元组的创建
列表:打了激素的数组
元组:带了紧箍咒的列表
不可变数据类型,没有增删改查
可以存储任意数据类型
“”"
定义元组
t = (1,1.2,True,'westos')
print(t,type(t))
如果元组里面包含可变数据类型,可以间接修改元组内容
t1 = ([1,2,3],4)
t1[0].append(4)
print(t1)
t2 = ()
print(t2)
t3 = tuple([])
print(t3)
l4 = list(())
print(l4)
元组如果只有一个元素,后面一定要加逗号,否则数据类型不确定
t4 = (1,)
print(t4,type(t4))
元组的特性
tuple=(1,1.3,True,'curry')
索引
print(tuple[0])
print(tuple[-1])
切片
print(tuple[1:])
print(tuple[::-1])
print(tuple[:-1])
连接
除了数值类型之外,不同的数据类型之间不能连接
print(tuple+(1,2,3))
重复
print(tuple*5)
for循环
for i in tuple:
print(i)
成员操作符
print(1 in tuple)
print(1 not in tuple)
元组的常用方法
t = (1,2,'a','c','a')
查看元素的索引值
print(t.index('c'))
查看元素在元组中出现的次数
print(t.count('a'))
元组的应用场景
元组的赋值:有多少元素,就有多少变量接收
t =('westos',10,100)
name,age,score=t
print(name,age,score)
scores = (100,89,45,78,45)
先对元组进行转换
scoresli = list(scores)
scoresli.sort()
print(scoresli)
score_list = sorted(scores)
print(score_list)
比赛计分器
scores = (100, 98, 65, 78, 89)
scores = sorted(scores)
#python2中*middle不能使用
min_score, *middle, max_score = scores
#默认依次为最小值,中间值,最大值,middle是一个列表
print(max_score,middle,min_score)
print('最终成绩为%s' % (sum(middle) / 4))
深拷贝和浅拷贝
不可变数据类型 深拷贝和浅拷贝都不会改变地址
可改变数据类型
浅拷贝只是拷贝了外壳,内在的地址依然是不变的,只是一个指向
深拷贝将所以的东西都拷贝的新的地址,地址是变的
In [1]: import copy
In [2]: a=[1,2]
In [3]: b=[3,4]
In [4]: c=(a,b)
In [5]: d=copy.copy(c)
In [6]: e=copy.deepcopy(c)
In [7]: d
Out[7]: ([1, 2], [3, 4])
In [8]: e
Out[8]: ([1, 2], [3, 4])
In [9]: id(c)
Out[9]: 140589617825032
In [10]: id(d)
Out[10]: 140589617825032
In [11]: id(e)
Out[11]: 140589618049160
In [12]: id(d[0])
Out[12]: 140589618109512
In [13]: id(e[0])
Out[13]: 140589618009672
In [14]: id(c[0])
Out[14]: 140589618109512
In [15]: a=(1,2)
In [16]: b=(3,4)
In [17]: c=(a,b)
In [18]: d=copy.copy(c)
In [19]: e=copy.deepcopy(c)
In [20]: id(c)
Out[20]: 140589617058632
In [21]: id(d)
Out[21]: 140589617058632
In [22]: id(e)
Out[22]: 140589617058632
In [23]: id(d[0])
Out[23]: 140589617029960
In [24]: id(e[0])
Out[24]: 140589617029960
In [25]: id(c[0])
Out[25]: 140589617029960
集合的定义
集和里面的元素是不可重复的
s = {1,2,3,4,5,6,6,3,3,2}
print(s,type(s))
s1 = {1}
print(s1,type(s1))
如何定义一个空集和
s2 = {} #默认情况是dict,称为字典
print(s2,type(s2))
定义一个空集和
s3 = set([])
print(s3,type(s3))
集和应用1:列表去重
li = [1,2,3,4,1,2,3]
print(list(set(li)))
集合的特性
集和支持的特性只有 成员操作符(索引 切片 重复 连接 均不支持)
s = {1,2,3}
print(1 in {1,2,3})
print(1 not in s)
for循环
for i in s:
print(i,end=' ')
print()
print('~~~~~~')
for + index
for i,v in enumerate(s):
print('index: %s,value:%s' %(i,v))
集合的常用方法
添加顺序,和在集合中存储的顺序不同
s={6,7,3,1,2,3}
增加
s.add(9)
print(s)
增加多个元素
s.update({10,11,23})
print(s)
删除
s.pop() #会弹出第一个元素
print(s)
删除指定元素(元素要存在)
s.remove(23)
print(s)
s1 = {1, 2, 3}
s2 = {2, 3, 4}
并集
print('并集:', s1.union(s2))
print('并集:', s1 | s2)
交集
print('交集:', s1.intersection(s2))
print('交集:', s1 & s2)
差集
可以理解为s1中有哪些s2中没有的元素
print('差集:', s1.difference(s2))
print('差集:', s1 - s2)
对等差分:并集-交集
print('对等差分:', s1.symmetric_difference(s2))
print('对等差分:', s1 ^ s2)
s3={1,2}
s4={1,2,3}
s3是否为s4的子集
print(s3.issubset(s4))
s3是否为s4的超集
print(s3.issuperset(s4))
两个集合是不是不相交
print(s3.isdisjoint(s4))
去重排序练习题
华为机测题:
明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性
他先用计算机生成了N个1~1000之间的随机整数(N<=1000),N是用户输入的,对于
其中重复的数字,只保留一个,把其余相同的数字去掉,不同的数对应着不同的学生的学号,然后再把这些
数从小到大排序,按照排好的顺序去找同学做调查,请你协助明明完成“去重”与排序工作
import random
s=set()
num = int(input('请输入1到1000之间的一个整数:'))
for i in range(num):
number=random.randint(1,1000)
s.add(number)
print(sorted(s))
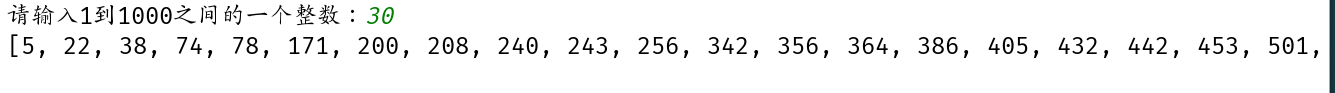
字典的创建
d={}
print(type(d))
字典:key-value键值对存储的一种数据结构
value值可以是任意数据类型:int float long list tuple set
d={
'curry':[30,'男','投篮'],
'james':[33,'男','上篮']
}
print(d)
print(d['curry'])
字典的嵌套
nbastar={
'30':{
'name':'stephen curry',
'age':30,
'team':'warriors'
},
'23':{
'name':'lebron james',
'age':33,
'team':'lakers'
}
}
print(nbastar['30']['team'])
工厂函数
d5=dict(a=1,b=5)
print(d5)
字典的创建
d = {
'1': 'a',
'2': 'b',
'3': 'c'
}
print(d['1'])
字典不支持索引和切片
字典的重复和连接是无意义的,字典的key是唯一的
成员操作符判断的是某个值是否为字典的key
print('1' in d)
print('1' not in d)
字典的for循环默认遍历字典的key值
for key in d:
print(key)
遍历字典
for key in d:
print(key, d[key])
字典的增加和删除
nbastar = {
'curry': 30,
'james': 23,
'kobe': 24
}
增加一个元素,key值存在更新,不存在添加
nbastar['rose'] = 1
print(nbastar)
添加多个,key值存在更新,不存在添加,用另一个字典去更新原来的字典
nbastar1 ={
'klay':11,
'durant':35
}
update方法的key值不能为数字
nbastar.update(nbastar1)
print(nbastar)
nbastar.update(wesborook=0)
print(nbastar)
setdefault添加key值,key值存在不修改,不存在则添加
nbastar.setdefault('curry',32)
print(nbastar)
nbastar.setdefault('paul',3)
print(nbastar)
nbastar2 = {
'curry': 30,
'james': 23,
'kobe': 24,
'harden': 13
}
del关键字
del nbastar2['harden']
print(nbastar2)
pop 删除指定的key的key-value值,如果存在,删除,并且返回删除key对应的value值
如果key不存在直接报错
player=nbastar2.pop('harden')
print(player)
print(nbastar2)
popitem删除最后一个key-value
player = nbastar2.popitem()
print(player)
print(nbastar2)
清空字典的内容
nbastar2.clear()
print(nbastar2)
字典的修改和查看
nbastar = {
'curry': 30,
'james': 23,
'kobe': 24
}
查看字典里面的key值
print(nbastar.keys())
查看字典里面的所有value值
print(nbastar.values())
遍历字典
for k,v in nbastar.items():
print(k,'----->',v)
for k in nbastar:
print(k,'---->',nbastar[k])
查看指定key对应的value值
key值不存在,程序就会报错
print(nbastar['curry'])
get 方法获取指定key对应的value值
如果key值存在,返回对应的value值
如果key值不存在,默认返回None,如果需要指定返回的值,传值即可
print(nbastar.get('harden'))
print(nbastar.get('harden','player not in nbastar'))
字典的练习
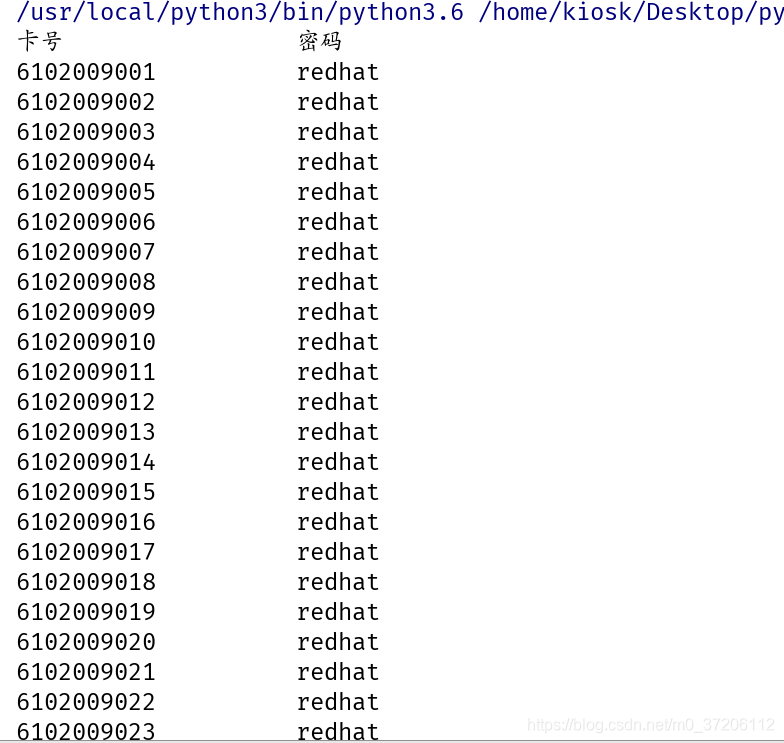
随机生成卡号,卡号为6102009开头,后面3位一次是(001,002…100)
默认卡号密码位‘redhat’
输出格式为
卡号 密码
6102009001 000000
“”"
card = []
for i in range(100):
s = '6102009%.3d' %(i+1)
card.append(s)
card_dict = {}.fromkeys(card,'redhat')
#print(card_dict)
print('卡号\t\t\t\t\t密码')
for k in card_dict:
print('%s\t\t\t%s' %(k,card_dict[k]))