之前看到一个问题:java的参数传递到底是值传递还是引用传递呢?
首先,我们来看看java的堆(heap)和栈(stack)吧!
堆是jvm虚拟机所管理的内存中最大的一块,主要用来存储new的对象实例或数组(当然会有一些别的东西,比如类变量)。java堆是被所有线程所共享的一块内存,在java虚拟机的规范中,java堆可以处于物理上不连续的内存空间,只要逻辑上是连续的就好。
栈是线程私有的,生命周期与线程捆绑在一起。每个java方法在执行的时候都会创建一个栈帧用来存储局部变量,操作数栈,动态链接,方法除垢等信息。每个方法调用知道完成执行后的过程,就对应着一个栈帧在虚拟机栈中的入栈到出栈的过程。局部变量所需的内存空间在编译期间就能完成分配的,就是说,在进入一个方法时,这个方法在帧中分配的空间是完全确定的,运行不会改变局部变量的大小。
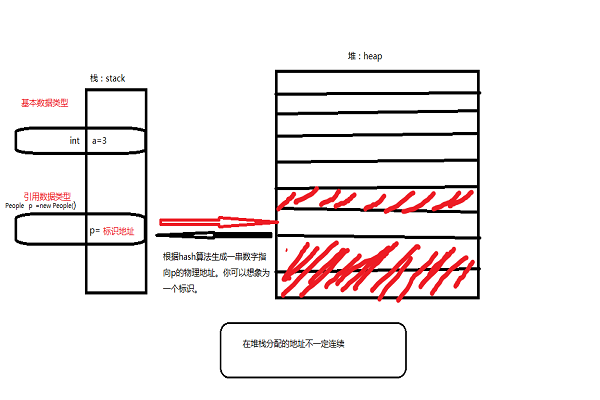
接下来看看变量的存储。首先我们看一个图(不会画图,将就着看......)
分析之前加个tips:
在Java中,变量的作用域分为四个级别:类级、对象实例级、方法级、块级。
类级变量又称全局级变量或静态变量,需要使用static关键字修饰。类级变量在类定义后就已经存在,占用内存空间,可以通过类名来访问,不需要实例化。
对象实例级变量就是成员变量,实例化后才会分配内存空间,才能访问。
方法级变量就是在方法内部定义的变量,就是局部变量。
说明:
方法内部除了能访问方法级的变量,还可以访问类级和实例级的变量。
块内部能够访问类级、实例级变量,如果块被包含在方法内部,它还可以访问方法级的变量。
方法级和块级的变量必须被显示地初始化,否则不能访问。
栈中存储基本类型和引用地址。当你定义一个变量,例如int a=3;则栈中就分配了一个a=3的帧。当你定义的变量的超过作用域时,假设为new一个People对象,这时p升级为实例级变量。这个实例对象超过了会在堆中分配内存,这个分配的物理地址可能不连续。同时通过hash算法生成一串长数字作为引用地址,返回给栈中。于是栈中就有了p=(引用地址),当你找这个对象其实是通过引用地址找堆中的实例对象。也就是当你使用==比较两个引用类型时,是比较的地址。你没重写toString()方法,你输出的对象或者数组是个地址。
在堆中的分配的内存,将由jvm的垃圾回收器(GC)回收。
再来聊聊java中变量在内存中的分配:
类变量(static修饰的变量):在程序加载时系统就为它在堆中开辟了内存,堆中的内存地址存放于栈以便于高速访问。静态变量的生命周期--一直持续到整个"系统"关闭
实例变量:当你使用java关键字new的时候,系统在堆中开辟并不一定是连续的空间分配给变量(比如说类实例),然后根据零散的堆内存地址,通过哈希算法换算为一长串数字以表征这个变量在堆中的"物理位置"。 实例变量的生命周期--当实例变量的引用丢失后,将被GC(垃圾回收器)列入可回收“名单”中,但并不是马上就释放堆中内存
局部变量:局部变量,由声明在某方法,或某代码段里(比如for循环),执行到它的时候在栈中开辟内存,当局部变量一但脱离作用域,内存立即释放。
总结一下:栈的存取速度快,稍逊于寄存器, 比堆快;堆内存,负责运行时(runtime, 执行生成的class文件时)数据,由JVM的自动管理。缺点是,存取速度较慢。 栈存储基本类型、局部变量以及引用地址;堆存储实例对象、类变量、数组。栈中的引用地址是堆中对应变量的标识。最后,我的认知可能会有偏差,希望读者能提出改进或者支出错误。
回到一开始的问题:java的参数传递到底是值传递还是引用传递呢?当传入的是基本数据类型时,传入的是变量的值;当传入的是引用类型时,传入的是引用地址。我们应该明确一点:程序运行过程中永远是在栈内运行,所以java的参数传递只能传基本数据类型和对象的引用,不会传对象本身。