201809201216——————————————————————创建
一、 背景:
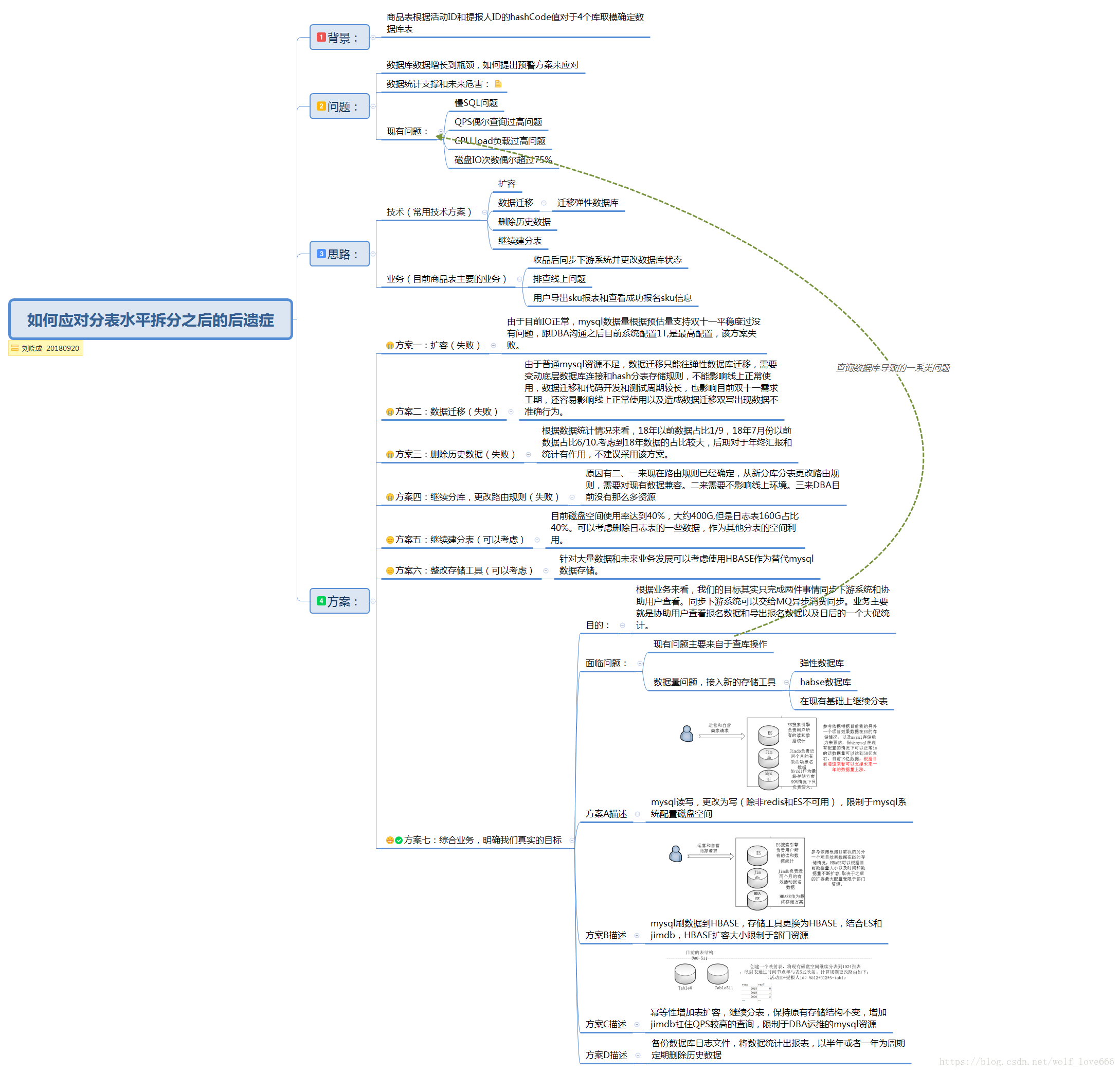
联合营销活动中心负责收品,伴随业务线上化的推广,使用率覆盖面的增高,原有数据库商品表不满足业务支撑。
特于2017年双十一前进行了垂直切分商品表分别到4个数据库,通过活动ID和提报人ID取模存放512张表中,迎接报名sku数量加剧情况。
二、 目前现状与问题:
【目前的数据量与未来发展问题】
目前4个数据库数据量统计如下(时间截止20180919):
总数据量(包含有效和无效sku) 大约19.6亿条数据,
失效大约SKU 1.37亿条数据
平均每张表 20亿/512张表=3906250条/表,Max表数据量达到519w条/表
每张表目前由于索引和字段一致,数据内容一致,采取最高数据量表计算其大小为:1131M,每条数据大约3k.
Mysql并没有定义一个大表的定义,根据Google团队的一些帖子,我查到达到2个亿数据量占用9G的时候查询是非常煎熬耗时的事情。
通过和DBA沟通,根据DBA建议单表范围保证性能高应该每张表大小控制在2G以内,以及数据量控制在千万级以下,防止产生亿级大表问题(表结构也会有影响,我们这里的表结构比较简单可以忽略)。
亿级大表主要危害有如下:
- 维护的不便利,查询的性能低
- 计算 sum、count过于集中
- 由于我们使用的索引目前是(InnoDB)索引及表数据都是放在 innodb_buffer_pool里面, 数据区间太大,读写热点不交集,造成命中率下降。
表数据那么多,总是冷不丁去查询时老数据,那么这种不频繁的page就会被挤出innodb_buffer_pool之外,使得之后的SQL查询会产生磁盘IO,从而导致响应速度变慢 。
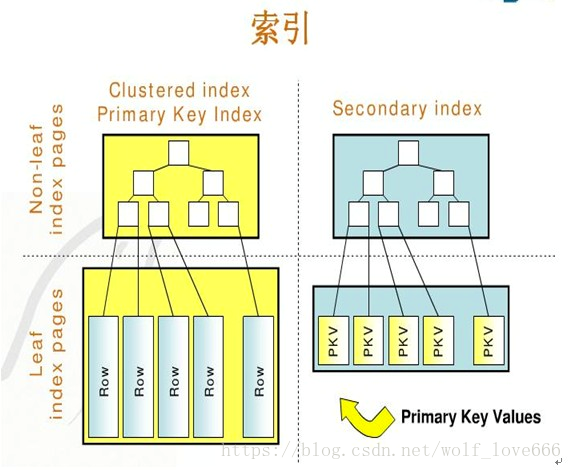
另外根据索引(B+tree)查询的问题,索引涉及到聚焦索引也就是我们常用的主键索引,左面聚集索引,右面非聚集索引,聚集索引通过B+tree的查询直接拿到row数据,而非聚集索引只能拿到他的主键标记,然后通过主键才能查询到数据(图片来自百度的谷歌图片)
【查询慢SQL问题以及使用情况】:
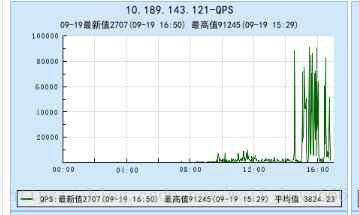
【QPS查询过高问题】
【CPU超过10%问题】
【磁盘IO次数】
三、 排查与分析
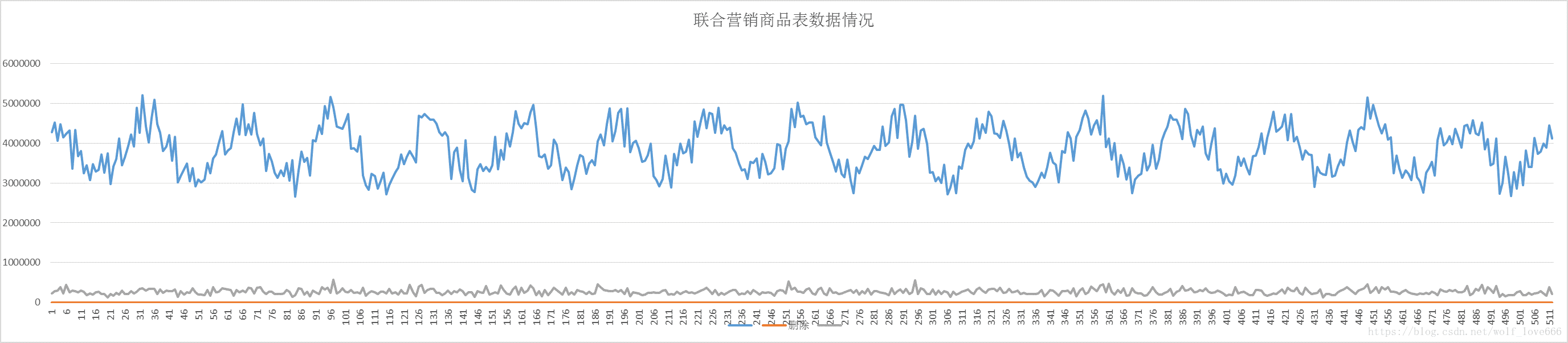
1)数据量问题:目前来看按照去年双十一和今年6.18数据量的增速,今年双十一数据量应对没有问题。
2)慢SQL举例:
可以从图中看出是由于单次查询占用行数接近27w数据,虽然SQL简单外加索引机制在数据量问题上依然是个鸡肋。
3)QPS偶尔查询过高的问题
可以定位到接口排查到调用数据库之前,根据冷热数据进行redis缓存处理。
4)CPU超过10%的问题:
根据前面的排查,应该是慢SQL的索引过滤性不强导致的全表扫描外加order by排序,具体还需要长时间观察与DBA沟通
5)磁盘IO次数目前还正常基本在75%以下。
四、 6.18和去年双十一数据统计综合统计分布图
五、方案参考首页banner图
201809211826更新——————————————————————————————