多线程环境中,通过队列可以很容易实现数据共享,比如经典的“生产者”和“消费者”模型中,通过队列可以很便利地实现两者之间的数据共享。假设我们有若干生产者线程,另外又有若干个消费者线程。如果生产者线程需要把准备好的数据共享给消费者线程,利用队列的方式来传递数据,就可以很方便地解决他们之间的数据共享问题。但如果生产者和消费者在某个时间段内,万一发生数据处理速度不匹配的情况呢?理想情况下,如果生产者产出数据的速度大于消费者消费的速度,并且当生产出来的数据累积到一定程度的时候,那么生产者必须暂停等待一下(阻塞生产者线程),以便等待消费者线程把累积的数据处理完毕,反之亦然。
阻塞队BlockingQueue继承自Queue。
![]()
除了实现了Queue的方法之外,还扩展了两个阻塞方法。
put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续.
take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到BlockingQueue有新的数据被加入;
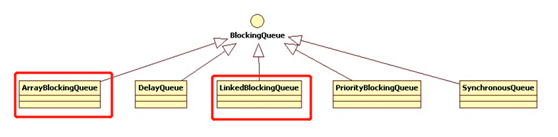
ArrayBlockingQueue和LinkedBlockingQueue是两个最普通也是最常用的阻塞队列,一般情况下,在处理多线程间的生产者消费者问题,使用这两个类足以。
1. ArrayBlockingQueue
基于数组的阻塞队列实现,在ArrayBlockingQueue内部,维护了一个定长数组,以便缓存队列中的数据对象,这是一个常用的阻塞队列,除了一个定长数组外,ArrayBlockingQueue内部还保存着两个整形变量putindex,takeindex,分别标识着队列的头部和尾部在数组中的位置。其结构图过于简单,不再画出来。
现在直接来看插入队列的实现,如下图所示:
实现很简单,直接在数组的putindex的位置放入这个新元素就可以了,
放入之后触发获取等待中的获取线程。

注意了,中间还有一句,如果放入新元素后putindex等于数组长度了,就把putindex置为0,什么意思呢?就是又从数组的第一个位置开始放入数据。有人可能就又疑问了,又从第一个元素开始放新插入的元素,那不是会覆盖之前插入的第一个元素吗?不会的,因为调用入队操作的offer,put等方法都做了判断,如果数组满了,是不会插入新元素进去的。而是等元素被取走之后,数组没满才会在这个位置插入新元素。非常简单巧妙却非常实用的设计。再结合出队方法,就可以知道这个的实现是何等的轻量级。出队方法如下图:

出队也很简单,直接取出数组takeindex位置的数就行了,取出之后,再把这个位置置空。如果下一次take的位置等于数组的长度了,那么就又从0开始取。取完之后,通知等待中的生产线程可以生产了。
利用这种方式,入队和出队操作,如此简单便捷轻量级,不需要像对普通数组作增删一样,要移动整个数组。
正是因为如此简单,所以入会和出队方法offer,poll这些,使用了同一个锁对像,效率也很高。而不像LinkedBlockingQueue,读和取使用两个不同的锁对象。
2. LinkedBlockingQueue
基于链表的阻塞队列,同ArrayListBlockingQueue类似,其内部也维持着一个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据时,队列会从生产者手中获取数据,并缓存在队列内部,而生产者立即返回;只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。
LinkedBlockingQueue的阻塞方法的插入和取出的实现其实非常简单。插入的时候,就是看当前容量是不是已经最大了,如果是就通过Condition类的await中断线程,让出锁等待其他线程执行取出方法后,调用Condition类的signal()重新触发执行。

取出的时候,也很简单,如果没有就释放锁进入等待,等待其他线程执行插入方法后被唤醒。

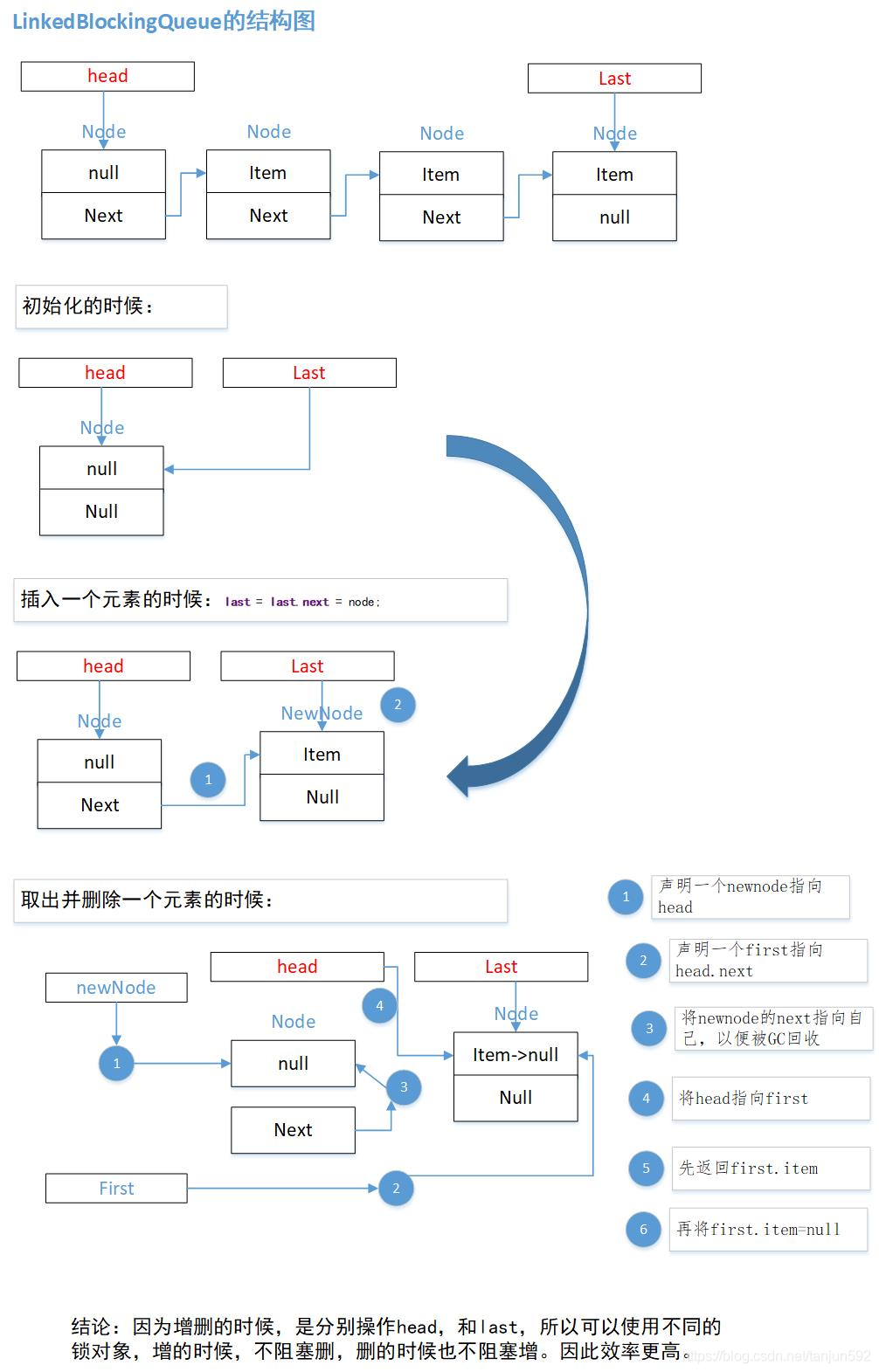
最大的不同,ABQ虽然用一个锁对象,但是增删快。LBQ虽然用两个锁对象,但是增删之前还要封装成Node对象,也有时间消耗,对GC也有影响。所以真不好说什么情况下用哪一个实现类了。只有在实际情况测试了。