Java内存模型
JMM(java内存模型)
java虚拟机有自己的内存模型(Java Memory Model,JMM),JMM可以屏蔽掉各种硬件和操作系统的内存访问差异,以实现让java程序在各种平台下都能达到一致的内存访问效果。
JMM决定一个线程对共享变量的写入何时对另一个线程可见,JMM定义了线程和主内存之间的抽象关系:共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存保存了被该线程使用到的主内存的副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存中的变量。这三者之间的交互关系如下
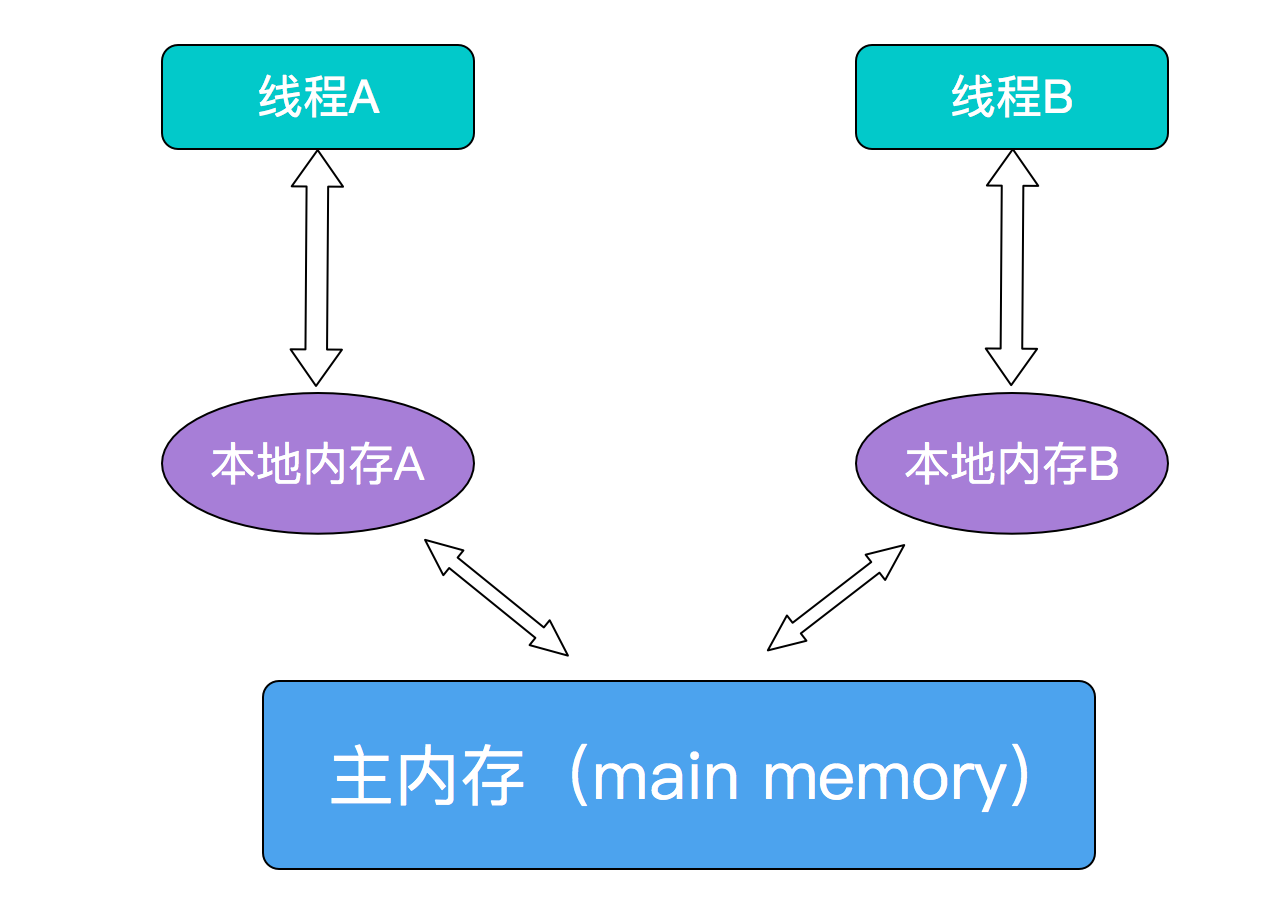
计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。
也就是,当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。举个简单的例子,比如下面的这段代码:
i = i + 1;
当线程执行这个语句时,会先从主存当中读取i的值,然后复制一份到高速缓存当中,然后CPU执行指令对i进行加1操作,然后将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。
这个代码在单线程中运行是没有任何问题的,但是在多线程中运行就会有问题了。在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。本文我们以多核CPU为例。
比如同时有2个线程执行这段代码,假如初始时i的值为0,那么我们希望两个线程执行完之后i的值变为2。但是事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存。
最终结果i的值是1,而不是2。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
并发编程中的三个概念
在并发编程中,我们通常会遇到以下三个问题:原子性问题,可见性问题,有序性问题。我们先看具体看一下这三个概念:
1.原子性
原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
一个很经典的例子就是银行账户转账问题:
比如从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元。
试想一下,如果这2个操作不具备原子性,会造成什么样的后果。假如从账户A减去1000元之后,操作突然中止。然后又从B取出了500元,取出500元之后,再执行 往账户B加上1000元 的操作。这样就会导致账户A虽然减去了1000元,但是账户B没有收到这个转过来的1000元。
所以这2个操作必须要具备原子性才能保证不出现一些意外的问题。
2.可见性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
举个简单的例子,看下面这段代码:
1 //线程1执行的代码 2 int i = 0; 3 i = 10; 4 5 //线程2执行的代码 6 j = i;
假若执行线程1的是CPU1,执行线程2的是CPU2。由上面的分析可知,当线程1执行 i =10这句时,会先把i的初始值加载到CPU1的高速缓存中,然后赋值为10,那么在CPU1的高速缓存当中i的值变为10了,却没有立即写入到主存当中。
此时线程2执行 j = i,它会先去主存读取i的值并加载到CPU2的缓存当中,注意此时内存当中i的值还是0,那么就会使得j的值为0,而不是10。
这就是可见性问题,线程1对变量i修改了之后,线程2没有立即看到线程1修改的值。
3.有序性
有序性:即程序执行的顺序按照代码的先后顺序执行。举个简单的例子,看下面这段代码:
int i = 0; boolean flag = false; i = 1; //语句1 flag = true; //语句2
从代码顺序上看,语句1是在语句2前面的,那么JVM在真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗?不一定,为什么呢?这里可能会发生指令重排序(Instruction Reorder)。
一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。在此我向大家推荐一个架构学习交流圈:609164807 帮助突破瓶颈 提升思维能力
比如上面的代码中,语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。
但是重排序也需要遵守一定规则:
1.重排序操作不会对存在数据依赖关系的操作进行重排序。
比如:a=1;b=a; 这个指令序列,由于第二个操作依赖于第一个操作,所以在编译时和处理器运行时这两个操作不会被重排序。
2.重排序是为了优化性能,但是不管怎么重排序,单线程下程序的执行结果不能被改变
比如:a=1;b=2;c=a+b这三个操作,第一步(a=1)和第二步(b=2)由于不存在数据依赖关系,所以可能会发生重排序,但是c=a+b这个操作是不会被重排序的,因为需要保证最终的结果一定是c=a+b=3。
volatile关键字
volatile是Java提供的一种轻量级的同步机制。同synchronized相比(synchronized通常称为重量级锁),volatile更轻量级。
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
1、共享变量的可见性
public class TestVolatile {
public static void main(String[] args) {
ThreadDemo td = new ThreadDemo();
new Thread(td).start();
while(true){
if(td.isFlag()){
System.out.println("------------------");
break;
}
}
}
}
class ThreadDemo implements Runnable {
private boolean flag = false;
@Override
public void run() {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
}
flag = true;
System.out.println("flag=" + isFlag());
}
public boolean isFlag() {
return flag;
}
}
上面这个例子,开启一个多线程去改变flag为true,main 主线程中可以输出"------------------"吗?
答案是NO!
这个结论会让人有些疑惑,可以理解。开启的线程虽然修改了flag 的值为true,但是还没来得及写入主存当中,此时main里面的 td.isFlag()还是false,但是由于 while(true) 是底层的指令来实现,速度非常之快,一直循环都没有时间去主存中更新td的值,所以这里会造成死循环!运行结果如下:

此时线程是没有停止的,一直在循环。
如何解决呢?只需将 flag 声明为volatile,即可保证在开启的线程A将其修改为true时,main主线程可以立刻得知:
第一:使用volatile关键字会强制将修改的值立即写入主存;
在此我向大家推荐一个架构学习交流圈:609164807 帮助突破瓶颈 提升思维能力
第二:使用volatile关键字的话,当开启的线程进行修改时,会导致main线程的工作内存中缓存变量flag的缓存行无效(反映到硬件层的话,就是CPU的L1缓存中对应的缓存行无效);
第三:由于线程main的工作内存中缓存变量flag的缓存行无效,所以线程main再次读取变量flag的值时会去主存读取。
volatile具备两种特性,第一就是保证共享变量对所有线程的可见性。将一个共享变量声明为volatile后,会有以下效应:
1.当写一个volatile变量时,JMM会把该线程对应的本地内存中的变量强制刷新到主内存中去;
2.这个写会操作会导致其他线程中的缓存无效。
2、禁止进行指令重排序
这里我们引用上篇文章单例里面的例子
1 class Singleton{
2 private volatile static Singleton instance = null;
3
4 private Singleton() {
5 }
6
7 public static Singleton getInstance() {
8 if(instance==null) {
9 synchronized (Singleton.class) {
10 if(instance==null)
11 instance = new Singleton();
12 }
13 }
14 return instance;
15 }
16 }
instance = new Singleton(); 这段代码可以分为三个步骤:
1、memory = allocate() 分配对象的内存空间
2、ctorInstance() 初始化对象
3、instance = memory 设置instance指向刚分配的内存
但是此时有可能发生指令重排,CPU 的执行顺序可能为:
1、memory = allocate() 分配对象的内存空间
3、instance = memory 设置instance指向刚分配的内存
2、ctorInstance() 初始化对象
在单线程的情况下,1->3->2这种顺序执行是没有问题的,但是如果是多线程的情况则有可能出现问题,线程A执行到11行代码,执行了指令1和3,此时instance已经有值了,值为第一步分配的内存空间地址,但是还没有进行对象的初始化;
此时线程B执行到了第8行代码处,此时instance已经有值了则return instance,线程B 使用instance的时候,就会出现异常。
这里可以使用 volatile 来禁止指令重排序。
从上面知道volatile关键字保证了操作的可见性和有序性,但是volatile能保证对变量的操作是原子性吗?
下面看一个例子:
package com.mmall.concurrency.example.count;
import java.util.concurrent.CountDownLatch;
/**
* @author: ChenHao
* @Description:
* @Date: Created in 15:05 2018/11/16
* @Modified by:
*/
public class CountTest {
// 请求总数
public static int clientTotal = 5000;
public static volatile int count = 0;
public static void main(String[] args) throws Exception {
//使用CountDownLatch来等待计算线程执行完
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
//开启clientTotal个线程进行累加操作
for(int i=0;i<clientTotal;i++){
new Thread(){
public void run(){
count++;//自加操作
countDownLatch.countDown();
}
}.start();
}
//等待计算线程执行完
countDownLatch.await();
System.out.println(count);
}
}
执行结果:
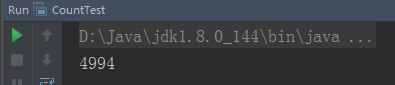
针对这个示例,一些同学可能会觉得疑惑,如果用volatile修饰的共享变量可以保证可见性,那么结果不应该是5000么?
问题就出在count++这个操作上,因为count++不是个原子性的操作,而是个复合操作。我们可以简单讲这个操作理解为由这三步组成:
1.读取count
2.count 加 1
3.将count 写到主存
所以,在多线程环境下,有可能线程A将count读取到本地内存中,此时其他线程可能已经将count增大了很多,线程A依然对过期的本地缓存count进行自加,重新写到主存中,最终导致了count的结果不合预期,而是小于5000。
那么如何来解决这个问题呢?下面我们来看看
Atomic包
在java 1.5的java.util.concurrent.atomic包下提供了一些原子操作类,即对基本数据类型的 自增(加1操作),自减(减1操作)、以及加法操作(加一个数),减法操作(减一个数)进行了封装,保证这些操作是原子性操作。atomic是利用CAS来实现原子性操作的(Compare And Swap)
package com.mmall.concurrency.example.count;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author: ChenHao
* @Description:
* @Date: Created in 15:05 2018/11/16
* @Modified by:
*/
public class CountTest {
// 请求总数
public static int clientTotal = 5000;
public static AtomicInteger count = new AtomicInteger(0);
public static void main(String[] args) throws Exception {
//使用CountDownLatch来等待计算线程执行完
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
在此我向大家推荐一个架构学习交流圈:609164807 帮助突破瓶颈 提升思维能力
//开启clientTotal个线程进行累加操作
for(int i=0;i<clientTotal;i++){
new Thread(){
public void run(){
count.incrementAndGet();//先加1,再get到值
countDownLatch.countDown();
}
}.start();
}
//等待计算线程执行完
countDownLatch.await();
System.out.println(count);
}
}
执行结果:
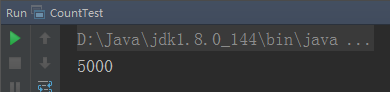
下面我们来看看原子类操作的基本原理
1 public final int incrementAndGet() {
2 return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
3 }
4
5 public final int getAndAddInt(Object var1, long var2, int var4) {
6 int var5;
7 do {
8 var5 = this.getIntVolatile(var1, var2);
9 } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
10
11 return var5;
12 }
13
14 /***
15 * 获取obj对象中offset偏移地址对应的整型field的值。
16 * @param obj 包含需要去读取的field的对象
17 * @param obj中整型field的偏移量
18 */
19 public native int getIntVolatile(Object obj, long offset);
20
21 /**
22 * 比较obj的offset处内存位置中的值和期望的值,如果相同则更新。此更新是不可中断的。
23 *
24 * @param obj 需要更新的对象
25 * @param offset obj中整型field的偏移量
26 * @param expect 希望field中存在的值
27 * @param update 如果期望值expect与field的当前值相同,设置filed的值为这个新值
28 * @return 如果field的值被更改返回true
29 */
30 public native boolean compareAndSwapInt(Object obj, long offset, int expect, int update);
首先介绍一下什么是Compare And Swap(CAS)?简单的说就是比较并交换。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该位置的值。CAS 有效地说明了“我认为位置 V 应该包含值 A;如果包含该值,则将 B 放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可。” Java并发包(java.util.concurrent)中大量使用了CAS操作,涉及到并发的地方都调用了sun.misc.Unsafe类方法进行CAS操作。
我们来分析下incrementAndGet的逻辑:
1.先获取当前的value值
2.调用compareAndSet方法来来进行原子更新操作,这个方法的语义是:
先检查当前value是否等于obj中整型field的偏移量处的值,如果相等,则意味着obj中整型field的偏移量处的值 没被其他线程修改过,更新并返回true。如果不相等,compareAndSet则会返回false,然后循环继续尝试更新。
第一次count 为0时线程A调用incrementAndGet时,传参为 var1=AtomicInteger(0),var2为var1 里面 0 的偏移量,比如为8090,var4为需要加的数值1,var5为线程工作内存值,在此我向大家推荐一个架构学习交流圈:609164807 帮助突破瓶颈 提升思维能力do里面会先执行一次,通过getIntVolatile 获取obj对象中offset偏移地址对应的整型field的值此时var5=0;while 里面compareAndSwapInt 比较obj的8090处内存位置中的值和期望的值var5,如果相同则更新obj的值为(var5+var4=1),此时更新成功,返回true,则 while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));结束循环,return var5。
当count 为0时,线程B 和线程A 同时读取到 count ,进入到第 8 行代码处,线程B 也是取到的var5=0,当线程B 执行到compareAndSwapInt时,线程A已经执行完compareAndSwapInt,已经将内存地址为8090处的值修改为1,此时线程B 执行compareAndSwapInt返回false,则继续循环执行do里面的语句,再次取内存地址偏移量为8090处的值为1,再去执行compareAndSwapInt,更新obj的值为(var5+var4=2),返回为true,结束循环,return var5。
CAS的ABA问题
当然CAS也并不完美,它存在"ABA"问题,假若一个变量初次读取是A,在compare阶段依然是A,但其实可能在此过程中,它先被改为B,再被改回A,而CAS是无法意识到这个问题的。CAS只关注了比较前后的值是否改变,而无法清楚在此过程中变量的变更明细,这就是所谓的ABA漏洞。