1. Kafka的Producer
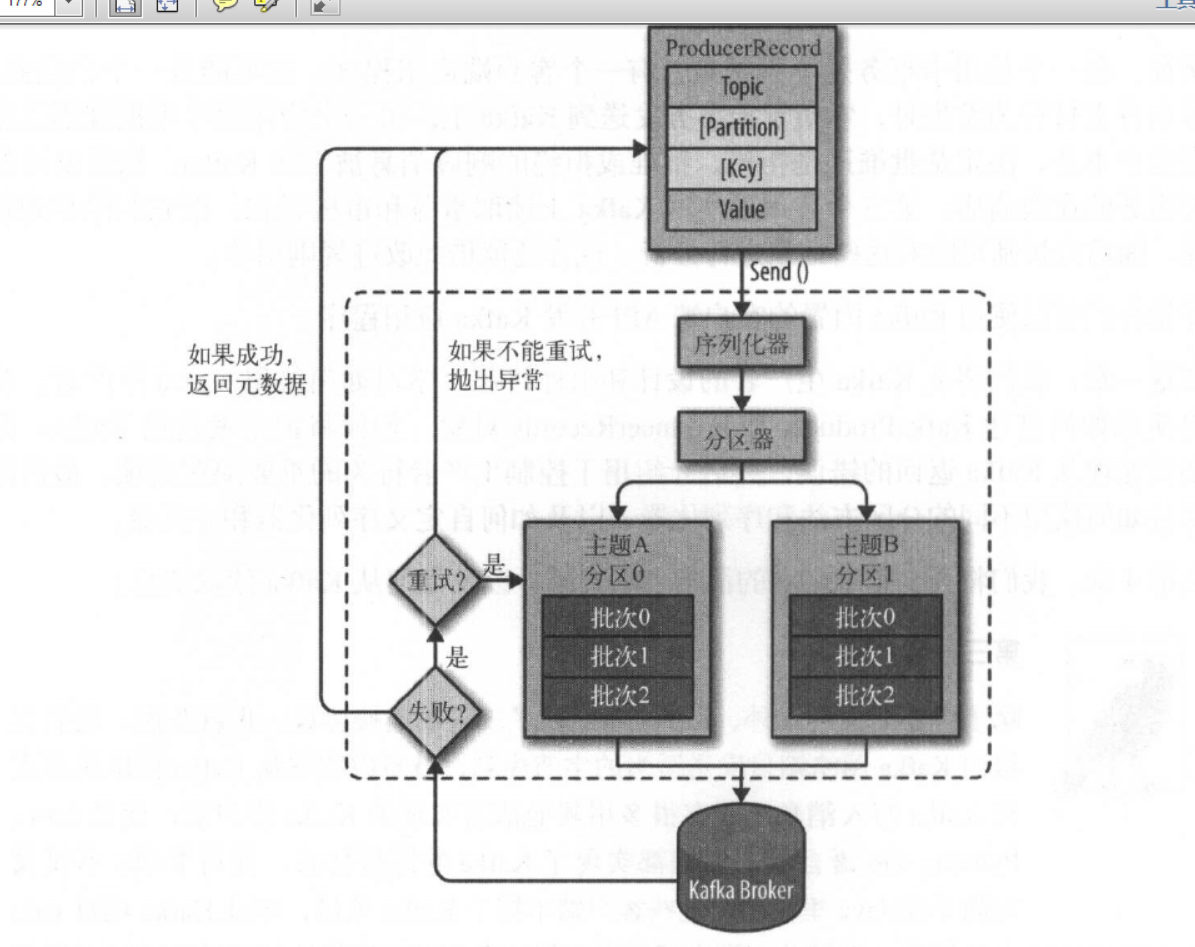
不论将kafka作为什么样的用途,都少不了的向Broker发送数据或接受数据,Producer就是用于向Kafka发送数据。如下:
2. 添加依赖
pom.xml文件如下:
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.12</artifactId> <version>2.1.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.1.0</version> </dependency>
3. 发送消息
3.1 创建生产者
创建生产者的时候,我们需要为生产者设置一些属性,其中有三个必选属性如下:
1. bootstrap.servers: 该属性指定broker 的地址清单,地址的格式为host:po 忱。清单里不需要包含所有的broker 地址,生产者会给定的broker 里查找到其他broker 的信息。不过建议至少要提供两个broker 的信息, 一且其中一个若机,生产者仍然能够连接到集群上。
2. key.serializer: broker 希望接收到的消息的键和值都是字节数组。生产者接口允许使用参数化类型,因此可以把Java 对象作为键和值发送给broker 。这样的代码具有良好的可读性,不过生产者需要知道如何把这些Java 对象转换成字节数组。key. serializer必须被设置为一个实现了org.apache.kafka.common.serialization.StringSerializer接口的类,生产者会使用这个类把键对象序列化成字节数组。Kafka 客户端默认提供了ByteArraySerializer(这个只做很少的事情)、StringSerializer和IntegeSerializer,因此,如果你只使用常见的几种Java 对象类型,那么就没必要实现自己的序列化器。要注意, key.serializer是必须设置的,就算你打算只发送值内容。
3. value.serializer: 与key.serializer一样,value.serializer指定的类会将值序列化。如果键和值都是字符串,可以使用与key.serializer一样的序列化器。如果键是整数类型而值是字符串,那么需要使用不同的序列化器。
设置属性代码如下:
Properties kafkaPropertie = new Properties(); //配置broker地址,配置多个容错 kafkaPropertie.put("bootstrap.servers", "node1:9092,node1:9093,node1:9094"); //配置key-value允许使用参数化类型 kafkaPropertie.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); kafkaPropertie.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
3.2 发送消息的三种方式
1. 并发并忘记,这是普通的消息发送方式,我们把消息发送给服务器,但井不关心它是否正常到达。大多数情况下,消息会正常到达,因为Kafka 是高可用的,而且生产者会自动尝试重发。不过,使用这种方式有时候也会丢失一些消息。
实现如下:
package com.wangx.kafka.client; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; import java.util.concurrent.ExecutionException; public class KafkaProducerDemo { public static void main(String[] args) throws ExecutionException, InterruptedException { Properties kafkaPropertie = new Properties(); //配置broker地址,配置多个容错 kafkaPropertie.put("bootstrap.servers", "node1:9092,node1:9093,node1:9094"); //配置key-value允许使用参数化类型 kafkaPropertie.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); kafkaPropertie.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer kafkaProducer = new KafkaProducer(kafkaPropertie); ProducerRecord<String, String> record = new ProducerRecord<String, String>("testTopic","key1","hello world"); kafkaProducer.send(record); } }
此时在Kafka中打开内置的消费者消费消息,结果如下,命令如下:
kafka-console-consumer.sh --bootstrap-server 47.105.145.123:9092 --topic testTopic --from-beginning
然后,启动生产者发送消息,结果如下:

这里启动了四次消费者,所以有四条消息被消费。
3.3 同步发送消息
我们使用send () 方怯发送消息, 它会返回Future对象,调用get () 方法进行等待,就可以知道悄息是否发送成功。
实现方式如下:
package com.wangx.kafka.client; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Properties; import java.util.concurrent.ExecutionException; public class KafkaProducerDemo { public static void main(String[] args) throws ExecutionException, InterruptedException { Properties kafkaPropertie = new Properties(); //配置broker地址,配置多个容错 kafkaPropertie.put("bootstrap.servers", "node1:9092,node1:9093,node1:9094"); //配置key-value允许使用参数化类型 kafkaPropertie.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); kafkaPropertie.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer kafkaProducer = new KafkaProducer(kafkaPropertie); //创建消息对象,第一个为参数topic,第二个参数为key,第三个参数为value ProducerRecord<String, String> record = new ProducerRecord<String, String>("testTopic","key1","hello world"); //同步发送方式,get方法返回结果 RecordMetadata metadata = (RecordMetadata) kafkaProducer.send(record).get(); System.out.println("broker返回消息发送信息" + metadata); } }
客户端消费者仍能收到消息,且生产者也能收到返回结果,返回结果如下:

3.4 异步发送消息
假设消息在应用程序和Kafka 集群之间一个来回需要lOm s 。如果在发送完每个消息后都等待回应,那么发送100 个消息需要l秒。但如果只发送消息而不等待响应,那么发送100 个消息所需要的时间会少很多。大多数时候,我们并不需要等待响应一一尽管Kafka会把目标主题、分区信息和悄息的偏移量发送回来,但对于发送端的应用程序来说不是必需的。不过在遇到消息发送失败时,我们需要抛出异常、记录错误日志,或者把消息写入“错误消息”文件以便日后分析。
实现如下:
package com.wangx.kafka.client; import org.apache.kafka.clients.producer.Callback; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Properties; import java.util.concurrent.ExecutionException; public class KafkaProducerDemo { public static void main(String[] args) { Properties kafkaPropertie = new Properties(); //配置broker地址,配置多个容错 kafkaPropertie.put("bootstrap.servers", "node1:9092,node1:9093,node1:9094"); //配置key-value允许使用参数化类型 kafkaPropertie.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); kafkaPropertie.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer kafkaProducer = new KafkaProducer(kafkaPropertie); //创建消息对象,第一个为参数topic,第二个参数为key,第三个参数为value final ProducerRecord<String, String> record = new ProducerRecord<String, String>("testTopic","key1","hello world"); //异步发送消息。异常时打印异常信息或发送结果 kafkaProducer.send(record, new Callback() { public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e != null) { System.out.println(e.getMessage()); } else { System.out.println("接收到返回结果:" + recordMetadata); } } }); //异步发送消息时必须要flush,否则发送不成功,不会执行回调函数 kafkaProducer.flush(); } }
监听到的返回信息如下:

3.5 生产者的配置
生产者还有很多可以配置的参数,如下:
1. acks:指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。这个参数对消息丢失的可能性有重要影响。该参数有如下选项。
如果acks=0 , 生产者在成功写入消息之前不会等待任何来自服务器的响应。也就是说,如果当中出现了问题, 导致服务器没有收到消息,那么生产者就无从得知,消息也就丢失了。不过,因为生产者不需要等待服务器的响应,所以它可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量。
如果acks=1 ,只要集群的首领节点收到消息,生产者就会收到一个来自服务器的成功响应。如果消息无法到达首领节点(比如领导节点奔溃,新的首领还没有被选举出来),生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。不过,如果一个没有收到消息的节点成为新首领,消息还是会丢失。这个时候的吞吐量取决于使用的是同步发送还是异步发送。如果让发送客户端等待服务器的响应(通过调用Future对象的ge t ()方法),显然会增加延迟(在网络上传输一个来回的延迟)。如果客户端使用回调,延迟问题就可以得到缓解,不过吞吐量还是会受发送中消息数量的限制(比如,生产者在收到服务器响应之前可以发送多少个消息)。
如果acks=all ,只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。这种模式是最安全的,它可以保证不止一个服务器收到消息,就算有服务器发生崩溃,整个集群仍然可以运行。不过,它的延迟比acks=1时更高,因为我们要等待不只一个服务器节点接收消息。
2. buffer.memory: 用来设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果应用程序发送消息的速度超过发送到服务器的速度,会导致生产者空间不足。这个时候,send ()方法调用要么被阻塞,要么抛出异常,取决于如何设置block.on.buffer 参数(在0. 9.0.0 版本里被替换成了l'la x .block.l'ls ,表示在抛出异常之前可以阻塞一段时间)。
3. compression.type: 默认情况下,消息发送时不会被压缩。该参数可以设置为snappy 、gzip 或lz4 ,它指定了消息被发到broker 之前使用哪一种压缩算法进行压缩。ssnappy压缩算法由Google发明,它占用较少的CPU ,却能提供较好的性能和相当可观的 压缩比,如果比较关注性能和网络带宽,可以使用这种算法。gzip压缩算法一般会占用较多的CPU ,但会提供更高的压缩比,所以如果网络带宽比较有限,可以使用这种算法。使用压缩可以降低网络传输开销和存储开销,而这往往是向Kafka 发送消息的瓶颈所在。
4. retries: 生产者从服务器收到的错误有可能是临时性的错误,在这种情况下, retries 参数的值决定了生产者可以重发消息次数,如果达到这个次数,生产者会放弃重试并返回错误
5. batch.size: 当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里,该参数指定了一个批次可以使用的内存大小,按照字节数计算。
6. linger.ms: 该参数指定了生产者在发送批次之前等待更多消息加入批次的时间。
7. client.id: 该参数可以是任意的字符串,服务器会用它来识别消息的来源,还可以用在日志和配额指标里
8. max.in.flight.requests.per.connection: 该参数指定了生产者在收到服务器晌应之前可以发送多少个消息
9. timeout.ms 、request.timeout.ms 和metadata.fetch.timeout.ms:request.timeout.ms 指定了生产者在发送数据时等待服务器返回响应的时间,metadata.fetch.timeout.ms指定了生产者在获取元数据(比如目标分区的首领是谁)时等待服务器返回响应的时间。如果等待响应超时,那么生产者要么重试发送数据,要么返回一个错误(抛出异常或执行回调)。timeout.ms指定了broker 等待同步副本返回消息确认的时间,与asks 的配置相匹配一一如果在指定时间内没有收到同步副本的确认,那么broker 就会返回一个错误。
10. max.block.ms:该参数指定了在调用send () 方法或使用partitionsFor()方法获取元数据时生产者的阻塞时间。
11. max.request.size:该参数用于控制生产者发送的请求大小,可以指能发送的单个消息的最大值,也可以指单个请求里面所有消息总的大小。
12. receive.buffer.bytes 和send.buffer.bytes: 这两个参数分别指定了TCP socket 接收和发送数据包的缓冲区大小,如果它们被设为-1,就使用操作系统的默认值。