曾经,我把目光放在你身体上四分位的地方,发现了世界的美好。。。
之后,山水流转,时光荏苒,不再从前。。。
此一文,献给过往。
先上张图:好奇怪,为什么是这么个比例[皱眉]
这篇文章分为两个部分,python爬虫和数据分析。爬取京东bra一些数据,并进行分析,在上帝视角看一看bra的秘密。
第一部分,爬虫部分。
爬虫部分利用python和selenium包,爬取京东数据,将数据保存在数据库中。
第二部分,将爬到的数据使用pandas包和matplotlib包进行清洗,在可视化
第一步,先导入包,需要导入的包有,selenium包,用来模仿浏览器,lxml包,用来分析网页信息,显示等待和隐式等待包,数据库包。如下
from selenium import webdriver
import time
from lxml import etree
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from databases import Write_databases然后,写打开浏览器接口,再获取URL列表时,使用PhantomJS浏览器。
#打开浏览器,返回driver
def open_web():
driver = webdriver.PhantomJS()
return driver获取京东商城前100也的bra商品详情页的URL,(前100页已经足够了,50页之后的商品就基本没有销售信息了)
#获取bra列表,获取每个bra的ID,生成详情页的url,返回url列表
def get_bra_list(driver,url):
bra_list_urls = [] #定义URL列表
driver.get(url)#打开浏览器
i=100
while i>0:#设置爬取前100页
html = etree.HTML(driver.page_source)
bra_lists = html.xpath(".//div[@id='J_goodsList']/ul/li")
for bra_list in bra_lists:
bra_id = bra_list.xpath(".//div[@class='p-price']/strong/@class")
bra_detail_url = 'https://item.jd.com/'+bra_id[0].split('_')[1]+'.html'
bra_list_urls.append(bra_detail_url)
next_btn = driver.find_element_by_class_name('pn-next')#某一页数据爬取完成时,点击下一页按钮
next_btn.click()
i -= 1
print("=*"*20+str(i))
return bra_list_urls得到URL列表之后,再按照列表中的URL一个一个爬取即可。
爬取详细URL相应信息,进入详情页面之后,首先需要爬取价格,然后点击商品评价,如图

然后再爬取商品评价中的颜色,尺寸,时间
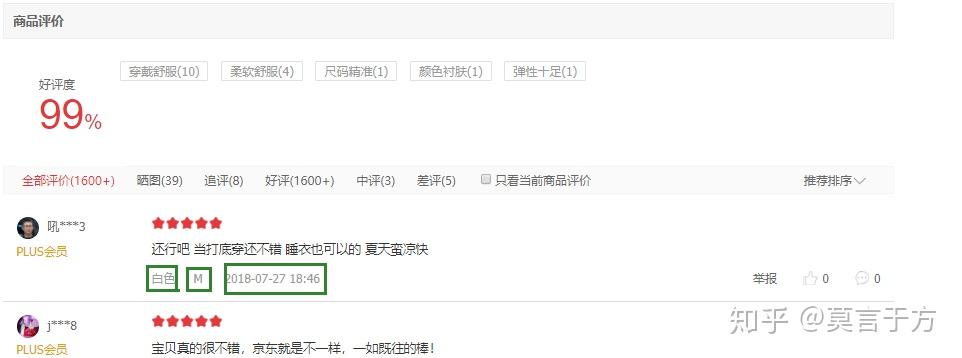
如下步骤,这次,使用Chrome浏览器
#进入详情页获取每个bra的信息,
def get_bra_info(bra_list_urls):
path = r'C:\Users\yuy-com\web_driver\chromedriver.exe'#设置Chrome浏览器的地址
sel_driver = webdriver.Chrome(executable_path=path)
sel_driver.maximize_window()#将浏览器设置为最大化
time.sleep(1)
for bra_url in bra_list_urls:
sel_driver.get(url=bra_url)#打开详情页面的URL
get_current(sel_driver)#开始获取数据
#获取评论信息,返回评论信息的列表
def get_current(driver):
bra_de_info = []
write_data = Write_databases()#初始化数据库类
while True:
souce_html = driver.page_source
html = etree.HTML(souce_html)
bra_text = html.xpath(".//div[@class='p-parameter']/ul[2]/li/text()")#获取商品介绍信息
#获取商品评价
current_num = html.xpath(".//div[contains(@class,'tab-main')]/ul/li[5]/s/text()")[0].split('(')[1].split(')')[0]
#如果商品评价为0,则直接跳过
if current_num == '0':
print('无评价!')
continue
#补货商品评价标签,点击
current = driver.find_element(By.XPATH, ".//div[contains(@class,'tab-main')]/ul/li[5]")
current.click()
#解析网页
souce_h = etree.HTML(driver.page_source)
current_list = souce_h.xpath(".//div[@class='tab-con']/div[1]/div")
price = souce_h.xpath(".//div[@class='dd']/span/span[2]/text()")[0]#获取价格
brand = souce_h.xpath(".//div[@class='p-parameter']/ul[1]/li/a/text()")[0]#获取品牌
bra = {}
for curr_info in current_list:
#获取商品颜色,尺寸和时间信息
info = curr_info.xpath(".//div[@class='comment-message']/div/span//text()")
if info:
color = info[0]
size = info[1]
times = info[2]
bra['bra_name'] = brand
bra['bra_color'] = color
bra['bra_size'] = size
bra['bra_time'] = times
bra['bra_price'] = price
bra['bra_text'] = " ".join(bra_text)
print('名称:{},颜色:{},尺寸:{},时间:{},价格:{},描述:{}'.format(brand,color,size, times, price," ".join(bra_text)))
write_data.insert_data(bra)#写入数据库
bra_de_info.append(bra)
try:
点击下一页获取评论信息
next_btn = driver.find_element(By.XPATH, './/a[@class="ui-pager-next"]')
WebDriverWait(driver,1000).until(EC.element_to_be_clickable((By.CLASS_NAME,"ui-pager-next")))
next_btn.click()
except:
return bra_de_info如上步骤数据便可以爬下来了,写入数据库之前,我们还需要配置数据库,在此我新建一个文件配置。如下
import pymysql#导入包
class Write_databases():
def __init__(self):
self.db = pymysql.connect(
host = '127.0.0.1',
user = 'root',
password = 'root',
database = 'bra_jd',
port = 3306
)
self.cursor = self.db.cursor()#连接数据库
#插入数据接口
def insert_data(self,data):
sql = '''
insert into bra_table(id,bra_name,bra_price,bra_color,bra_size,bra_time,bra_text)
values(null,%s,%s,%s,%s,%s,%s)
'''
self.cursor.execute(sql,(data['bra_name'],data['bra_price'],data['bra_color'],data['bra_size'],data['bra_time'],data['bra_text']))
self.db.commit()#提交
#关闭连接
def close_databases(self):
self.db.close()这样就可以吧数据全部保存在数据库中了。大约有两万条数据,如下图所示
我们先看下数据量:有两万5前多条

数据清洗:在这里,我现将数据库中的数据导出到cvs文件,然后pandas包载入文件。如图:
首先清洗尺寸数据,清洗之前先看尺寸数据的情况,真的是一片杂乱。

看到这,我的头一下就很大,慢慢分析吧,分为如下步骤,
首先,先将标记为L,S,M,XL(码)的数据删除
bra_da = bra_da[(bra_da['bra_size'] != 'S')
&(bra_da['bra_size'] != 'L')&(bra_da['bra_size'] != 'M')&
(bra_da['bra_size'] != 'X')&(bra_da['bra_size'] != 'XL')&
(bra_da['bra_size'] != 'L码')&(bra_da['bra_size'] != 'M码')&
(bra_da['bra_size'] != 'X码')&(bra_da['bra_size'] != 'XL码')&
(bra_da['bra_size'] != 'XXL码')&(bra_da['bra_size'] != 'XXL')]看了下,虽然少了一点,但是还有很多,继续
将含有“建议”,“均码”,“通杯”的数据删除。因为这些数据没有明确的指向大小,可以视为垃圾数据。如果含有加号,则取加好之前的数据,否则写0,最后将写0的数据删除,新建一列,用MAP函数实现
def pass_cup_del(bra_data):
if "+" in bra_data:
return xxx.split("+")[0]
elif "建议" in bra_data:
return '0'
elif "均码" in bra_data:
return '0'
elif "通杯" in bra_data:
return '0'
else:
return bra_data
bra_da['bra_size2'] = bra_da['bra_size'].map(pass_cup_del)
分析之后还是很凌乱,决定,将括号删去,只取括号左边的数据:再加一列数据,再删除标记为L,S,M,XL(码)的数据,将数据框的名称修改。
def brackets_delete(bra_da):
if "(" in bra_da:
return bra_da.split("(")[0]
else:
return bra_da
bra_da['bra_size3'] = bra_da['bra_size2'].map(fun2).map(fun1)
bra_data = bra_da[(bra_da['bra_size3'] != 'L码')&(bra_da['bra_size3'] != 'M码')&(bra_da['bra_size3'] != 'X码')&(bra_da['bra_size3'] != 'XL码')&(bra_da['bra_size3'] != 'XXL码')]
bra_data.drop(['bra_size2','bra_size'],axis=1,inplace=True)
bra_da_o = bra_data[bra_data['bra_size3'] == '0']
bra_data.drop(bra_da_o.index,inplace=True)到这时,已经差不多了,数据已经变得比较干净了,然后将有A的数据换成A,B,C,D,E,F一样处理
def set_abcd_vlaue(data):
if 'A' in data:
return 'A'
elif 'B' in data:
return 'B'
elif 'C' in data:
return 'C'
elif 'E' in data:
return 'E'
elif 'F' in data:
return 'F'
elif 'D' in data:
return 'D'
else:
return '0'
bra_data['bra_size'] = bra_data['bra_size3'].map(set_abcd_vlaue)
bra_da_o1 = bra_data[bra_data['bra_size'] == '0']
bra_data.drop(bra_da_o1.index,inplace=True)
如上图,这样就处理好了。
然后处理颜色,先看下颜色,竟然五颜六色。[捂脸]

竟然,这么多颜色,牛X
我将颜色分析了下,准备分为如下色彩:酒红,枣红,钴蓝,藏青,紫灰,粉,肤,红,蓝,杏,紫,绿,白,黑,啡,灰,棕
开始处理:
def set_color(color):
if '酒红' in color:
return '酒红'
elif '枣红' in color:
return '枣红'
elif '钴蓝' in color:
return '钴蓝'
elif '藏青' in color:
return '藏青'
elif '粉' in color:
return '粉'
elif '肤' in color:
return '肤'
elif '红' in color:
return '红'
elif '蓝' in color:
return '蓝'
elif '杏' in color:
return '杏'
elif '紫' in color:
return '紫'
elif '绿' in color:
return '绿'
elif '白' in color:
return '白'
elif '黑' in color:
return '黑'
elif '啡' in color:
return '啡'
elif '灰' in color:
return '灰'
elif '棕' in color:
return '棕'
else:
return '0'
bra_data['color'] = bra_data['bra_color'].map(set_color)
bra_color_o = bra_data[bra_data['color'] == '0']
bra_data.drop(bra_color_o.index,inplace=True)
bra_data.drop(['bra_color','bra_size3'],axis=1,inplace=True)
print(set(bra_data['color']))和之前处理的套路一样,先将有关的颜色修改,最后删除无关的颜色项

果然,颜色也分析好了。
看一下处理之后还有多少数据:绳一万六千多条数据了,应该还能说明点问题。

接下来就是可视化了。可视化主要分析如下几项,
1.颜色柱状图:我们根据在京东爬的销售数据,可以查看在所销售的bra中,颜色的分部
y_color_valse = []
bra_color = bra_data['color']
color_list = set(bra_color)
for x in color_list:
num = len(bra_data[bra_data['color'] == x])
y_color_valse.append(num)
plt.figure()
plt.bar(list(color_list),y_color_valse)
plt.title("bra_color")
plt.show()图如下:
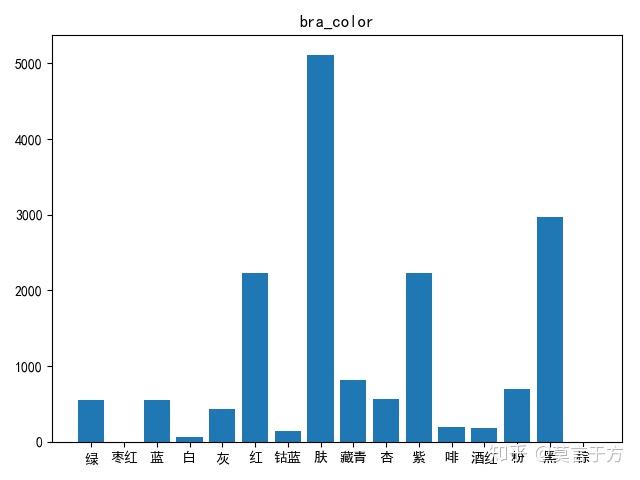
可见,肤色,黑色,红色,紫色,占统治地位,白色酒红数量较少。我喜欢的粉色,竟然不多,太神奇了。
我们在画一个颜色的饼图:
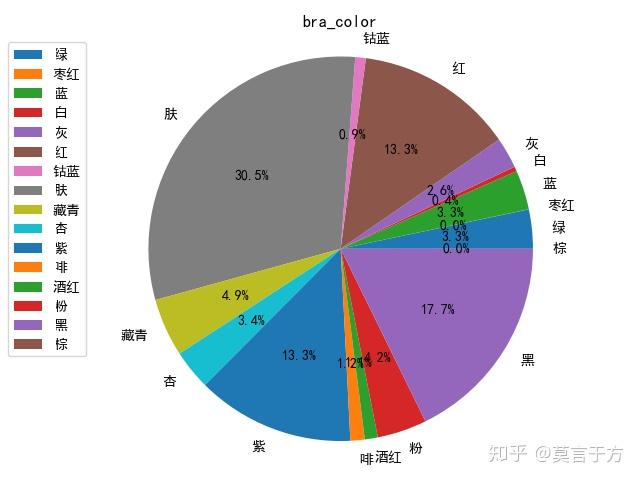
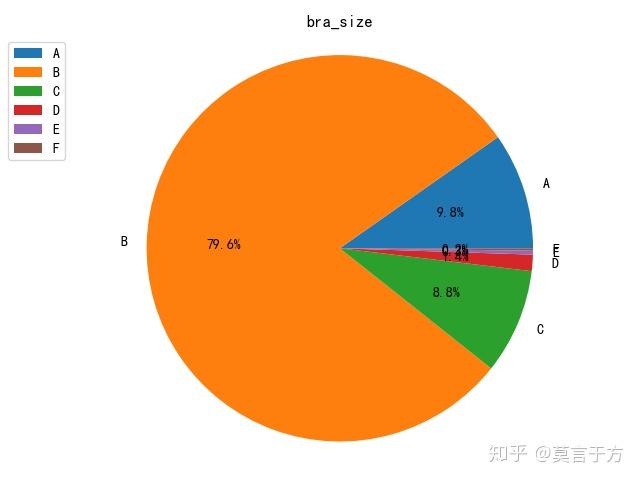
第二个是查看尺寸的分部
bra_size_label = ['A','B','C','D','E','F']
y_bra_size = []
for bra in bra_size_label:
num = len(bra_data[bra_data['bra_size'] == bra])
y_bra_size.append(num)
plt.figure()
plt.pie(y_bra_size,labels=bra_size_label,autopct='%1.1f%%')
plt.title("bra_size")
plt.axis('equal')
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.show()如图:B罩杯最多,[偷笑]
在这,我们再看看各个品牌的分部:
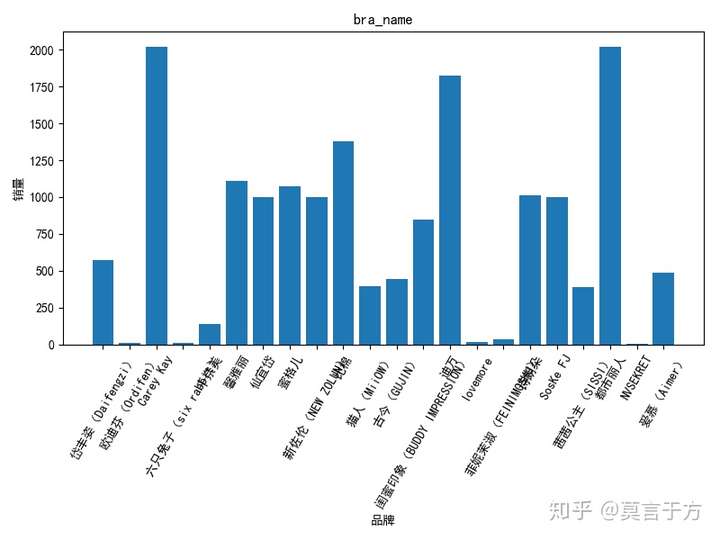
排名最多的是,carey Key,迪万,都市丽人,为啥我只听过都市丽人呢?