/**************************************************list.c************************************/
#define NULL 0
struct list {
struct list *next;
};
一上来就搞事情,定义一个结构类型叫struct list 里面只有一个成员,还是这个结构体类型的指针,看字面的意思是想说指向下一个结构体,可是这样的list有啥意义,把一堆结构体串成链表,然后就没然后了,什么内容也没有,按理说结构体里应该得有个data才对吧。一开始的时候我还真是在这个上面费了好大功夫,才弄懂这个作者到底想干嘛。
我们就从某一个操作list的函数说起吧,我也是从这个函数里找到灵感,才明白上面这个结构体到底想干嘛。光看这个函数还是不能明白的,我们再加多一些用到这个list的代码。
/*********************nbr_table.c******************************/
typedef struct nbr_table_key {
struct nbr_table_key *next;
linkaddr_t lladdr;
} nbr_table_key_t;
MEMB(neighbor_addr_mem, nbr_table_key_t, NBR_TABLE_MAX_NEIGHBORS);
LIST(nbr_table_keys);
nbr_table_key_t *key;
key = nbr_table_allocate(reason, data);
list_add(nbr_table_keys, key);
/*********************************************************************/
上面这些代码在nbr_table.c中不是在一起,是我摘录下来放到一起的。我们来一句一句理解,一开始定义了一个结构体类型,叫struct nbr_table_key还用typedef给它另外取了个名字叫nbr_table_key_t,MEMB这个宏可以理解为定义了一个nbr_table_key_t类型的数组,接着就用到在list.h里的宏定义LIST,我们知道用这个宏的话就是定义两个变量,一个是void类型指针,一个是指向这个指针的指针。再接下来一句定义了一个nbr_table_key_t结构体类型的指针,接下来这句函数意思就是说向MEMB宏定义的数组里申请一个没人用的变量,并把这个变量的地址赋给刚刚定义的nbr_table_key_t类型指针,这样子这个key指针才有所指向,而不是NULL。然后就调用了list_add函数,函数代码如下。
void list_add(list_t list, void *item)
{
struct list *l;
/* Make sure not to add the same element twice */
list_remove(list, item);
((struct list *)item)->next = NULL;
l = list_tail(list);
if(l == NULL)
{
*list = item;
}
else
{
l->next = item;
}
}
这样子我们就知道了,函数里的list就是我们刚刚用宏LIST定义的那个指向指针的指针变量,而这个item就是我们刚刚定义的那个nbr_table_key_t类型的结构体指针。list_remove函数我们暂时不展开,展开的话就被绕进入了,我们看注释知道这个函数是为了检查列表里有没有跟item重复的成员,怎么才算重复呢,就是地址相同,看看有没有哪个成员的内存地址跟传入函数的item值相等。待会我们会讲到这个函数,这里不详细说。
关键的语句来了,灵感从这迸发,
((struct list *)item)->next = NULL;
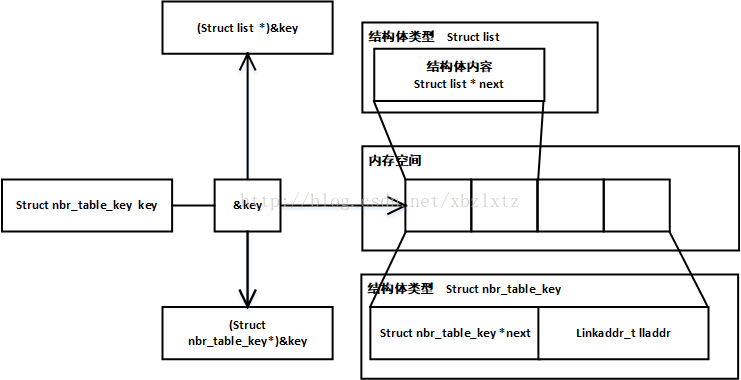
还记得我们一开始说到的怪怪的结构体么,里面只有一个本类型的指针,字面意思是指向下一个结构体。这里居然把我们传进来的nbr_table_keys_t类型结构体指针强转成struct list结构体类型了。巧的是nbr_table_keys_t结构体的第一个成员刚好就叫next,跟struct list一样。其实这是作者精心安排的。这里插播一下关于这个类型强转在内存里是怎么个原理,为什么这样强转以后访问的next成员就刚好是nbr_table_keys_t里的next。
假设我们定义了key变量,指定了是什么类型的,那么就会在内存空间开辟一个指定类型大小的空间。如上图的key变量。&key就是对key取址,得到的就是key变量在内存空间的首地址,如果这个时候你定义一个变量struct nbr_table_keys_t* key_ptr。然后 key_ptr = &key,编译是不会错的,因为这个指针类型跟变量类型一致,如果你定义 struct list* list_ptr = &key,编译肯定报错,类型不匹配。编译器为啥要检测类型匹配呢,因为你定义一个指针的时候是有指定类型的,这个类型就决定了指针在解引用的时候是怎么对内存进行操作的,比如说int*就是把指针指向的地址开始四个字节取出来,char*就是把指针指向地址开始一个字节取出来。编译器检测类型匹配就是怕你乱来,如果你明明在内存中开辟了char类型的空间,然后用int*指针去解引用,这不就出事了么。但是C语言偏偏还就允许出现类型不匹配,strcut list* list_ptr = &key不是不行么,那我就struct list* list_ptr = (struct list *)&key,强转,编译通过。说了这么多,意思就是C语言允许你用适当的手段,实现开辟内存时一种类型,使用内存时可以是各种类型,这很危险,但是也可以很强大。比如我们在讨论的这个。
就如上图中所示,我们传进函数的是nbr_table_key_t指针,但是在用的时候是struct list,那么就会有一段空间是访问不到的。在一个系统里,指针类型的变量,不管是何种类型的指针,均占用一样多的内存空间,因为指针变量存的是地址,不管何种类型的变量其地址都一样长,所以作者就巧妙安排struct list 和nbr_table_key_t第一个成员名字一样,而且都是指针。分析到这就明白为何strcut list结构体只有一个指针变量了,为了安全啊!list这个模块就是为了实现链表的各种操作,链表的每个单元总是会携带数据的嘛,为了不同的目的携带的数据都是不同的,但是链表的操作有很多都是一样的,插入单元,删除单元,取第一个,取最后一个等等。如何能够让不同链表单元类型的链表共享一样的操作呢,作者就想出了这么一个法子。
到此一切通顺了
,
((struct list *)item)->next = NULL;意思就是说把key指针指向的nbr_table_key_t结构体变量中的next成员赋值为NULL
。接着
l = list_tail(list); 找列表的尾,假设我们这时候列表是空的,那么就会返还NULL。接着往下看
if(l == NULL)
{
*list = item;
}
else
{
l->next = item;
}
如果是NULL,那么就把key指针赋值给用LIST宏定义的那个指针变量。因为传入函数的list是指向指针的指针,所以*list就是那个指针变量了。那么就会是如图的关系
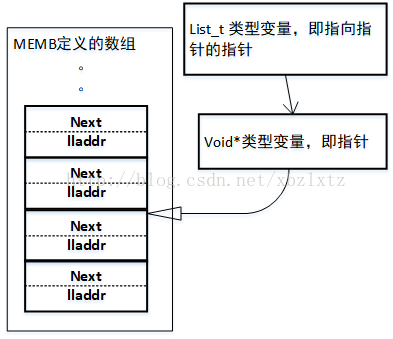
如果再一次调用list_add函数,把数组里另外一个结构体地址作为item,那么执行到if语句的时候,就会到另外一个分支 I->next = item。这里的I就是链表最后一个单元。那么就会是下图
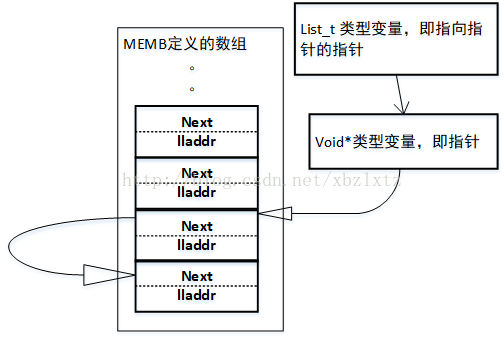
可以想象得到如果一直调用list_add的话就会成为一个长长的链表。