如何区分深拷贝与浅拷贝,简单点来说,就是假设B复制了A,当修改A时,看B是否会发生变化,如果B也跟着变了,说明这是浅拷贝,拿人手短,如果B没变,那就是深拷贝,自食其力。
此篇文章中也会简单阐述到栈堆,基本数据类型与引用数据类型,因为这些概念能更好的让你理解深拷贝与浅拷贝。
我们来举个浅拷贝例子:
let a=[0,1,2,3,4],
b=a;
console.log(a===b);
a[0]=1;
console.log(a,b);

嗯?明明b复制了a,为啥修改数组a,数组b也跟着变了,这里我不禁陷入了沉思。
那么这里,就得引入基本数据类型与引用数据类型的概念了。
面试常问,基本数据类型有哪些,number,string,boolean,null,undefined五类。
引用数据类型(Object类)有常规名值对的无序对象{a:1},数组[1,2,3],以及函数等。
而这两类数据存储分别是这样的:
a.基本类型--名值存储在栈内存中,例如let a=1;

当你b=a复制时,栈内存会新开辟一个内存,例如这样:

所以当你此时修改a=2,对b并不会造成影响,因为此时的b已自食其力,翅膀硬了,不受a的影响了。当然,let a=1,b=a;虽然b不受a影响,但这也算不上深拷贝,因为深拷贝本身只针对较为复杂的object类型数据。
b.引用数据类型--名存在栈内存中,值存在于堆内存中,但是栈内存会提供一个引用的地址指向堆内存中的值,我们以上面浅拷贝的例子画个图:

当b=a进行拷贝时,其实复制的是a的引用地址,而并非堆里面的值。

而当我们a[0]=1时进行数组修改时,由于a与b指向的是同一个地址,所以自然b也受了影响,这就是所谓的浅拷贝了。

那,要是在堆内存中也开辟一个新的内存专门为b存放值,就像基本类型那样,起步就达到深拷贝的效果了

1.我们怎么去实现深拷贝呢,这里可以递归递归去复制所有层级属性。
这么我们封装一个深拷贝的函数

function deepClone(obj){
let objClone = Array.isArray(obj)?[]:{};
if(obj && typeof obj==="object"){
for(key in obj){
if(obj.hasOwnProperty(key)){
//判断ojb子元素是否为对象,如果是,递归复制
if(obj[key]&&typeof obj[key] ==="object"){
objClone[key] = deepClone(obj[key]);
}else{
//如果不是,简单复制
objClone[key] = obj[key];
}
}
}
}
return objClone;
}
let a=[1,2,3,4],
b=deepClone(a);
a[0]=2;
console.log(a,b);
可以看到

跟之前想象的一样,现在b脱离了a的控制,不再受a影响了。 这里再次强调,深拷贝,是拷贝对象各个层级的属性,可以看个例子。JQ里有一个extend方法也可以拷贝对象,我们来看看
let a=[1,2,3,4],
b=a.slice();
a[0]=2;
console.log(a,b);
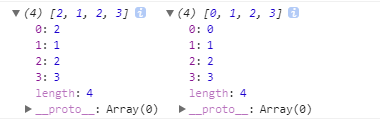
那是不是说slice方法也是深拷贝了,毕竟b也没受a的影响,上面说了,深拷贝是会拷贝所有曾经的属性,还是这个例子,我们把a改改
let a=[0,1,[2,3],4],
b=a.slice();
a[0]=1;
a[2][0]=1;
console.log(a,b);

拷贝的不彻底啊,b对象的一级属性确实不受影响了,但是二级属性还是没能拷贝成功,仍然脱离不了a的控制,说明slice根本不是真正的深拷贝。
这里引用知乎问答里面的一张图

第一层的属性确实深拷贝,拥有了独立的内存,但更深的属性却仍然公用了地址,所以才会造成上面的问题。
同理,concat方法与slice也存在这样的情况,他们都不是真正的深拷贝,这里需要注意。
2.除了递归,我们还可以借用JSON对象的parse和stringify
function deepClone(obj){
let _obj = JSON.stringify(obj),
objClone = JSON.parse(_obj);
return objClone
}
let a=[0,1,[2,3],4],
b=deepClone(a);
a[0]=1;
a[2][0]=1;
console.log(a,b);

可以看到,这下b是完全不受a的影响了。
附带说下,JSON.stringify与JSON.parse除了实现深拷贝,还能结合localStorage实现对象数组存储。有兴趣可以阅读博客这篇文章。
localStorage存储数组,对象,localStorage,sessionStorage存储数组对象
3.除了上面两种方法之外,我们还可以借用JQ的extend方法。
$.extend( [deep ], target, object1 [, objectN ] )
deep表示是否深拷贝,为true为深拷贝,为false,则为浅拷贝
target Object类型 目标对象,其他对象的成员属性将被附加到该对象上。
object1 objectN可选。 Object类型 第一个以及第N个被合并的对象。
let a=[0,1,[2,3],4],
b=$.extend(true,[],a);
a[0]=1;
a[2][0]=1;
console.log(a,b);
可以看到,效果与上面方法一样,只是需要依赖JQ库。
说了这么多,了解深拷贝也不仅仅是为了应付面试题,在实际开发中也是非常有用的。例如后台返回了一堆数据,你需要对这堆数据做操作,但多人开发情况下,你是没办法明确这堆数据是否有其它功能也需要使用,直接修改可能会造成隐性问题,深拷贝能帮你更安全安心的去操作数据,根据实际情况来使用深拷贝,大概就是这个意思。
首先得明白JSON.stringify()与JSON.parse()的作用,针对你的疑问,我们可以这样理解,前者能将一个对象转为json字符串(基本类型),后者能将json字符串还原成一个对象(引用类型)。
基本类型拷贝是直接在栈内存新开空间,直接复制一份名-值,两者互不影响。
而引用数据类型,比如对象,变量名在栈内存,值在堆内存,拷贝只是拷贝了堆内存提供的指向值的地址,而JSON.stringify()巧就巧在能将一个对象转换成字符串,也就是基本类型,那这里的原理就是先利用JSON.stringify()将对象转变成基本数据类型,然后使用了基本类型的拷贝方式,再利用JSON.parse()将这个字符串还原成一个对象,达到了深拷贝的目的。
JSON.stringify()对对象的转换,避开了只拷贝地址指向,无法直接拷贝值本身的问题,不知道这样说你能否理解。
JSON.stringify()与JSON.parse()的作用还是挺强大的,如果有兴趣,可以看看博主这篇关于这两个方法的小归纳。
https://www.cnblogs.com/echolun/p/9631836.html