1. 引言
从 3.0 版本开始,redis 具备了集群功能,实现了分布式、容错、去中心化等特性,在生产环境中对于保证数据一致性和安全性、提高系统响应能力都有着很必要的意义。
本文我们就来介绍 redis 集群的三种搭建模式和搭建方法。
1.1. redis 集群的特性
redis 集群的目标是线性可扩展性和保证最终一致性,因此,redis 集群不存在中心节点或代理节点。
同时,一致性的保证是建立在一部分容错性牺牲的基础上的,系统通过主从节点的模式在保证对节点失效具有有限抵抗力的前提下,尽可能保证数据的一致性。
redis 集群实现了节点的自动发现、master 的自动选举、热分片、ASK 转向和 MOVED 转向等机制。
可以参考官方文档:
https://redis.io/topics/cluster-tutorial。
1.2. 集群端口
无论是哪种模式的 redis 集群,都需要指定服务端口(默认为 6379),但 redis 实际上是通过服务端口 + 10000 的端口来进行数据同步的。
因此,如果集群无法建立或同步无法进行,除了需要考虑服务端口是否连通以外,还需要检测同步端口的可用性。
2. 主从模式集群
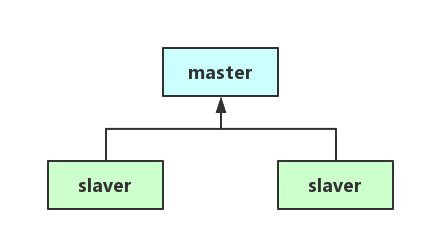
redis 支持简单的主从单向同步的集群结构,主节点负责写入数据,同步到从节点,从节点进行只读操作。
主从单向同步的集群结构可以有效提升系统的吞吐量,同时保证数据的安全性。
2.1. 搭建方法
主从模式的集群搭建方法非常简单,只需要在从节点的配置文件中写入:
slaveof 112.126.74.142 6379
这样,启动该节点后,他就成为了 112.126.74.142:6379 节点的从节点。
2.2. 从节点的写入操作
需要注意的是,从节点默认也可以进行读写操作,但从节点的写入将会导致这部分数据不会被同步,从而造成数据不一致的问题。
可以通过指定配置来强制从节点不可写入:
replica-read-only yes
此时对从节点进行写入操作会报错:
(error) READONLY You can't write against a read only replica.
2.3. 从节点的同步机制
在 redis-cli 中,通过执行 info replication 可以看到集群信息。
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:462
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:201640b5a63c036087b7a459245a6f6a699b8a36
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:462
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:462
其中有两个标识:

- master_replid – 长度为41个字节的字符串,主节点标识
- master_replid2 – 该节点上一次连接主实例的实例 master_replid
如果 A 是集群主节点,B 是 A 的从节点,C 是 B 的从节点,那么 C 的 master_replid 则存储的是 A 的节点标识,这意味着,如果 B 节点非只读,B 节点内写入的数据并不会同步到 C 节点。
数据的同步就是基于 master_replid 与 master_repl_offset 两个字段进行的,每个从节点都保存了当前已同步数据的偏移,从而实现部分同步。
主节点一旦重启,master_replid 就会发生变动,从而造成所有从节点重新同步全量数据,由于 master_replid 是自动生成的,我们并不能干涉这一过程。
3. 高可用集群 – HA
上面所描述的主从集群存在一个问题,那就是当主节点宕机时,将导致整个集群无法提供服务。
为了保证集群的容错性,redis 提供了官方的 HA 方案,他是通过建立哨兵节点或哨兵集群来实现对 master 的监控和对 slaver 的提权。
哨兵节点通过监控 redis 集群中 master 的状态实现当 master 状态异常时,在 master 的多个 slaver 中选举一个并通过发送 SLAVEOF NO ONE 命令提升其为 master 节点,同时自动发送 SLAVE OF 命令给其他 slaver 节点,从而让集群重新工作起来,这个过程称为 failover 过程。
多个哨兵节点可以组成集群,从而避免某个哨兵节点宕机的情况发生。
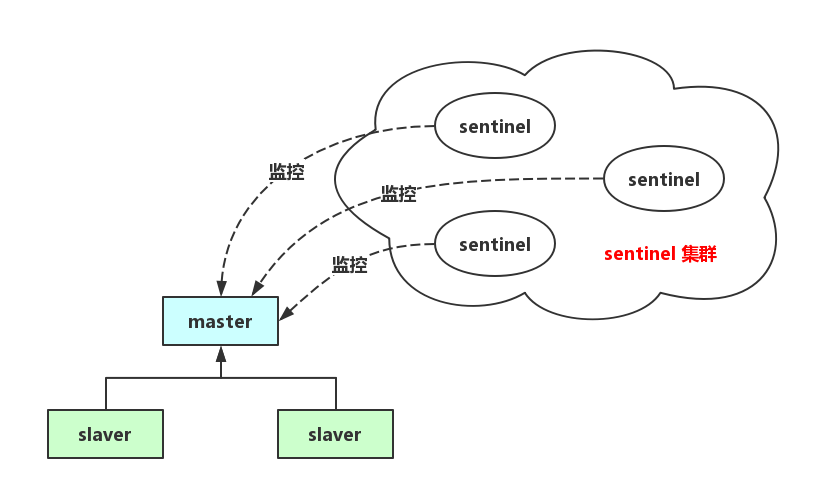
3.1. 集群搭建
首先,我们需要创建哨兵节点配置文件:
port 20086 #默认端口26379
dir "/tmp"
logfile "/var/log/redis/sentinel_20086.log"
daemonize yes
# 配置监视的进群的主节点 ip 和端口 1 表示至少需要几个哨兵统一认定才可以做出判断
sentinel monitor mymaster 127.0.0.1 6380 1
# 表示如果 5s 内 mymaster 没响应,就认为 SDOWN
sentinel down-after-milliseconds mymaster 5000
# 表示如果15秒后,mysater 仍没活过来,则启动 failover,从剩下从节点序曲新的主节点
sentinel failover-timeout mymaster 15000
# 在发生failover主备切换时,这个选项指定了最多可以有多少个slave同时对新的master进行同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave处于不能处理命令请求的状态
sentinel parallel-syncs T1 1
# sentinel 连接设置了密码和主从
# sentinel auth-pass <master_name> xxxxx
# 发生切换之后执行的一个自定义脚本
# sentinel client-reconfig-script <master-name> <script-path>
通过 redis-sentinel 命令指定配置文件启动即可。
4. redis-cluster
尽管可以使用哨兵主从集群实现可用性保证,但是这种实现方式每个节点的数据都是全量复制,数据存放量存在着局限性,受限于内存最小的节点。
为了增大存储性能,实现真正的分布式存储系统,sharding 的方案是非常有必要的。
所谓的 sharding 方案指的是将全量数据分成 16384 个散列槽,我们只需采用密钥模数 16384 的 CRC16 就可以计算 key 所在的散列槽位置,这样,每个节点容纳全部 16384 个散列槽中的一部分,所有 master 节点共同组成完整的数据。
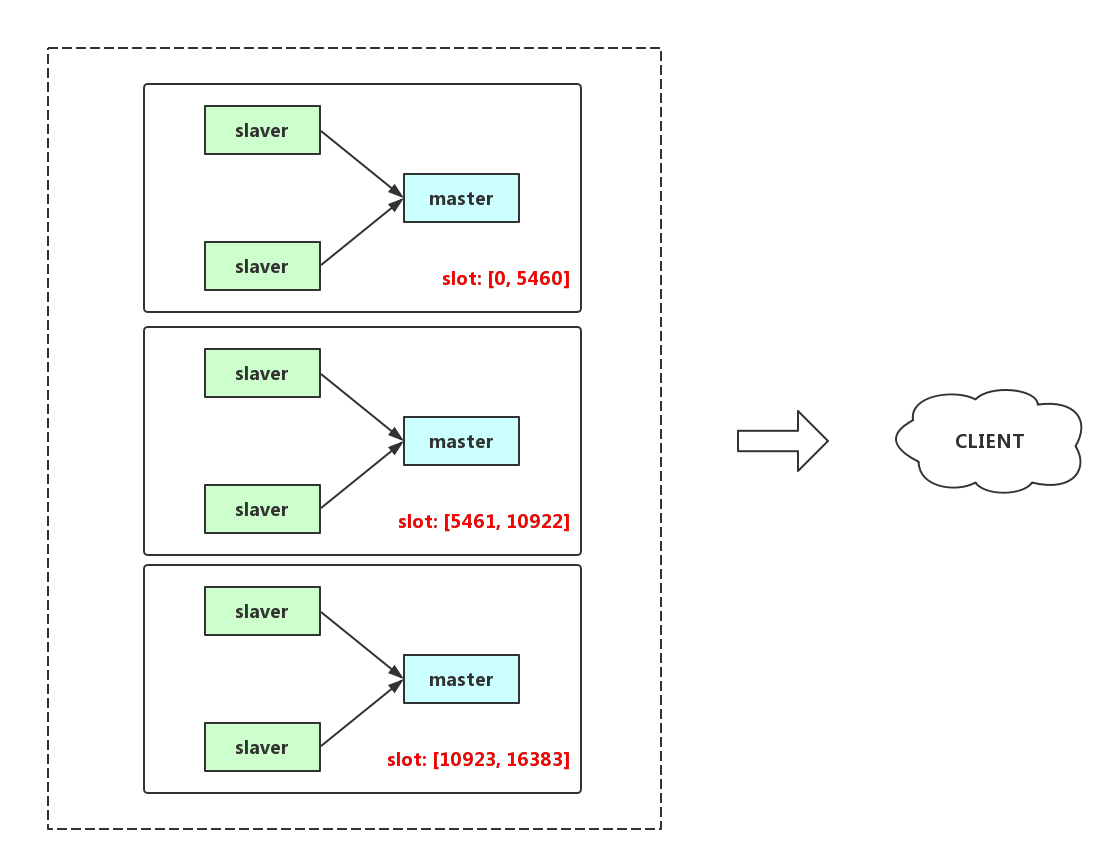
4.1. 配置集群
如果需要 sharding 模式与主从模式结合使用,那么需要在建立集群时通过命令指定,而不能在配置文件中添加 slaveof 配置项。
首先修改 redis 配置打开 cluster 配置:
################################ REDIS CLUSTER ###############################
#
# ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# WARNING EXPERIMENTAL: Redis Cluster is considered to be stable code, however
# in order to mark it as "mature" we need to wait for a non trivial percentage
# of users to deploy it in production.
# ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
#
# Normal Redis instances can't be part of a Redis Cluster; only nodes that are
# started as cluster nodes can. In order to start a Redis instance as a
# cluster node enable the cluster support uncommenting the following:
#
cluster-enabled yes
# Every cluster node has a cluster configuration file. This file is not
# intended to be edited by hand. It is created and updated by Redis nodes.
# Every Redis Cluster node requires a different cluster configuration file.
# Make sure that instances running in the same system do not have
# overlapping cluster configuration file names.
#
cluster-config-file /etc/redis/nodes-6379.conf
# Cluster node timeout is the amount of milliseconds a node must be unreachable
# for it to be considered in failure state.
# Most other internal time limits are multiple of the node timeout.
#
cluster-node-timeout 15000
cluster-config-file 配置的文件 redis 集群启动后会自动写入集群信息,如果要删除集群重建,最暴力的方法就是删除集群中每台机器上的 cluster-config-file 配置文件。
其他配置项还有:
- cluster-slave-validity-factor – slave节点与master断线的时间是否过长,如果 (node-timeout * slave-validity-factor) + repl-ping-slave-period 大于了该值,则 slave 不会被提升为 master,默认值为 10
- cluster-migration-barrier – master 的最小 slaver 数,避免组建集群时 slaver 不能平均分配的情况发生,默认为 0
- cluster-require-full-coverage – 是否 sharding 所有 slot 才能够提供服务,默认为 yes,如果设置为 no,可以在 slot 没有全部分配的时候提供服务,不建议,这样会造成分区的时候,小分区的master一直在接受写请求,而造成很长时间数据不一致
4.2. 启动集群
首先,更新完配置后,需要启动所有节点的 redis-server。
redis5.0 版本以后集群操作从 redis-trib.rb 命令迁移到 redis-cli,通过 redis-cli --cluster 命令就可以组建集群了。
redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1
–cluster-replicas 指定了集群中每个 master 节点的 slaver 数量。
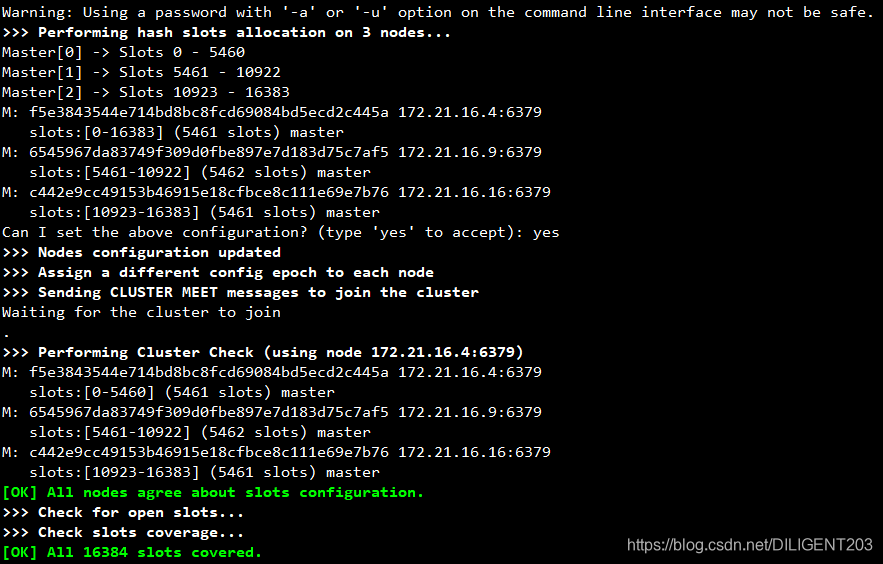
- 需要注意的是,至少三台 master 主机才能组成一个 redis-cluster,并且集群中的所有节点初始时必须不能有数据
4.3. 报错处理 – Not all 16384 slots are covered by nodes
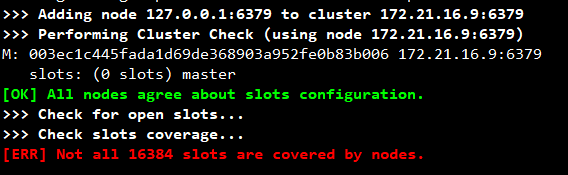
可以通过 redis-cli --cluster fix 命令修复,让集群中槽位重新分布。
通过执行 redis-cli --cluster check host:port 可以检测集群中的槽位分布情况。
官方文档中还介绍了集群的其他操作,例如节点的添加和删除,可以进一步阅读。
4.4. MOVED xxx xxx.xxx.xxx.xxx:xxxx
使用 redis-cli 连接集群进行操作,会出现 MOVED 错误。

这是因为出现了 MOVED 转向,提示客户端转向分片所在节点进行操作,关于 MOVED 转向和 ASK 转向我们下一篇文章中再来介绍。
redis 要求客户端自己处理 MOVED 转向和 ASK 转向,所以 redis-cli 中已经拥有了处理逻辑,只需在登录时增加 -c 参数即可自动进行转向,也就不会再报出相应的错误了。

5. 参考资料
https://redis.io/topics/cluster-tutorial。
https://blog.csdn.net/qq_20597727/article/details/83385737。
https://www.cnblogs.com/vansky/p/9130647.html。
https://www.cnblogs.com/zhoujinyi/p/5570024.html。
https://blog.csdn.net/vtopqx/article/details/50235737。
https://blog.csdn.net/huwei2003/article/details/50973893。