本篇文章主要围绕字符编码展开,为了能够更好地讲述这一主题,我将从字节流操作中文数据开始。
字节流操作中文数据
假设编写有如下程序,代码贴出如下:
package cn.liayun.readcn;
import java.io.FileOutputStream;
import java.io.IOException;
public class ReadCNDemo {
public static void main(String[] args) throws IOException {
writeCNText();
}
public static void writeCNText() throws IOException {
FileOutputStream fos = new FileOutputStream("tempfile\\cn.txt");
fos.write("你好".getBytes());//按照默认编码表GBK编码
fos.close();
}
}
此时运行以上程序,可以发现在cn.txt文本文件中有”你好“两字,并且文件大小仅有4字节。其原因是String类的getBytes()方法是使用平台的默认字符集(即GBK码表,而在GBK码表里面,一个中文占2个字节)将”你好“字符串编码为了一个字节数组。
上面程序将”你好“两字写入cn.txt文本文件之后,我们需要使用字节流将其读取出来,由于该文本文件大小仅有4字节,可使用字节输出流的read()方法一个字节一个字节地读取出来,代码如下:
package cn.liayun.readcn;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class ReadCNDemo {
public static void main(String[] args) throws IOException {
readCNText();
}
public static void readCNText() throws IOException {
FileInputStream fis = new FileInputStream("tempfile\\cn.txt");
int by = fis.read();
System.out.println(by);
int by2 = fis.read();
System.out.println(by2);
int by3 = fis.read();
System.out.println(by3);
int by4 = fis.read();
System.out.println(by4);
int by5 = fis.read();
System.out.println(by5);
fis.close();
}
}
运行以上程序,可发现Eclipse控制台打印如下,截图如下。
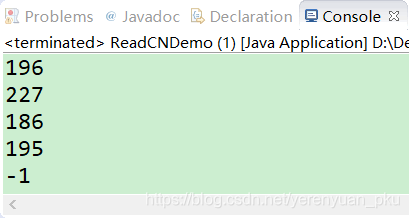
上面输出的东西是一堆数字,我们可能看不懂,而我们想要看到的是”你好“两字,那么问题归纳为:使用字节输出流读取中文时,是按照字节形式,但是一个中文在GBK码表中是2个字节,而且字节输出流的read()方法一次读取一个字节,如何可以获取到一个中文呢?解决方案就是别读一个就操作,多读一些存起来,再操作,存到字节数组中,将字节数组转成字符串就哦了。
package cn.liayun.readcn;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class ReadCNDemo {
public static void main(String[] args) throws IOException {
readCNText();
}
public static void readCNText() throws IOException {
FileInputStream fis = new FileInputStream("tempfile\\cn.txt");
//读取中文,按照字节的形式,但是一个中文,GBK码表中是两个字节
//而字节流的read方法一次读取一个字节,如何可以获取到一个中文呢?
//别读一个就操作,多读一些存起来,再操作,存到字节数组中,将字节数组转成字符串就哦了
byte[] buf = new byte[1024];
int len = fis.read(buf);
String s = new String(buf, 0, len);//将字节数组转换成字符串,而且是按照默认的编码表(GBK)进行解码。
System.out.println(s);
fis.close();
}
}
须知String类的String(byte[] bytes, int offset, int length)构造方法是通过使用平台的默认字符集(即GBK码表)解码指定的byte子数组,构造一个新的String。接下来,就要引出编码表这一概念了。
编码表
编码表的由来
计算机只能识别二进制数据,早期由来是电信号。为了方便应用计算机,让它可以识别各个国家的文字,就将各个国家的文字用数字来表示,并一一对应,形成一张表,这就是编码表。
常见的编码表
| 编码表名称 | 说明 |
|---|---|
| ASCII | 美国标准信息交换码,用一个字节的7位可以表示 |
| ISO8859-1 | 拉丁码表或欧洲码表,用一个字节的8位表示 |
| GB2312 | 中国的中文编码表 |
| GBK | 中国的中文编码表升级,融合了更多的中文文字符号 |
| GB18030 | GBK的取代版本 |
| BIG-5 | 通行于台湾、香港地区的一个繁体字编码方案,俗称”大五码“ |
| Unicode | 国际标准码,融合了多种文字,所有文字都用两个字节来表示,Java语言使用的就是Unicode |
| UTF-8 | 最多用三个字节来表示一个字符。UTF-8不同,它定义了一种”区间规则“,这种规则可以和ASCII编码保持最大程度的兼容:它将Unicode编码为00000000-0000007F的字符,用单个字节来表示;将Unicode编码为00000080-000007FF的字符,用两个字节来表示;将Unicode编码为00000800-0000FFFF的字符,用三个字节来表示 |
编码与解码
- 编码:把看得懂的变成看不懂的。即将字符串变成字节数组(String→byte[]),代表方法为
str.getBytes(charsetName); - 解码:把看不懂的变成看得懂的。即将字节数组变成字符串(byte[]→String),代表方法为
new String(byte[], charsetName)。
关于编码与解码,有一个结论,即由UTF-8编码,自然要通过UTF-8来解码;同理,由GBK来编码,自然也要通过GBK来解码,否则会出现乱码。下面我会通过若干个案例来详述编码与解码。
由GBK来编码,通过GBK来解码
首先运行以下程序,给出程序代码如下:
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("GBK");// 默认编码方式就是GBK
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "GBK");// 通过GBK来解码
System.out.println("s1 = " + s1);
}
}
运行以上程序,可发现Eclipse控制台打印如下,截图如下。

发现输出结果并无乱码。
由GBK来编码,通过UTF-8来解码
然后再运行以下程序,观察运行后的结果,给出程序代码如下:
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("GBK");// 默认编码方式就是GBK
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "UTF-8");// 通过UFT-8来解码
System.out.println("s1 = " + s1);
}
}
运行以上程序,可发现Eclipse控制台打印如下,截图如下。
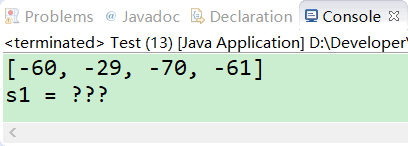
发现输出了乱码——???。
由UTF-8来编码,通过UTF-8来解码
那怎么不是像上面那样输出三个问号呢?method()方法的代码应修改为如下,即可解决乱码问题。
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("UTF-8");// 默认编码方式就是UTF-8
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "UTF-8");// 通过UFT-8来解码
System.out.println("s1 = " + s1);
}
}
再次运行以上程序,可发现Eclipse控制台打印如下,截图如下。

由UTF-8来编码,通过GBK来解码
接着再运行以下程序,观察运行后的结果,给出程序代码如下:
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("UTF-8");// 默认编码方式就是UTF-8
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "GBK");// 通过GBK来解码
System.out.println("s1 = " + s1);
}
}
运行以上程序,可发现Eclipse控制台打印如下,截图如下。

发现输出结果出现了乱码,至于怎么解决我就不说了。
由GBK来编码,再通过ISO8859-1来解码,乱码问题如何解决?
这里有一种特殊的情况,先对字符串“你好”进行GBK编码,再通过ISO8859-1解码,程序代码如下:
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("GBK");// 默认编码方式就是GBK
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "ISO8859-1");// 通过ISO8859-1来解码
System.out.println("s1 = " + s1);
}
}
运行以上程序,输出结果肯定会出现乱码——???。

如果要输出正确的字符串内容,可对s1进行ISO8859-1编码,然后再通过GBK解码,所以method()方法的代码应修改为如下,即可解决乱码问题。
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("GBK");// 默认编码方式就是GBK
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "ISO8859-1");// 通过ISO8859-1来解码
System.out.println("s1 = " + s1);
// 对s1进行ISO8859-1编码
byte[] b2 = s1.getBytes("ISO8859-1");
System.out.println(Arrays.toString(b2));
String s2 = new String(b2, "GBK"); // 通过GBK来解码
System.out.println("s2 = " + s2);
}
}
不理解以上代码没关系,下面我会图解,如下:

由GBK来编码,再通过UTF-8来解码,乱码问题如何解决?
现在来思考这样一个问题:先对字符串“你好”进行GBK编码,再通过UTF-8解码,编写代码如下:
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("GBK");// 默认编码方式就是GBK
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "UTF-8");// 通过UTF-8来解码
System.out.println("s1 = " + s1);
}
}
运行以上程序,此时肯定会输出乱码——???。如果想要输出正确的字符串内容,可不可以对s1进行一次UTF-8编码,然后再通过GBK解码呢?即method()方法的代码应修改为如下:
package cn.liayun.readcn;
import java.io.IOException;
import java.util.Arrays;
public class Test {
public static void main(String[] args) throws IOException {
method();
}
public static void method() throws IOException {
String s = "你好";
byte[] b1 = s.getBytes("GBK");// 默认编码方式就是GBK
System.out.println(Arrays.toString(b1));
String s1 = new String(b1, "UTF-8");// 通过UTF-8来解码
System.out.println("s1 = " + s1);
// 对s1进行UTF-8编码
byte[] b2 = s1.getBytes("UTF-8");
System.out.println(Arrays.toString(b2));
String s2 = new String(b2, "GBK"); // 通过GBK来解码
System.out.println("s2 = " + s2);
}
}
答案是不可以。如若不信,读者不妨试着调用以上方法,可以看到Eclipse控制台打印如下,给出截图。

发现依然输出乱码——锟斤拷锟?,其原因又是什么呢?不妨画张图来解释一下。
