思维导图
结构体基础
-
结构体类型的定义与声明

-
结构体类型变量定义和初始化

- 定义变量
struct stu s1;- 结构体变量初始化
struct stu s5 = { “小明”,10,15,5,98};- 使用,变量用 “.” 引用成员,指针用 “->” 引用成员
printf (“num = %d,name = %s\n”, s5.num, s5.name);
-
结构体类型变量赋值与使用

-
结构体数组

-
结构体嵌套

-
结构体指针
• 结构体和结构体变量是不同的概念
• 结构体是一种数据类型,和我们的int float等是一样的,编译器不会为它分配内存
• 结构体变量才是实实在在的数据,才需要内存来存储
struct student stu = {“xiaoming”, 18, 50}; // 结构体变量
struct student *pstu = &stu; // 结构体指针,指向一个结构体变量stu
struct student pstu = student; //错误的写法
获取结构体成员:
. 号的优先级高于*,(*pstu)两边的括号是不能少的,如果去掉括号,
就变成 *pstu.name == *(pstu.name)
printf (“name = %s\n”, (*pstu).name);
->是一个新的运算符,一般叫做"箭头",通过它结构体指针能直接取得结构体的成员
printf (“name = %s\n”, pstu->name);
printf (“age = %d\n”, pstu->age);
printf (“score = %.2f\n”, pstu->score);
结构体变量名代表的是整个集合本身,作为函数参数时传递的整个集合,也就是所有成员,而不是像数组一样被编译器转换成一个指针。如果结构体成员较多,尤其是成员为数组时,传送的时间和空间开销会很大,影响程序的运行效率。所以最好的办法就是使用结构体指针,这时由实参传向形参的只是一个地址,非常快速

结构体内存对齐模式
为什么要进行内存对齐?
内存对齐是操作系统为了快速访问内存而采取的一种策略,简单来说,就是为了放置变量的二次访问。操作系统在访问内存 时,每次读取一定的长度(这个长度就是操作系统的默认对齐系数,或者是默认对齐系数的整数倍)。如果没有内存对齐时,为了读取一个变量是,会产生总线的二 次访问。
例如假设没有内存对齐(默认对齐系数为8),结构体xx的变量位置会出现如下情况:
struct xx{
char b; //0xffbff5e8
int a; //0xffbff5e9
int c; //0xffbff5ed
char d; //0xffbff5f1
};
操作系统先读取0xffbff5e8-0xffbff5ef的内存,然后在读取0xffbff5f0-0xffbff5f8的内存,为了获得值c,就需要将两组内存合并,进行整合,这样严重降低了内存的访问效率。(这就涉及到了老生常谈的问题,空间和效率哪个更重要?)。
这样大家就能理解为什么结构体的第一个变量,不管类型如何,都是能被8整除的吧(因为访问内存是从8的整数倍开始的,为了增加读取的效率)
内存对齐原则
1、 结构体成员的首地址要能被该成员的类型长度所整除
2、 结构体为成员分配空间原则
- 每次分配的时候按当前最大类型分配
- 如果当前空间够用,则不再分配空间
- 如果当前类型大于系统默认对齐系数的时候,按系统系数标准进 行分配空间,否则按最大类型分配空间
系统默认对齐系数
每 个操作系统都有自己的默认内存对齐系数,如果是新版本的操作系统,默认对齐系数一般都是8,因为操作系统定义的最大类型存储单元就是8个字节,例如 long long,不存在超过8个字节的类型(例如int是4,char是1,long在32位编译时是4,64位编译时是 8)。当操作系统的默认对齐系数与内存对齐的理论产生冲突时,以操作系统的对齐系数为基准
举例说明:
#include<stdio.h>
struct test
{
char a;
int b;
long c;
long long d;
char e;
short f;
};
int main()
{
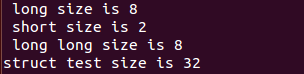
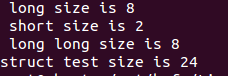
printf(" long size is %lu\n",sizeof(long));
printf(" short size is %lu\n",sizeof(short));
printf(" long size is %lu\n",sizeof(long));
printf("struct test size is %lu\n",sizeof(struct test));
return 0;
}Ubuntu14.04 64bits 测试:
分析:
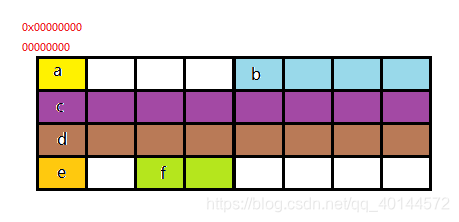
struct test 成员的最大类型长度是8字节
Ubuntu14.04 64bits默认内存对齐系数也是8字节
所以按8字节进行分配空间
上面的成员排列会造成内存空间浪费

应该如下排列,资源最大化利用。
struct test
{
char a;
char e;
short f;
int b;
long c;
long long d;
};

结构体位域
- 概念:
有些数据在存储时并不需要占用一个完整的字节,只需要占用一个或几个二进制位即可。例如开关只有通电和断电两种状态,用 0 和 1 表示足以,也就是用一个二进位。正是基于这种考虑,C语言又提供了一种叫做位域的数据结构。
在结构体定义时,我们可以指定某个成员变量所占用的二进制位数(Bit),这就是位域:
struct bs
{
unsigned m;
unsigned n: 4;
unsigned char ch: 6;
};
- 存储规则:
• 相邻成员的类型相同
当相邻成员的类型相同时,如果它们的位宽之和小于类型的 sizeof 大小,那么后面的成员紧邻前一个成员存储,直到不能容纳为止;如果它们的位宽之和大于类型的 sizeof 大小,那么后面的成员将从新的存储单元开始,其偏移量为类型大小的整数倍。
struct bs{
unsigned m: 6;
unsigned n: 12;
unsigned p: 4;
};
printf("%d\n", sizeof(struct bs));
• 相邻成员的类型不同
当相邻成员的类型不同时,不同的编译器有不同的实现方案,GCC 会压缩存储,而 VC/VS 不会
struct bs
{
unsigned m: 12;
unsigned char ch: 4;
unsigned p: 4;
};
printf("%d\n", sizeof(struct bs));
• 成员之间插着非位域成员
如果成员之间穿插着非位域成员,会视情况进行压缩。例如对于下面的 bs:
struct bs
{
unsigned m: 12;
unsigned char ch;
unsigned p: 4;
};
printf("%d\n", sizeof(struct bs));
• 位域成员可以没有名字,只给出数据类型和位宽
struct bs{
int m: 12;
int : 20; //该位域成员不能使用
int n: 4;
};
无名位域一般用来作填充或者调整成员位置。因为没有名称,无名位域不能使用。
上面的例子中,如果没有位宽为 20 的无名成员,m、n 将会挨着存储,sizeof(struct bs) 的结果为 4;有了这 20 位作为填充,m、n 将分开存储,sizeof(struct bs) 的结果为 8。
共用体
共用体:
所用成员共用一段内存,共用体大小是成员中占据最大的成员的大小
定义、初始化和使用:
union 共用体名
{
成员列表
};
结构体和共用体的区别在于:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
共用体的所有成员起始地址的是一样的。
#include<stdio.h>
union Test
{
int a;
char c;
};
int main()
{
printf ("sizeof Test = %lu\n", sizeof(union Test));
union Test t;
t.a = 10;
t.c = 'A';
printf ("%d\n", t.a);
return 0;
}大小端模式:
如果我们将0x1234abcd 写入到以0x0000 开始的内存中,则Little endian和Big endian 模式的存放结果如下:
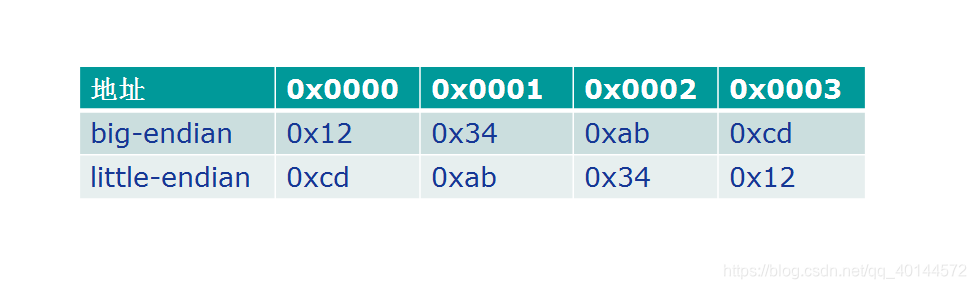
大端模式:字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中。
小端模式:字数据的高字节存储在高地址中,而字数据的低字节则存放在低地址中。
测试大小端
// 小端返回1 大端返回0
int func()
{
union
{
unsigned int a;
unsigned char c;
}t;
t.a = 0x12345678
return (t.c == 0x78);
}
枚举
enum typeName{ valueName1, valueName2, valueName3, ...... };
enum week{ Mon, Tues, Wed, Thurs, Fri, Sat, Sun };
-
枚举列表中的 Mon、Tues、Wed 这些标识符的作用范围是全局的,不能再定义与它们名字相同的变量。
-
Mon、Tues、Wed 等都是常量,不能对它们赋值,只能将它们的值赋给其他的变量
-
Mon、Tues、Wed 等都是常量, 初始化只能在定义的时候进行,如果没有初始化,默认从0开始依次递增1,如果只初始化部分,后面的也是一次递增1
#include<stdio.h>
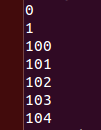
enum week{Mon, Tues, Wed=100, Thurs, Fri, Sat, Sun};
int main()
{
printf ("%d\n", Mon);
printf ("%d\n", Tues);
printf ("%d\n", Wed);
printf ("%d\n", Thurs);
printf ("%d\n", Fri);
printf ("%d\n", Sat);
printf ("%d\n", Sun);
return 0;
}结果: