有它自己的特定目标受众,这是由使用它的客户决定的 |
在项目中,我们需要做到的是:
1.将产品与每个销售渠道相关联并将其与其他销售渠道进行比较,来为特定种类的产品定义最佳销售渠道。依托于这些信息,我们可以为不同渠道的穿品创建自定义的折扣
2.定义特定产品的客户机首选项。依托于这些信息,我们可以为他们提供适合他们特定口味的折扣票。
3.确定特定产品的平均消费,并与我们的库存进行比较。一旦需要的话,我们可以自动的触发供应商请求来发货。
4.根据我们对具体供应商的订单数量,我们可以去争取一个价格的折扣
5.我们可以分析客户在eShops中所购买的不同商品。 如果,在某个时候,购买超出了我们认为的正常范围,我们可以 采取一系列行动,从一个简单的警告,到为特定的购买提供直接的人类支持。
4.5 if not
1.在这个项目中,很少有独立的规则:如果在需求收集中确定的业务规则非常简单,并且最多可以跨越一个或两个对象,我们不需要一个规则引擎来运行他们
2.业务逻辑不会经常改变:
3.对于应用程序来说,非常严格的执行流控制至关重要:当我们执行业务规则的时候,没有提供一个序列流控制。如果业务规则背后的业务逻辑有很大的依赖关系,对于业务规则需要按顺序执行的严格步骤, 那么规则引擎可能不合适。然而,如果它经常发生变化,可能是商业过程是值得考虑的。
下一节讲书写和执行规则
5. 环境配置
1.jdk 1.8
2.maven 3.1 above
3.Git 1.9 above
5.1 创建第一个Drools项目
1.地址:
git clone https://bitbucket.org/drools-6-developer-guide/drools6-dev-guide.git2.Eclipse导入项目二,不会的话,请关掉电脑,该干嘛干嘛去。。
3.首先看pom文件,
<dependencies>
<dependency>
<groupId>org.kie</groupId>
<artifactId>kie-api</artifactId>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-compiler</artifactId>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.drools</groupId>
<artifactId>drools-core</artifactId>
<type>jar</type>
</dependency>
//上面的jar功能在第二节里都讲了~~
//为了开始编写我们自己域的规则,我们还需要添加一个依赖。下面这个依赖定义了由该域模型提供的域模型,这个在上一节我们也讲过:
<dependency>
<groupId>org.drools.devguide</groupId>
<artifactId>model</artifactId>
<type>jar</type>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
</dependencies> 4./src/main/resources/META-INF/kmodule.xml
这个文件将被用于配置如何加载规则引擎中项目中定义的规则。就目前而言, kmodule.xml的内容将非常简单,因为我们将使用所有的缺省值配置。下节我们会讲解如果配置这个文件
5.项目的阻止结果已经确定了,我们现在来书写和运行我们的第一个规则。
①在src/main/resources文件下创建文本,这个文件可不是text文件,文件拓展名以.drl标识。这样它就可以被当作一个规则文件
②文件的抬头与java文件相似,分别是package和import
package myfirstproject.rules
import org.drools.devguide.eshop.model.Item;
import org.drools.devguide.eshop.model.Item.Category;
rule "Classify Item - Low Range"
when
$i: Item(cost < 200)
then
$i.setCategory(Category.LOW_RANGE);
end这条规则检查每一项成本低于200美元并自动以一个类别标记这个项目 。在这种情况下, 是将其标识以LOW_RANGE类别。对于我们的商店来说,区分不同种类的商品是有意义的,这样我们就可以为他们应用不同的折扣和营销策略。这个分类过程可以自动地使用规则来完成,这些规则集中了我们对LOW_RANGE、MID_RANGE或HIGH_RANGE项目的业务定义的点。
一般来说,这些文件的结构如下:
package定义
import
(可选的)声明的类型和事件
Rules: (1..N)/Queries (1..N)
③执行测试
public static void main( String[] args )
{
System.out.println( "Bootstrapping the Rule Engine ..." );
// Bootstrapping a Rule Engine Session
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.getKieClasspathContainer();
KieSession kSession = kContainer.newKieSession();
Item item = new Item("A", 123.0,234.0);
System.out.println( "Item Category: " + item.getCategory());
kSession.insert(item);
int fired = kSession.fireAllRules();
System.out.println( "Number of Rules executed = " + fired );
System.out.println( "Item Category: " + item.getCategory());
}正如您在前面的示例中看到的,有三个主要阶段,如下所示以下几点:
- 引导规则引擎会话: KieServices /KieContainer /KieSession的职责,我们会在下一节里讲。现在,我们只需要知道KieSession代表了一个具有指定配置和一系列规则的规则引擎的运行时实例。它掌握了与我们域对象的规则相匹配的评估算法
- 让规则引擎知道我们的数据:我们负责把所有的信息都提供给引擎,这样它就可以操作。为了做到这一点,我们在KieSession上使用了insert()方法。我们也可以使用delete()从规则引擎上下文删除信息方法或使用modify()方法更新信息。
- 如果我们提供的信息与一个或多个定义的规则相匹配,我们就就会得到匹配结果。调用fireAllRules()方法将执行这些匹配操作。在下一节,Drools运行时,我们将学习更多的匹配。
5.2 使用CDI引导规则引擎
Contexs and Dependency Injection (CDI) (网站 http://www.cdi-spec.org),是一组标准化的api,用于为我们的应用程序提供这些特性,因为它允许我们选择我们所要的上下文和依赖注入容器。CDI现在已经成为Java SE规范的一部分,它的应用正在每年增长。由于这个原因,由于Drools项目增加了很多支持 CDI环境,本节简要介绍如何简化我们的Hello World 我们在上一节中所写的例子。
为了在我们的项目中使用CDI,我们需要在我们的项目中添加一些依赖项 项目,如下:
<dependencies>
....上述的jar,不列举了.....
<dependency>
<groupId>javax.enterprise</groupId>
<artifactId>cdi-api</artifactId>
</dependency>
<dependency>
<groupId>org.jboss.weld.se</groupId>
<artifactId>weld-se-core</artifactId>
</dependency>
</dependencies>javax.enterprise:cdi-api包含CDI规范中定义的所有接口
org.jboss.weld.se:weld-se-core包含我们将使用实现CDI接口的工具
通过添加了这两个jar,我们可以在项目中使用@Inject注解,来注入KieSession,Weld容器将负责为我们提供规则引擎。
CDI的工作原理基于约定优于配置,它引入了添加新文件的需要,文件放在 src/main/resources/META-INF下的bean.xml文件,用于配置容器如何在项目和其他配置中访问我们的bean。请注意与我们之前介绍过的文件kmodule. xml的相似性 。这是一个空的beans.xml的示例内容文件,CDI容器使用该文件了解需要解析的jar 将容器提供给@inject注入的bean,如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/beans_1_0.xsd">
</beans>一旦我们有了容器的依赖项和beans.xml文件,容器可以扫描类路径(即我们的项目及其依赖项) 寻找要注入的bean,我们可以在应用程序中使用这些特性。
下面的类表示创建默认KieSession的同一个简单示例,然后与它交互。
下面的代码片段通过CDI初始化KieSession并与它交互, 如下:
public class App
{
@Inject
@KSession("") // This is not working track: https://issues.jboss.org/browse/DROOLS-755
// it should be @KSession() for the default session
KieSession kSession;
public void go(PrintStream out){
Item item = new Item("A", 123.0,234.0);
out.println( "Item Category: " + item.getCategory());
kSession.insert(item);
int fired = kSession.fireAllRules();
out.println( "Number of Rules executed = " + fired );
out.println( "Item Category: " + item.getCategory());
}
public static void main( String[] args )
{
Weld w = new Weld();
WeldContainer wc = w.initialize();
App bean = wc.instance().select(App.class).get();
bean.go(System.out);
w.shutdown();
}
}注意,main(…)方法现在正在引导Weld容器,由于这个原因,我们的bean(App)可以注入任何bean。在本例中,@ksession注释负责引导引擎并为其创建一个新的实例 提供给我们使用。我们将看第3章中CDI扩展所提供的注解。
将此视为与Drools规则引擎交互的另一个非常有效的选项。 如果您正在使用一个Java EE容器,比如WildFly AS(http://www.wildfly.org/),它是建立在纯粹基于CDI的核心之上的,那么这种方式使可以使用的。
在本例中,我们使用WELD,他是CDI的参考实现。注意,您可以使用任何其他CDI实现,例如在 http://openwebbeans.apache.org中打开Apache Open Web Beans。
现在,为了了解规则是如何被应用和执行的,我们应该清楚地理解我们用来写规则的语言,我们称呼它叫做Drools规则语言(DRL)。下面的部分将从不同角度更详细的介绍语言。下一节将更详细地介绍执行方面,当我们引导规则引擎会话时,以及如何为不同的目的配置它时,解释了正在发生的事情。
5.3 规则语言
PS:参考项目为chapter-02-kjar
正如之前所属的,规则是由条件和结果组成的
rule "name"
when
(Condition条件)--通常也叫做左手边的规则(LHS)
then
(Actions/Consequence)--通常也叫做右手边的规则(RHS)
end规则的LHS–条件,是根据DRL语言来编写的(文件名都是.drl结尾。。。),为了简单起见不会完全解释。我们会在样例里看到最常用的一些DRL语言结构,我们会尽可能多地使用语言。你可以通过下面的地址来学习完整详细的语言结构:
https://docs.jboss.org/drools/release/7.1.0.Final/drools-docs/html_single/index.html#DroolsLanguageReferenceChapter- 1
规则的LHS由条件元素组成,它们充当过滤器,定义规则来评估真正的满足的条件。这个条件元素过滤事实(即insert方法传入的对象数据),在我们的例子中是我们在Java中工作的对象实例。
如果你看我们第一条规则的LHS,那个条件表达式非常简单,如下:
rule "Classify Item - Low Range"
when
$i: Item(cost < 200)
then
$i.setCategory(Category.LOW_RANGE);
endLHS可以划分为三部分:
- Item(…)是为Item类型的对象的过滤器。这个过滤器会拿起所有我们以insert方法进session中的item对象用于进行处理。
- cost<200这个过滤器将会看一看每个item对象,确保cost属性有一个值且小于200
- i表示一个变量绑定,它用于以后引用匹配的对象。注意,我们使用
- 符号来命名变量,这样我们就能很容易地与对象字段对比中识别出它们。这是好的做法。
综上所述,我们基于对象及其属性进行过滤。重要的是要理解,我们将过滤与这些条件匹配的对象实例。对于每一个对所有条件求真值的项目实例,规则引擎将创建一个匹配结果。
更复杂的规则可能是根据他们的订单的大小来对我们的客户进行分类。新规则和前一条规则有很大区别,现在的规则将需要评估订单和客户。看一下规则是:
rule "Classify Customer by order size"
when
$o: Order( orderLines.size >= 5, $customer: customer ) and
$c: Customer(this == $customer, category == Customer.Category.NA)
then
modify($c){
setCategory(Customer.Category.SILVER)
};
end 在这个规则里,我们正在对订单数量超过5条的订单进行评估,即表示五个不同的物品。然后,我们查找与这个订单管理关联的消费者,并设置这个消费者的类别。消费者和订单之间的关系是通过将订单对象中的客户引用绑定到一个叫做customer的变量,并通过下面的步骤来比较我们正在评估的客户−>Customer(this==
customer…).条件元素的顺序只由我们需要的绑定定义.在这种情况下,我们将Order.getCustomer()拿来去匹配消费者。但是,我们也可以用另一种方法来做,它会以同样的方式工作,如下所示:
$c:Customer(category == Customer.Category.NA)
$o:Order(orderLines.size >= 5,customer == $c)在这个端点上我们需要理解的是Customer(…条件)过滤器和Order(…条件)过滤器需要是事实,换句话说,他们需要去显式的以insert方法a插入进KieSession中.尽管Order.getcustomer()不是事实,但是它是事实中的对象。
这个规则要想评估为true,我们需要一个Order和一个Customer对象来使得所有的条件为真。在Customer(…条件)过滤器和Order(…条件)之间,有一个隐式的AND,因此,这个LHS可以这样解读:这里有一个超过20条记录的订单,AND,一个消费者与这个订单相关联。
那么,现在我们再来看RHS,即modify(c)句子。modify()方法是由规则引擎提供的,来确保引擎知道了我们加入进规则引擎中的事实数据被修改了,并且这些修改需要通知其他的规则,因为这里的改变可能会触发其他的规则的匹配。既然这样,我们正在让引擎知道对消费者对象的类别的修改。如果您省略了modify(
c),则没有其他规则知道该更改 类别,这意味着依赖于已分类条目的规则将不会被匹配的。由于这个原因,当在隶属于classify-item-rules.drl文件的规则中设置类别时,您会注意到我们也在更新项目事实。
现在我们的规则变得更加复杂了,我们在项目代码中清楚地区分业务定义,而注意这些个事实也很重要。我们正在提取如何将客户分类为这些规则的定义,如果业务定义发生变化而不修改应用程序的其余部分,我们将能够更新这个定义。这是使用业务规则的核心概念之一。
现在,基于这种分类,我们可以为不同的客户创建不同类型的优惠券,允许我们以不同的方式对待每一个客户,依托于他们的忠诚值和以前的订单:
rule "Create Coupons for Silver Customers"
when
$o: Order( $customer: customer )
$c: Customer(this == $customer, category == Category.SILVER )
then
insert(new Coupon($c, $o, Coupon.CouponType.POINTS));
end
和前面的例子一样,这里的规则是由Order和Customer过滤; 然而,正如您在规则RHS中看到的,我们正在创建 Coupon优惠券的新对象并使用insert()方法将其插入进规则引擎让其变为事实。这这意味着,一旦该规则被规则引擎执行,它就会触发任何其他的期待着优惠券对象的规则。在这里,事情变得更有趣了。我们了解了规则如何能够生成新的数据并将不同的规则组合在一起当我们为规则引擎提供新数据时。
如果你觉得有必要做实验,我们鼓励你在 coupons-creation.drl 写文件里一个规则去匹配创建的优惠券,看看会发生什么
现在让我们把事情变得更复杂一些,假设我们想要检查一个包含两个或多个项目的订单,但是只包含HIGH_RANGE项目,我们想要对这些具体的订单申请一些折扣。
为了编写一个检查这种情况的规则,我们还需要对OrderLine对象(我们也需要添加这个导入)进行评估 。这可以翻译成在我们的规则中添加更多的过滤器。现在,我们需要对Order对象进行约束、OrderLines和相Item关联。下面的UML图显示了 这些对象之间的关系:
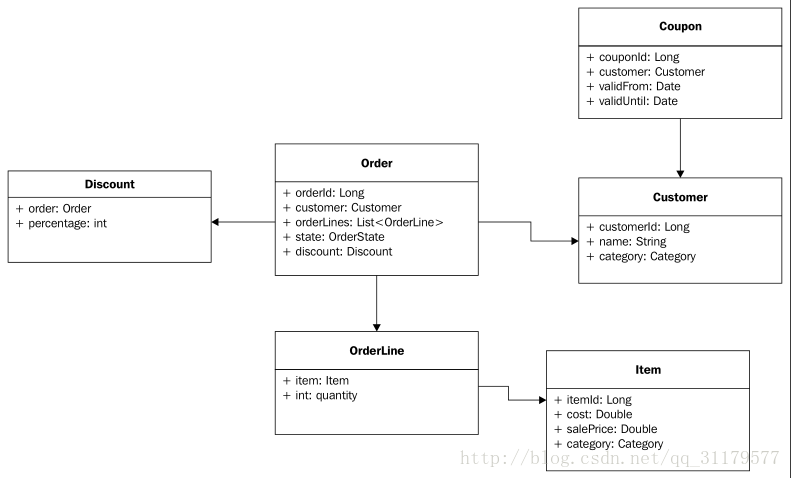
下面的规则文件表达了先前引入的折扣规则:
rule "Silver Customers + High Range Order - 10% Discount"
when
$o: Order( $lines : orderLines.size >= 2, $customer: customer, discount == null )
$c: Customer( category == Category.SILVER, this == $customer )
forall( OrderLine( this memberOf $lines, $item : item)
Item(this == $item, category == Item.Category.HIGH_RANGE)
)
then
$o.setDiscount(new Discount(10.0));
update($o);
end对于Order()、OrderLine()和Item(),我们有三种不同的对象筛选器。请注意 这条规则也取决于我们的物品分类;然而,这个规则和我们的第一个分类我们的物品的规则之间没有明确的关系。 这个规则引入的一个新事物是条件元素forall,它确保所有的OrderLines和相关的订单项都被分类为HIGH_RANGE物品。如果至少有一个项目与当前订单有不同的类别集 ,此规则将不会被激活和触发。在和前面一样,我们正在更新订单,以便有另一条查看折扣的规则被应用,信息可以提供给引擎。
我们将分析这些项目结构和执行这些规则所提供的测试
5.4 组织我们的项目
我们的规则越复杂,对他们进行测试就越重要,并让他们尽可能地组织起来。我们将讨论如何组织我们的示例项目,以使我们的规则、它们的测试和相关的类保持在一个易于维护的结构中。
我们推荐这样的方式来构建项目,这样每个项目都有一个定义良好的范围,依赖关系集,并且它们可以独立测试.您应该保留所有的应用程序基础设施代码(用户接口,系统集成,服务,等)在单独的Maven模块中,因此,基础设施层可以在倾向于更频繁地根据业务需要更新的业务知识的单独循环中进行维护.
示例存储库包含一个高级的父项目,该项目由每个章节模块组成。每一章都包含以下三个模块.
-kjar:这将包含我们的业务资产,如规则、业务流程, 等等
-tests:我们将在这里包括所有的测试
-extras (可选的):这个模块通常包含扩展的类 Drools和jBPM功能,比如规则的自定义评估器,业务流程的工作项处理程序,等等
-kjar和-tests模块被认为是知识项目,因为它们包含规则、定义和测试,以确保定义的知识行为正确。如下图所示,*-test工程将会从你的应用中依赖领域模型工程。它也可能依赖于服务层来执行操作;然而,作为一种良好的实践,这些服务可以被嘲笑。从项目的角度来看,最有可能的是,服务和用户接口模块最终会依赖于知识相关的项目(就是-kjar,里面是业务规则)。如果知识相关的项目只是定义了核心业务逻辑,您的应用程序里的服务层将最终使用它们,以便在内部作出决策。从用户界面的角度来看,我们还可以定义知识项目来帮助用户在UI级别上,如下图所示:

在这一点上,不要担心这个结构,它会变得更加清晰。现在,如果你看一下chapter-02-test/项目,您会发现我们需要定义一些额外的依赖项 我们将使用的测试框架如下:
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.hamcrest</groupId>
<artifactId>hamcrest-library</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<scope>test</scope>
</dependency>在将这些依赖项添加到我们的项目之后,我们即可创建第一个Junit测试单元来使得而我们的规则可以按照预期的执行。注意,我们已经在这一章中定义了不同规则文件中的几个规则,现在,我们将把它们全部加载到相同的KieSession下。这意味着当我们你插入信息进引擎中时,所有的规则都将会评估,并可能被触发
我们要研究的第一个测试是 ClassifyItemsTest.java,位置在 src/tests/java/org/drools/devguide/chapter-02文件夹下的 chapter-02/chapter-02-test 项目里
public class ClassifyItemsTest extends BaseTest {
@Test
public void lowRangeItemClassificationTest() {
KieSession kSession = createDefaultSession();
Item item = new Item("A", 123.0, 234.0);
kSession.insert(item);
int fired = kSession.fireAllRules();
assertThat(1, is(fired));
assertThat(Category.LOW_RANGE, is(item.getCategory()));
}
// @Test
// public void midRangeItemClassificationTest() {
// }
// @Test
// public void highRangeItemClassificationTest() {
// }
}这个测试展示了如何去确保我们的物品被分类正确。我们鼓励去研究下classify-item-rules.drl文件,查看其它的规则文件,并写测试用例来确保其他类别也被正确处理。
如果我们的项目使用CI持续集成系统,例如jeekins,一旦规则改变,我们就会收到通知,其中一个测试会中断。允许我们检查测试是否需要更改,或者规则中引入的更改是否破坏了已经在系统中定义的其他一些策略。
另外的一个单元测试是OrderDiscountTest.java,在相同文件夹下。
public class OrderDiscountTest extends BaseTest {
@Test
public void highRangeOrderDiscountTest() {
KieSession kSession = createDefaultSession();
Order o = ModelFactory.getOrderWithFiveHighRangeItems();
kSession.insert(o.getCustomer());
kSession.insert(o.getOrderLines().get(0));
kSession.insert(o.getOrderLines().get(1));
kSession.insert(o.getOrderLines().get(2));
kSession.insert(o.getOrderLines().get(3));
kSession.insert(o.getOrderLines().get(4));
kSession.insert(o.getOrderLines().get(0).getItem());
kSession.insert(o.getOrderLines().get(1).getItem());
kSession.insert(o.getOrderLines().get(2).getItem());
kSession.insert(o.getOrderLines().get(3).getItem());
kSession.insert(o.getOrderLines().get(4).getItem());
kSession.insert(o);
int fired = kSession.fireAllRules();
// We have 5 Items that are categorized -> 5 rules were fired
// We have 1 Customer that needs to be categorized -> 1 rule fired
// We have just one order with all HIGH RAnge items -> 1 rule fired
// One Coupon is created for the SILVER Customer -> 1 rule fired
assertThat(8, is(fired));
assertThat(o.getCustomer().getCategory(), is(Customer.Category.SILVER));
assertThat(o.getDiscount(), not(nullValue()));
assertThat(o.getDiscount().getPercentage(), is(10.0));
assertThat(o.getOrderLines().get(0).getItem().getCategory(), is(Item.Category.HIGH_RANGE));
assertThat(o.getOrderLines().get(1).getItem().getCategory(), is(Item.Category.HIGH_RANGE));
assertThat(o.getOrderLines().get(2).getItem().getCategory(), is(Item.Category.HIGH_RANGE));
assertThat(o.getOrderLines().get(3).getItem().getCategory(), is(Item.Category.HIGH_RANGE));
assertThat(o.getOrderLines().get(4).getItem().getCategory(), is(Item.Category.HIGH_RANGE));
// The Coupon Object was created by the Rule Engine so we need to get it from the KieSession
Collection<Coupon> coupons = getFactsFromKieSession(kSession, Coupon.class);
assertThat(1, is(coupons.size()));
}
}这些测试的一个常见需求是使用我们的域模型,这些领域对象可以包含复杂的结构和大量的数据。通常,我们最终会有一些助手从数据库之类的数据存储中检索这些信息,或者为了测试,我们可以创建本地实例。
对于这些测试,我们使用的是ModelFactory助手,它初始化了不同的订单,客户,以及我们的产品。
这个测试加载了我们迄今为止定义的所有规则(没有特定的顺序) DRL文件:
classify-customer-rules.drl
classify-item-rules.drl
coupons-creation.drl
order-discount-rules.drl
KieSession是由助手方法createDefaultSession()创建的,ModelFactory为我们提供了一个订单,让我们可以访问OrderLines,Customer 和 Items。为了使规则引擎能够工作并将这些对象与之前定义的规则相匹配,我们需要使用insert()方法插入每个对象。你们可能已经注意到了,如果我们需要分别插入所有对象,那么这很容易成为一个问题。 有几个替代方案可以解决这个问题,我们将后面会讲。我们需要知道我们是否有按类型过滤事实的规则。我们也需要将这些事实(就是数据)都加入进引擎中以供它使用。
现在,在将所有事实插入到KieSession之后,评评估由引擎完成,并创建匹配。重要的是要明白,并非所有的匹配都需要在fireAllRules()调用上执行,其中一些可能会被取消 ,或者还可以在执行过程中创建新的匹配。我们将在下一节详细分析规则执行流程。现在,我们需要了解 为什么我们要在测试中使用8条规则,为了做到这一点,我们需要做一些简单的数学运算。
我们知道一个规则将被每一个需要分类的项目触发。在这测试中,我们有5个物品条目对象Item,因此我们会有5条规则被触发。我们不知道这些规则会被触发的顺序,然而,我们知道,他们将在一个依赖于这种分类的规则之前被触发。同样的情况也发生在顾客身上,因此,还有一条规则被触发。同样,我们不知道也不关心条目和客户分类的顺序。最后,为优惠券创建而触发一个规则,再一个规则是向订单应用折扣。正如我们之前描述的那样,触发命中的顺并不重要,这个测试检查是否对象会像预计那样被改变。在测试结束后,我们无法检查Coupon优惠券对象,因为我们没有任何对于它的引用。这个Coupon优惠券对象被规则引擎创建,为了让我们得到它,我们可以使用 getFactsFromSession ( kSession , Coupon.class ) 工具方法,这个方法可以获取插入进KieSession中的Coupon对象事实。
如果你写了更多关于优惠券、客户、订单等的规则,测试可能会失败。如果你这样做了,一定要更新测试,这样他们就能通过。
**下一节,Drools运行时**
6.Drools Runtimes
6.1 理解Drools运行时实例
Drools允许我们以不用的方式创建规则引擎的实例,所以我们可以选择最适合于我们正待解决的问题的方式。每一个规则引擎都是一个密封的上下文,我们定义的规则将根据我们提供给这个特定实例的数据进行评估。规则引擎被看作是在服务器中运行它们的大而单一的进程,我们可以发送数据给它处理。另一方面,Drools允许我们本地为我们的应用程序生成轻量级实例。通常有多个实例处理不同的规则和数据,而不仅仅是一个大实例。
为了生成规则引擎的新实例,我们需要了解以下概念:
KieService
KieContainer
KieModule
KieBase
KieSession
通过使用这五个概念,我们将能够定义每个实例是如何配置的,以及每个实例对每个实例的可用性。在我们需要创建多个规则引擎的情况下,重要的是要了解究竟发生了什么,以避免不必要的瓶颈和性能问题。重要的是要理解这五个概念是在Drools的前一个版本中提供的扩展版本。注意这里的KIE前缀,这表明,现在我们不仅在处理规则引擎实例,而且还提供了更多的定义和执行业务知识的方法。
首先,我们将从KieServices 类开始,通过提供一个服务注册表,我们可以找到不同目的的帮助方法,从而使我们能够访问所有其他的概念。在以后版本你的Drools,我们可以包含更多的服务来满足不同的用例。而现在,我们需要知道如何获取KieServices实例,我们通过使用下面的静态kieservices.factory . get()方法来做到这一点:
KiseServices ks = KieServices.Factory.get()使用KieServices,我们可以访问与规则引擎实例一起使用的许多工厂、服务和实用方法。我们将会使用KieService来创建KieContainer实例,它定义了用于创建规则引擎的新实例的规则的范围。一个KieContainer可以承载一个KieModule和它的依赖,这意味着一个层次结构的KieModules可以被加载到KieContainer的一个实例中。
这些概念之间的关系如下图所示:
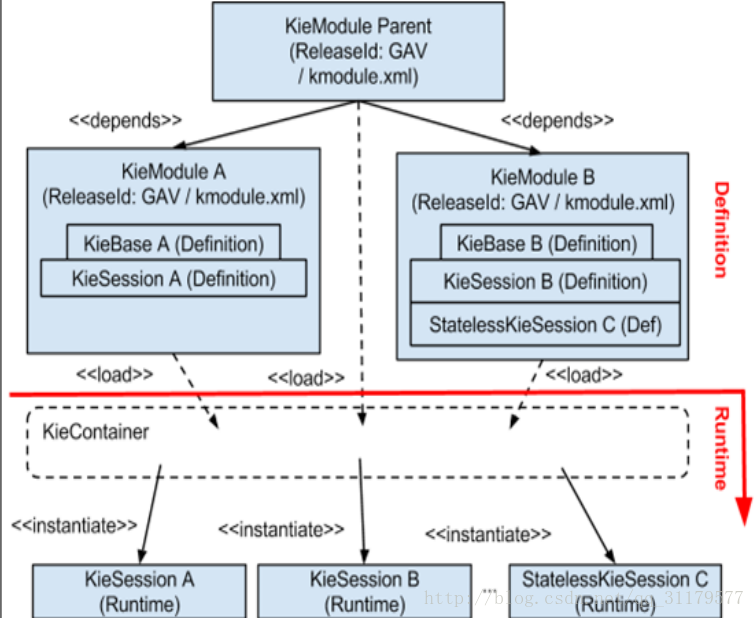
在Drools 6中,所有的东西都是围绕着KieModules创建的。每个KieModule包含 在某一区域或某一领域相关的业务资产(业务规则、业务流程、决策表等)。这些KieModules可以包括其他的KieModules, 允许我们组成一个顶级的KieModule,包含来自不同领域的若干资产。
KieModule是一个包含规则的标准java-maven项目,业务流程和其他资源在其资源中。一个特殊的叫做kmodule.xml的文件也必须包含在其中(存放在META-INF/dictory下),它定义了关于如何对这些特定资产进行分组和消费的内部配置。
正如我们在前面的图中看到的,KieContainer将会允许我们去实例化一个KieModule,以便创建规则引擎的一个或多个实例。这些实例可以被配置为具有相同的规则或完全不同的设置。前面的图还显示了如何决定装入哪个KieModule;例如,我们可以决定去加载KieModule A模块,因为我们要使用定义在其中的规则,或者我们可以直接加载其母类,即KieModule Parent,它依赖于KieMouduleA模块和KieModule B模块,因此这些模块中的每个配置都将被加载。
下面的部分将深入探讨KieModule和KieContainer的细节。在开始的时候,这听起来有点让人困惑,因为有太多的选择,这正是Drools为配置和实例化规则引擎所提供的灵活性的原因。
6.2 KieMoudule和KieContainer
一旦我们掌握了kieservice,我们就可以创建新的KieContainers。在内部, KieContainer对所有的业务资产(规则、流程、电子表格、PMML文档等)都有引用,当我们创建新的规则引擎实例时,这些资产将被加载。正如上一节所描述的,一个KieContainer根据我们的应用程序需要,可以生成具有不同配置的多个规则引擎实例,并承载不同的规则集.在Drools 6中,我们可以在两个选项之间进行选择,以定义将包含在KieContainer实例中的资源和配置的范围,如下所示:
基于类路径
使用Maven依赖解析技术(kie - ci)
第一个选项将查看应用程序类路径中的所有业务资产,并允许我们在规则引擎的不同实例中加载它们。第二个选项把预先定义的工件和它们的传递依赖项委托给Maven,以找出需要包含的所有资源。
让我们详细地看一下这两个选项。首先,我们先来看看如何做到类路径被扫描和规则被接收。了解该如何工作是为了了解本节所提供的项目。
本节提供了以下五个项目来演示我们的kiemodule的不同设置:
chapter-03-classpath-tests:这个项目提供了用于创建kiecontainer的类路径解析策略的测试。
chapter-03-maven-tests:这个项目提供了测试,展示了如何利用Maven的力量来解决作为Maven构件的kiemodule
chapter-03-kjar-simple-discounts: 这是一个包含一套简单折扣规则的kiemodule。
chapter-03-kjar-premium-discounts:这是另一个包含一套优惠折扣规则的kiemodule
chapter-03-kjar-parent:这是一个把持有对于上面的KieMoudule引用的模块。它不包含任何内部资产,但它提供了对简单和高级折扣的参考,以便它们可以被一起引用。
接下来的两部分将包括以下两种选择:
从classpth类路径下加载规则
使用Maven构件加载规则(使用kie - ci)
6.2.1 从classpth类路径下加载规则
参考 chapter-03-classpath-tests 项目
KieContainerClassPathTests类下的 loadingRulesFromClassPath()演示了如何可以通过扫描当前应用程序类路径来创建新的KieContainer。在这个例子中,我们在JUnit测试中引导Drools,而Maven则负责根据pom.xml中的定义为我们设置类路径。如果我们不适用maven来启动这个项目(或者这个测试类),那么Drools将会扫描项目的classpath类路径,不管它是如何定义的。在这个例子中,就像我们在Maven项目中,为项目定义的所有依赖项和测试范围定义的依赖项将在运行测试之前被添加到类路径中。
让我们来看已开pom.xml文件,我们将注意到,三个包含kmodulexml文件的依赖项目。,如下:
<dependency>
<groupId>org.drools.devguide</groupId>
<artifactId>chapter-03-kjar-simple-discounts</artifactId>
<version>1.0.0</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.drools.devguide</groupId>
<artifactId>chapter-03-kjar-premium-discounts</artifactId>
<version>1.0.0</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.drools.devguide</groupId>
<artifactId>chapter-03-kjar-parent</artifactId>
<version>1.0.0</version>
<scope>test</scope>
</dependency>当我们基于classpath类路径创建一个KieContainer时候,所有的可用的jar将会被扫描。要创建一个新的KieContainer,我们使用KieSevice(ks)来为我们提供一份KieContainer实例,如下:
KieContainer kContainer = ks.newKieClasspathContainer();Drools将会扫描所有类路径下的jar,来在META-INF文件夹下寻找kmoufle.xml文件。当找到时,这个文件将加载所提供的配置,使它们可以在我们的应用程序中使用。对于这个特定的例子,会有4个kmoudle.xml文件被发现,其中3个是在pom文件中以依赖项定义的,另一个就是本项目自身的kmoudle.xml文件。每一个kmoudle.xml文件中的配置都会加载并提供给KieContainer,等待被使用。当然,注意在有一个叫classpath-discount-rules.drl的DRL文件,在chapter-03-kjar-simple-discounts项目下的\src\main\resources\rules\simple\里。
现在,我们的KieContainer已经加载了所有这些配置,我们可以开始马上使用。回到我们的loadingRulesFromClassPath()测试,该测试显示规则如何从类路径加载,如下:
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.newKieClasspathContainer();
Results results = kContainer.verify();
results.getMessages().stream().forEach((message) -> {
System.out.println(">> Message ( "+message.getLevel()+" ): "+message.getText());
});
assertThat(false, is(results.hasMessages(Message.Level.ERROR)));
kContainer.getKieBaseNames().stream().map((kieBase) -> {
System.out.println(">> Loading KieBase: "+ kieBase );
return kieBase;
}).forEach((kieBase) -> {
kContainer.getKieSessionNamesInKieBase(kieBase).stream().forEach((kieSession) -> {
System.out.println("\t >> Containing KieSession: "+ kieSession );
});
});- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
如我们所见,verify()方法将允许我们确保我们的业务资产是正确的,并在KieContainer实例中正确加载。如果 verify()方法返回包含错误的结果,我们应该在这些错误再向前移动之前停止和纠正。注意,results.getmessages()方法返回的Message对象还包含问题所在的文件中的行和列。如果一切正常,我们可以继续检查是否所有我们期望使用的KieBases和kiesUNK是被加载的。对于这个测试,我们只是打印了一下,然而,这里建议使用断言。
如前所述,kmodule.xml文件包含了将提供给该KieContainer的内容,因此,让我们来看看kmodule.xml文件内容,来更深的理解在创建一个KieContainer类路径时候都加载了什么。
这个简单的测试演示了如何基于类路径扫描将所有的kiemodule加载到容器中 .确保您运行这个测试来验证结果,并理解为什么要加载不同的配置。
6.2.2 使用MAVEN加载规则(Kie-CI)
上面的小节里讲了,在类路径中找到的所有KieModules,应用程序会将其加载到KieContainer中。有些情况下我们不希望这种情况发生。可能是因为我们在本地没有项目的这些jars,或者我们想要从业务规则的依赖上分离我们的应用程序依赖关系。
如果我们打开 chapter-03-maven-tests项目,查看他的pom文件,我们会发现有巨大的不同。这个文件里没有一个KieMoudle依赖。然而,一个新的依赖被加入到了kie-ci 模块内。如下:
<dependency>
<groupId>org.kie</groupId>
<artifactId>kie-ci</artifactId>
<type>jar</type>
<scope>test</scope>
</dependency>这个新加入的依赖项,可以允许Drools使用Maven的机制去解决在应用程序类路径之外的artifacts。让我们看一看 KieContainerMavenTests测试类。我们看到我们可以使用KieService以一种不同的方式来创建一个新的容器,就像下面的这样:
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.newKieContainer(ks.newReleaseId("org.drools.devguide",
"chapter-03-kjar-simple-discounts",
"1.0.0"));现在请注意,我们没有使用maven的poms文件来依赖于其他的项目或者应用,而是代替以KieContainer根据我们所提供的GroupId, ArtifactId,和Version (也叫做GAV)来处理一个artifact。正如你看到的,newKieContainer()方法期待一个ReleaseId对象作为参数,这个对象是用KieServices的助手方法来完成创建的。
Drools的API不仅允许我们使用ReleaseId来指定KieMoudle的版本,而且如果需要的话,还可以升级到新版本,即通过updateToVersion()方法。这个方法会重新创建KieContainer,来使得它变为一个接入点,将KieBase和新版本的KieModule的KieSession连接起来的。
使用这种机制,容器将会从这个artifact以及这个artifact的依赖的配置项。如果你执行这个测试,你将会看到每一个单独的测试只是加载在KieContainer创建时请求的那个artifact里的kmoudle.xml文件。
现在是时间来看一下kmoufle.xml文件了,它允许我们配置我们的KieBase和KieSession,来准确定义了如何创建规则引擎实例以供我们在应用程序中使用
6.3 KieMoudle配置(KieBases,KieSession&StatelessSession)
kmoubdle.xml被用于自定义KieMoudle配置。在这个文件里,我们可以定义规则如何在不同的KieBase里组织在一起,KieBase可以以不同的目的被加载。它还允许我们去为将会创建的规则引擎实例定义更多的细粒度的配置。
在这一以小节里,我们将会覆盖KieBase,KieSeession和StateKieSeeion的基础配置。在最后,我们也会回顾一种机制,我们可以使用这种机制,来让其他Kiemoudle里的KieBase加入进我们的KieMoudle中。
首先看chapter-03-classpath-tests/src/test/resources/META-INF/下的kmoudle.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<kmodule xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://jboss.org/kie/6.0.0/kmodule">
<kbase name="rules.cp.discount">
<ksession name="rules.cp.discount.session" type="stateful"/>
</kbase>
</kmodule>使用这个KieBase和KieSession的概念,我们可以定义如何加载规则的粒度。KieBase表示一组资产(即规则等)的编译版本。而一个KieSession则是一个包含KieBase里的规则的规则引擎的实例。为此,对于一个相同的KieBase,我们可以有多个不同会话实例,而且这是有意义的。我们可以使用相同的规则,但是有一个以不同的方式为不同的需求配置的会话。
在本例子中,我们定义了KieBase叫做rules.cp.discount.注意,KieBase的name属性与我们在src/test/resources/下所使用的文件结构相同,其实也是我们规则的所存储的地方。 在KieBase中,我们定义了一个叫做rules.cp.discount.session 的KieSession。这个KieSession代表了包含所有在KieBase中定义的规则的规则引擎实例。在Drools6中,类似于以前的Drools版本,KieSession有两种状态类型(以前叫做KnowledgeSession):Stateful和Stateless
stateful状态的KieSession允许我们在与规则引擎的几次交互时保持这种状态。在Drools6, Stateful Knowledge Sessions改名为KieSession,因为有最常见的会话类型,名字就保持的较短一点。相比之下,StatelessKieSession只允许我们交互一次,取得结果,没有为下一个交互保存状态。我们将会在之后章节将KieSession。
例如,如果你看一下测试,KieContainerClasspathTests类下的loadingRulesFromDependencyParentKieModule()方法,你可能注意到我们使用一个(StateFul)的KieSession插入了一些列的事实数据,然后我们调用fireAllRules()方法来,然后我们不断插入更多的事实数据,并再次调用fireAllRules()。在两次调用 fireAllRules()之间,状态(即事实数据和规则的评估)被保持了下来。在某些情况下,第二组事实与第一组事实一起触发新的规则,如下:
KieSession kieSession = kContainer.newKieSession("rules.discount.all");
Customer customer = new Customer();
customer.setCustomerId(1L);
customer.setCategory(Customer.Category.SILVER);
Order order = new Order();
order.setCustomer(customer);
kieSession.insert(customer);
kieSession.insert(order);
int fired = kieSession.fireAllRules();
assertThat(1, is(fired));
assertThat(10.0, is(order.getDiscount().getPercentage()));
Customer customerGold = new Customer();
customerGold.setCustomerId(2L);
customerGold.setCategory(Customer.Category.GOLD);
Order orderGold = new Order();
orderGold.setCustomer(customerGold);
kieSession.insert(customerGold);
kieSession.insert(orderGold);
fired = kieSession.fireAllRules();
assertThat(1, is(fired));
assertThat(20.0, is(orderGold.getDiscount().getPercentage()));正如你看到的,分类为SILVER的订单和消费者customer,在我们插入了分类GOLD的消费者和订单后,仍然在KieSession中,即说明状态被保持了下来。下一节我们会学如何小更复杂的规则,例如,评估两个订单及其关系。在这样的情况下,不止一条规则可以被触发。
现在我们来看看 statelessSessionTest()这个测试,这是一个StateLess的KieSeesion的例子,我们可以与之前的Stateful的KieSesion的进行对比。当然首先我们需要在kmoudle.xml文件里定义stateless的KieSession。
<ksession name="rules.cp.discount.session" type="stateful"/>现在我们通过我们的KieContainer;来获取一个statelessSession实例。如下:
StatelessKieSession statelessKieSession = kContainer.newStatelessKieSession("rules.simple.sl.discount");
Customer customer = new Customer();
customer.setCategory(Customer.Category.SILVER);
Order order = new Order();
order.setCustomer(customer);
Command newInsertOrder = ks.getCommands().newInsert(order, "orderOut");
Command newInsertCustomer = ks.getCommands().newInsert(customer);
Command newFireAllRules = ks.getCommands().newFireAllRules("outFired");
List<Command> cmds = new ArrayList<Command>();
cmds.add(newInsertOrder);
cmds.add(newInsertCustomer);
cmds.add(newFireAllRules);
ExecutionResults execResults = statelessKieSession.execute(ks.getCommands().newBatchExecution(cmds));
order = (Order)execResults.getValue("orderOut");
int fired = (Integer)execResults.getValue("outFired");
assertThat(1, is(fired));
assertThat(10.0, is(order.getDiscount().getPercentage()));- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
注意现在我们需要使用newStatelessKieSession()方法来创建新的StateLessKieSession.这个类型的会话,我们不需要有insert方法和fireAllRules()方法,代替的是使用execute()方法,来让我们发送一个命令或者一串命令去执行。从这个执行,你可以获取到一个 ExecutionResults对象,它会包含所有的我们想要在规则执行后收集的结果集。然而在交互之后(执行并取得了执行结果),statelessKieSession就不会保存任何状态,如果你又执行execut(),那么所有的规则只会根据我们发送给这个交互的事实数据来重新评估。
最终,你如果想聚合KieMoudle,我们可以使用在KieBase配置文件中的包含选项。你可以看一下位于 chapter-03-kjar-parent/src/main/resources/kmodule.xml。如下:
<?xml version="1.0" encoding="UTF-8"?>
<kmodule xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://jboss.org/kie/6.0.0/kmodule">
<kbase name="discount" default="true" includes="rules.premium, rules.simple">
<ksession name="rules.discount.all" type="stateful"/>
</kbase>
</kmodule>- 1
- 2
- 3
- 4
- 5
- 6
- 7
如所见,kbase标签的includes属性,做了一个到在其他模块内定义的KieBase的引用。如果这个KieBase在初始化的时候可用,那么他们将会被添加进来,那么现在这个叫做 rules.discount.all 的KieSession将会包含在这两个KieBase中定义的规则。
为了完整起见,这里是kmodule.xml文件的完整模式:
地址是:https://github.com/droolsjbpm/droolsjbpm-knowledge/blob/master/kie-
api/src/main/resources/org/kie/api/kmodule.xsd- 1
- 2
我们将使用提供的大部分选项来配置我们的KieBase地和KieSession。现在,我们来看看由Drools提供的最需要的特性之一,动态加载我们在业务资产中所做的更改。本节的下半部分将介绍KieScanner和如何使用它我们的应用程序。
6.4 KieScanner
如果有一个关于应用的普遍真理,那就是:随着时间的推移,业务规则会发生变化。
Drools提供了解决办法。Drools 介绍的在应用程序和业务逻辑之间分离,允许我们将业务逻辑中的更改解耦–这通常是频繁的–从应用程序的基础结构或UI中发生的变化,而且这并不常见。
我们已经看到了当一个新版的KieMoudle发布的时候,如何手动更新KieContainer。这种方法的局限性之一是我们需要去手工通知每个依赖于修改的KieModule的应用程序,如果有一种方法可以自动地让应用程序在它们依赖的一个kiemodule模块被更新时通知应用程序呢?幸运的是,Drools为我们提供了这个机制,它的名字叫KieScanner。
PS:重点内容
为了在我们的应用中使用KieScanner,那么 org.kie::kie-ci这个artifact就必须引入
Drools中的KieScanner组件只是一个围绕KieContainer的包装器,它可以被配置为自动检测容器所依赖的资源的变化。但是有一个陷阱,KieContainer所引用的资源必须被驻留在Maven存储库中的KieJars监控。默认情况下,kie-ci将会使用.m2中的setting.xml文件制定的用户仓库。这种行为可以被重写,使用 -Dkie.maven.settings.custom系统属性即可.例如:
KieServices ks = KieServices.Factory.get();
KieContainer kieContainer = ks.newKieContainer(
ks.newReleaseId("group.test","artifact-test", "1.0"));
KieScanner scanner = ks.newKieScanner(kieContainer);如所见,一个KieScanner可以被实例化—就像Drools6的系统组件一样–使用KieService。在KieScanner初始化之后,我们有两个选项,我们可以将其配置为在每一毫秒的时间内对底层的KieJars的新版本进行轮询,或者我们可以手工强制它检查新版本的需求,如下:
//Manually run a check for new versions
scanner.scanNow();
//Configure the scanner to check for new versions every 10 seconds
scanner.start(10_000);如果使用start()方法启动KieScanner,stop()方法可以用来停止这种机制。
当新的KieJar版本被KieScanner检测到了,增量构建资源被触发。从这一刻起,所有的通过KieConainer创建的KieBase和KieSession,将会使用新版本的资源。那些预先存在的KieBase和KieSession,也将会被更新至由KieScanner发现的最新的版本。
首先,可以很容易地认为,一个KieContainer的增量构建可以用于添加、修改或删除规则,但是,真相是当KieContainer重新构建时候,更复杂的资源修改,如新类型的声明、对现有类型声明的修改、全局变量和/或函数的添加,以及您所能想到的几乎所有内容都允许发生。
6.5 Artifacts version resolution
KieScanner检查新版本的被监控的KieJars方式是根据Maven的工件版本规则:最新版本总是一个版本 使用最大版本号,除非版本是快照。如果两个工件有相同的GroupId,ArtifactId和version,比较每个工件的时间戳,以确定哪一个是最新的。KieScanner只检查KieJar中的版本,这些版本与在KieContainer中定义的版本是兼容的。换句话说,如果KieContainer使用的是特定KieJar的1.0版本,那么相应的KieScanner将检查与1.0兼容的kiejar的新版本。
下面的表显示了在不同的KieContainer版本和Maven存储库中新部署的KieJar版本的版本中兼容版本的含义
KieContainer version:1.0
| 新的KieJar版本 | KieScanner触发吗? | 原因 |
|---|---|---|
| 0.9 | no | 0.9版本(低版本)是与1.0版本不同的 |
| 1.0-SNAPSHOT | no | 版本不同 |
| 1.0 | yes | 版本相同。但是新的的时间戳会比较大,还是会检测出来 |
| 1.1 | no | 1.1版本(高版本)与1.O版本不同 |
正如我们在前面的表中看到的,KieScanner只有在一个新的被监控的KieJar的版本被检测到时候才触发 (根据它的时间戳)。就KieScanner而言,快照版本是 以同样的方式对待。下表显示了该行为对于快照KieJar版本。
KieContainer version:1.0-SNAPSHOT
| 新的KieJar版本 | KieScanner触发吗? | 原因 |
|---|---|---|
| 0.9 | no | 0.9版本(低版本)是与1.0-SNAPSHOT版本不同的 |
| 1.0-SNAPSHOT | yes | 版本相同。但是新的的时间戳会比较大,还是会检测出来 |
| 1.0 | yes | 版本不同 |
| 1.1 | no | 版本不同 |
一个KieScanner可以被定义使用一个固定的KieJar版本(上面的就是),但是还是可以配置为Maven的LATEST或者RELEASE版本,甚至是一个区间。这些特殊的版本定义在我们想让我们的KieContainers与最新版本或者一个KieJar的范围更新时是很有用的,不管它的具体版本号是什么:
KieContainer version:LATEST/RELEASE(原始KieJar版本是0.9)
| 新的KieJar版本 | KieScanner触发吗? | 原因 |
|---|---|---|
| 0.9 | yes | 版本相同,新的的时间戳会比较大,还是会检测出来 |
| 1.0-SNAPSHOT | no | KieScanner将LATEST版本视为RELEASE,当使用maven魔法名字时候不会使用快照,如果你想让快照被识别,那么就使用range区域来设置 |
| 1.0 | no | 版本不同 |
| 1.1 | no | 版本不同 |
就像LATEST和RELEASE一样,MAVEN魔法的版本名称也得到了KieScanner的range的支持。一个版本范围允许我们去指定一个可用的KieJar版本区间。范围支持开放和封闭的范围。
KieContainer version:(0.9)(原始KieJar版本是0.9)
| 新的KieJar版本 | KieScanner触发吗? | 原因 |
|---|---|---|
| 0.9 | yes | 版本相同,新的的时间戳会比较大,还是会检测出来 |
| 1.0-SNAPSHOT | yes | 版本不同 |
| 1.0 | no | 版本不同 |
| 1.1 | no | 版本不同 |
在前面的例子,一个开放式的版本([0.9,])在KieContainer中被指定。这个范围基本上说的是,KieContainer允许任何版本,只要超过0.9的即可,包括快照版本。
6.6 处理意外的问题和错误
到目前为止,我们已经介绍了在使用KieContainer时如何和何时更新 与KieScanner联合;然而,有一个很重要的问题 仍然打开:如果在将KieContainer升级到新版本时发生错误,会发生什么情况吗?
首先,我们需要理解的是,在升级过程中可能出现一个错误的KieJar的版本。一般来说,我们在讨论编译 新版本的KieJar的错误如下:
Syntax errors
Adding rules with duplicated names
Removing globals that are still being used, and so on
KieScanner将KieJar的整个过程视为一种原子行为。当由于任何原因,KieContainer的升级失败,那么整个过程被重新回滚,并且KieContainer保持原本的样子。在升级过程中生成的任何错误都会被悄悄地丢弃。
6.7 将他们组织在一起
在对KieScanner进行了很长时间的介绍之后,是时候把所有这些都放在一起进行单元测试了。
在 chapter-03/chapter-03-tests这个项目下,有一个 KieScannerTest.java测试类。他其中有一个 kieContainerUpdateKieJarTest单元测试,这个测试表明了如何使用KieScanner来更新KieContainer正在使用的KieJar。该测试还显示了在基本的KieContainer更新之后,之前创建的kiesession会自动更新到KieContainer所使用的KieJar的最新版本。
测试用例先创建了另个分类为SLIVER的消费者(CustomerA和CustomerB)和他们的订单(OrderA和OrderB)。这个单元测试的想法是创建带有单个规则的KieJar,规则是对于分类是SLVER的订单进行折扣。第一个版本的KieJAR的订单折扣是10%,第二个版本–该测试将通过编程方式创建和部署KieJar的新版本–将会给这些订单以25%的折扣
KieServices ks = KieServices.Factory.get();
ReleaseId releaseId = ks.newReleaseId(groupId, artifactId, version);
//The KieJar will contains a single rule that will give a 10% discount
//to Orders from SILVER Customers.
InternalKieModule originalKJar = createKieJar(ks, releaseId, createDiscountRuleForSilverCustomers(10.0));- 1
- 2
- 3
- 4
- 5
- 6
前面的行(这是测试用例的节选)以编程方式创建一个KieJar带有10%折扣
//Before we can create a kieContainer for the KieJar we just created,
//we need to deploy the KieJar into maven's repository.
repository.deployArtifact(releaseId, originalKJar, createKPom(fileManager, releaseId));
//Once the KieJar is deployed in maven, we can create a KieContainer for it,
KieContainer kieContainer = ks.newKieContainer(releaseId);
//The KieContainer is wrapped by a KieScanner.
//Note that we are neve starting the KieScanner because we want to control
//when the upgrade process kicks in.
KieScanner scanner = ks.newKieScanner(kieContainer);一旦KieJar被创建,它就被部署到本地Maven存储中,然后创建KieContainer。代码摘录也显示了 KieContainer用KieScanner包装。在现实生活中,我们应该使用它的start方法开始一个KieScanner;然而,考虑到我们需要我们的单位测试是确定的,我们不希望KieScanner异步方式检查更新 与此相反,测试将使用KieScanner的scanNow方法 在需要时,如下所示:
//Create a KieSession from the KieContainer
KieSession ksession = kieContainer.newKieSession();
//Calculate the dicount for OrderA using the provided KieSession.
//This method will assert that the calculated discount is 10%.
this.calculateAndAssertDiscount(customerA, orderA, ksession, 10.0);从生成KieContainer,我们将创造一个新的KieSession;calculateAndAssertDiscount助手方法被用于插入 customerA和OrderA进KieSession,并断言生成的折扣是10.0,如下所示
//A new KieJar for the same GAV is created and deployed into maven.
//This new version of the KieJar will give a 25% discount to SILVER
//Customers' Orders.
InternalKieModule newKJar = createKieJar(ks, releaseId, createDiscountRuleForSilverCustomers(25.0));
repository.deployArtifact(releaseId, newKJar, createKPom(fileManager, releaseId));- 1
- 2
- 3
- 4
- 5
- 6
下一步是创建一个不同版本的KieJar(相同group ID, artifact ID和version),这一次有一个将给予25%折扣的规则给银牌消费者。和以前一样,这个KieJar部署在Maven的存储库中, 覆盖原来的版本。
值得注意的是,KieContainer不会注意到这种变化。是 KieContainer是用KieJar的前一个版本建造的,不会 更新内容直到明确告知它这么做(使用KieScanner或通过 KieContainer。updateToVersion方法)。
//Programmatically tells the scanner to look for modifications in the
//KieJar referenced by the KieContainer it is wrapping.
//At this point, the KieSession we had previously created will be updated.
scanner.scanNow();
//Using THE SAME KieSession we used before, we now calculate the discount
//for OrderB. This method is asserting that the calculated discount is
//now 25% instead of 10%. This proves that the KieBase was modified
//according to the latest version of org.drools.devguide:chapter-03-scanner-1:0.9
this.calculateAndAssertDiscount(customerB, orderB, ksession, 25.0);在之前的代码里,我们可以看到测试用例测试是如何明确告诉KieScanner去扫描监控的KieContainer,并检查Kiejar的更新。注意:与 KieScanner.start对比 , KieScanner.scanNow是同步的。在它返回的时候,KieContainer将会被更新成最新的KieJar版本。
当KieContainer得到跟新到KieJar的最新版本,任何之前穿件的KieBase-KieSession–都会被更新。测试通过在以前用于customerA和orderA的同一会话中插入customerB和orderB来演示这种行为,这次的结果将会有所不同。现在的KieSession将包含25%的折扣而不是10%的折扣了。
重新整理的,希望字体样式可以更适合大家阅读,有问题可以在下面提意见,我会改进~~