并发性Concurrency
1.1 什么是并发
Go是并发语言,而不是并行语言。在讨论如何在Go中进行并发处理之前,我们首先必须了解什么是并发,以及它与并行性有什么不同。(Go is a concurrent language and not a parallel one. )
并发性Concurrency是同时处理许多事情的能力。
举个例子,假设一个人在晨跑。在晨跑时,他的鞋带松了。现在这个人停止跑步,系鞋带,然后又开始跑步。这是一个典型的并发性示例。这个人能够同时处理跑步和系鞋带,这是一个人能够同时处理很多事情。
什么是并行性parallelism,它与并发concurrency有什么不同?
并行就是同时做很多事情。这听起来可能与并发类似,但实际上是不同的。
让我们用同样的慢跑例子更好地理解它。在这种情况下,我们假设这个人正在慢跑,并且使用它的手机听音乐。在这种情况下,一个人一边慢跑一边听音乐,那就是他同时在做很多事情。这就是所谓的并行性(parallelism)。
并发性和并行性——一种技术上的观点。
假设我们正在编写一个web浏览器。web浏览器有各种组件。其中两个是web页面呈现区域和下载文件从internet下载的下载器。假设我们以这样的方式构建了浏览器的代码,这样每个组件都可以独立地执行(这是在Java和Go中使用线程来完成的,我们可以在稍后使用Goroutines来实现这一点)。当这个浏览器运行在单个核处理器中时,处理器将在浏览器的两个组件之间进行上下文切换。它可能会下载一个文件一段时间,然后它可能会切换到呈现用户请求的网页的html。这就是所谓的并发性。并发进程从不同的时间点开始,它们的执行周期重叠。在这种情况下,下载和呈现从不同的时间点开始,它们的执行重叠。假设同一浏览器运行在多核处理器上。在这种情况下,文件下载组件和HTML呈现组件可能同时在不同的内核中运行。这就是所谓的并行性。

并行性Parallelism不会总是导致更快的执行时间。这是因为并行运行的组件可能需要相互通信。例如,在我们的浏览器中,当文件下载完成时,应该将其传递给用户,比如使用弹出窗口。这种通信发生在负责下载的组件和负责呈现用户界面的组件之间。这种通信开销在并发concurrent 系统中很低。当组件在多个内核中并行concurrent 运行时,这种通信开销很高。因此,并行程序并不总是导致更快的执行时间!
进程(Process),线程(Thread),协程(Coroutine,也叫轻量级线程)
进程
进程是一个程序在一个数据集中的一次动态执行过程,可以简单理解为“正在执行的程序”,它是CPU资源分配和调度的独立单位。
进程一般由程序、数据集、进程控制块三部分组成。我们编写的程序用来描述进程要完成哪些功能以及如何完成;数据集则是程序在执行过程中所需要使用的资源;进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。 进程的局限是创建、撤销和切换的开销比较大。
线程
线程是在进程之后发展出来的概念。 线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID、程序计数器、寄存器集合和堆栈共同组成。一个进程可以包含多个线程。
线程的优点是减小了程序并发执行时的开销,提高了操作系统的并发性能,缺点是线程没有自己的系统资源,只拥有在运行时必不可少的资源,但同一进程的各线程可以共享进程所拥有的系统资源,如果把进程比作一个车间,那么线程就好比是车间里面的工人。不过对于某些独占性资源存在锁机制,处理不当可能会产生“死锁”。
协程
协程是一种用户态的轻量级线程,又称微线程,英文名Coroutine,协程的调度完全由用户控制。人们通常将协程和子程序(函数)比较着理解。
子程序调用总是一个入口,一次返回,一旦退出即完成了子程序的执行。
与传统的系统级线程和进程相比,协程的最大优势在于其"轻量级",可以轻松创建上百万个而不会导致系统资源衰竭,而线程和进程通常最多也不能超过1万的。这也是协程也叫轻量级线程的原因。
协程的特点在于是一个线程执行,与多线程相比,其优势体现在:协程的执行效率极高。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
1.2 Goroutines
1.2.1 什么是Goroutines
go中使用Goroutines来实现并发concurrently。Goroutines是与其他函数或方法同时运行的函数或方法。Goroutines可以被认为是轻量级的线程。与线程相比,创建Goroutine的成本很小,它就是一段代码,一个函数入口。以及在堆上为其分配的一个堆栈(初始大小为4K,会随着程序的执行自动增长删除)。因此它非常廉价,Go应用程序可以并发运行数千个Goroutines。
Goroutines在线程上的优势。
- 与线程相比,Goroutines非常便宜。它们只是堆栈大小的几个kb,堆栈可以根据应用程序的需要增长和收缩,而在线程的情况下,堆栈大小必须指定并且是固定的
- Goroutines被多路复用到较少的OS线程。在一个程序中可能只有一个线程与数千个Goroutines。如果线程中的任何Goroutine都表示等待用户输入,则会创建另一个OS线程,剩下的Goroutines被转移到新的OS线程。所有这些都由运行时进行处理,我们作为程序员从这些复杂的细节中抽象出来,并得到了一个与并发工作相关的干净的API。
- 当使用Goroutines访问共享内存时,通过设计的通道可以防止竞态条件发生。通道可以被认为是Goroutines通信的管道。
1.2.2 如何使用Goroutines
在函数或方法调用前面加上关键字go,您将会同时运行一个新的Goroutine。
实例代码:
package main
import (
"fmt"
)
func hello() {
fmt.Println("Hello world goroutine")
}
func main() {
go hello()
fmt.Println("main function")
}
运行结果:可能会值输出“main function”。
main function
我们开始的Goroutine怎么样了?我们需要了解Goroutine的规则
- 当新的Goroutine开始时,Goroutine调用立即返回。与函数不同,go不等待Goroutine执行结束。当Goroutine调用,并且Goroutine的任何返回值被忽略之后,go立即执行到下一行代码。
- main的Goroutine应该为其他的Goroutines执行。如果main的Goroutine终止了,程序将被终止,而其他Goroutine将不会运行。
修改以上代码:
package main
import (
"fmt"
"time"
)
func hello() {
fmt.Println("Hello world goroutine")
}
func main() {
go hello()
time.Sleep(1 * time.Second)
fmt.Println("main function")
}
运行结果:
Hello world goroutine
main function
在上面的程序中,我们已经调用了时间包的Sleep方法,它会在执行过程中休眠。在这种情况下,main的goroutine被用来睡觉1秒。现在调用go hello()有足够的时间在main Goroutine终止之前执行。这个程序首先打印Hello world goroutine,等待1秒,然后打印main函数。
1.2.3 启动多个Goroutines
示例代码:
package main
import (
"fmt"
"time"
)
func numbers() {
for i := 1; i <= 5; i++ {
time.Sleep(250 * time.Millisecond)
fmt.Printf("%d ", i)
}
}
func alphabets() {
for i := 'a'; i <= 'e'; i++ {
time.Sleep(400 * time.Millisecond)
fmt.Printf("%c ", i)
}
}
func main() {
go numbers()
go alphabets()
time.Sleep(3000 * time.Millisecond)
fmt.Println("main terminated")
}
运行结果:
1 a 2 3 b 4 c 5 d e main terminated
时间轴分析:
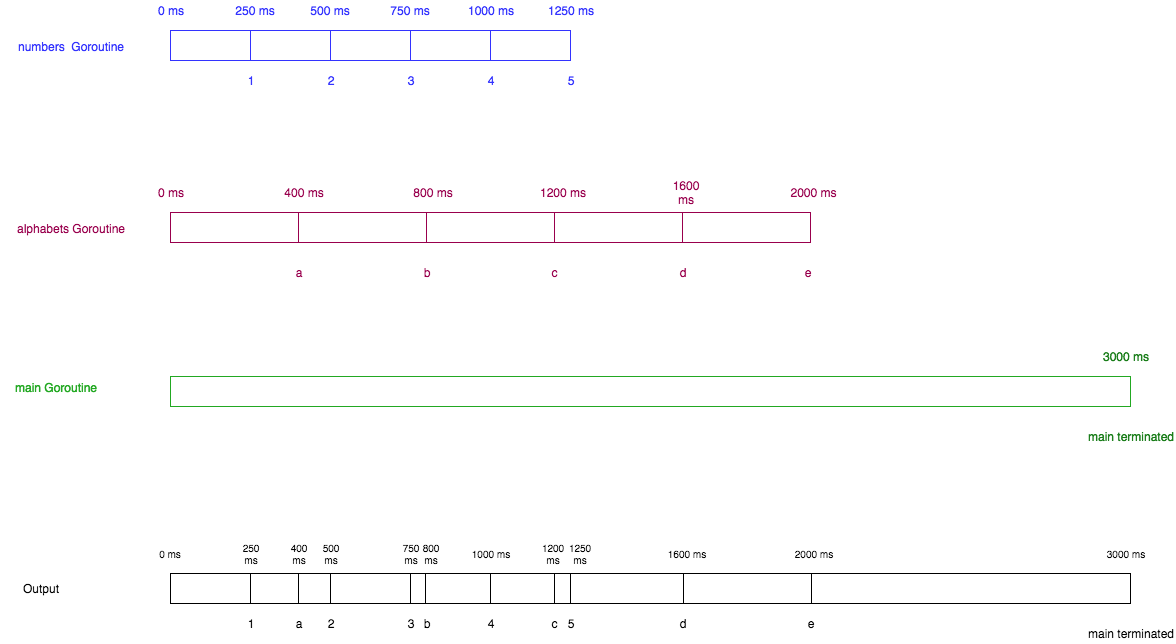
1.3通道channels
通道可以被认为是Goroutines通信的管道。类似于管道中的水从一端到另一端的流动,数据可以从一端发送到另一端,通过通道接收。
1.3.1 声明通道
每个通道都有与其相关的类型。该类型是通道允许传输的数据类型。(通道的零值为nil。nil通道没有任何用处,因此通道必须使用类似于地图和切片的方法来定义。)
示例代码:
package main
import "fmt"
func main() {
var a chan int
if a == nil {
fmt.Println("channel a is nil, going to define it")
a = make(chan int)
fmt.Printf("Type of a is %T", a)
}
}
运行结果:
channel a is nil, going to define it
Type of a is chan int
也可以简短的声明:
a := make(chan int)
1.3.2 发送和接收
发送和接收的语法:
data := <- a // read from channel a
a <- data // write to channel a
在通道上箭头的方向指定数据是发送还是接收。
1.3.3 发送和接收默认是阻塞的
一个通道发送和接收数据,默认是阻塞的。当一个数据被发送到通道时,在发送语句中被阻塞,直到另一个Goroutine从该通道读取数据。类似地,当从通道读取数据时,读取被阻塞,直到一个Goroutine将数据写入该通道。
这些通道的特性是帮助Goroutines有效地进行通信,而无需像使用其他编程语言中非常常见的显式锁或条件变量。
示例代码:
package main
import (
"fmt"
)
func hello(done chan bool) {
fmt.Println("Hello world goroutine")
done <- true
}
func main() {
done := make(chan bool)
go hello(done)
<-done // 接收数据,阻塞式
fmt.Println("main function")
}
运行结果:
Hello world goroutine
main function
在上面的程序中,我们在第一行中创建了一个done bool通道。把它作为参数传递给hello Goroutine。第14行我们正在接收已完成频道的数据。这一行代码是阻塞的,这意味着在某些Goroutine将数据写入到已完成的通道之前,程序将不会执行到下一行代码。因此,这就消除了对时间的需求。睡眠在原来的程序中,以防止主要的Goroutine退出。
代码<-done接收来自done Goroutine的数据,但不使用或存储任何变量中的数据。这是完全合法的。
现在,我们的main Goroutine阻塞等待已完成通道的数据。hello Goroutine接收这个通道作为参数,打印hello world Goroutine,然后写入done通道。当此写入完成时,main的Goroutine接收来自已完成通道的数据,它是未阻塞的,然后输出文本主函数。
让我们通过在hello Goroutine中引入睡眠来修改这个程序,以更好地理解这个阻塞的概念。
package main
import (
"fmt"
"time"
)
func hello(done chan bool) {
fmt.Println("hello go routine is going to sleep")
time.Sleep(4 * time.Second)
fmt.Println("hello go routine awake and going to write to done")
done <- true
}
func main() {
done := make(chan bool)
fmt.Println("Main going to call hello go goroutine")
go hello(done)
<-done
fmt.Println("Main received data")
}
再一个例子,这个程序将打印一个数字的个位数的平方和。
package main
import (
"fmt"
)
func calcSquares(number int, squareop chan int) {
sum := 0
for number != 0 {
digit := number % 10
sum += digit * digit
number /= 10
}
squareop <- sum
}
func calcCubes(number int, cubeop chan int) {
sum := 0
for number != 0 {
digit := number % 10
sum += digit * digit * digit
number /= 10
}
cubeop <- sum
}
func main() {
number := 589
sqrch := make(chan int)
cubech := make(chan int)
go calcSquares(number, sqrch)
go calcCubes(number, cubech)
squares, cubes := <-sqrch, <-cubech
fmt.Println("Final output", squares + cubes)
}
运行结果:
Final output 1536
1.3.4 死锁
使用通道时要考虑的一个重要因素是死锁。如果Goroutine在一个通道上发送数据,那么预计其他的Goroutine应该接收数据。如果这种情况不发生,那么程序将在运行时出现死锁。
类似地,如果Goroutine正在等待从通道接收数据,那么另一些Goroutine将会在该通道上写入数据,否则程序将会死锁。
示例代码:
package main
func main() {
ch := make(chan int)
ch <- 5
}
报错:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
/tmp/sandbox249677995/main.go:6 +0x80
1.3.5 定向通道
之前我们学习的通道都是双向通道,我们可以通过这些通道接收或者发送数据。我们也可以创建单向通道,这些通道只能发送或者接收数据。
创建仅能发送数据的通道,示例代码:
package main
import "fmt"
func sendData(sendch chan<- int) {
sendch <- 10
}
func main() {
sendch := make(chan<- int)
go sendData(sendch)
fmt.Println(<-sendch)
}
示例代码:
package main
import "fmt"
func sendData(sendch chan<- int) {
sendch <- 10
}
func main() {
chnl := make(chan int)
go sendData(chnl)
fmt.Println(<-chnl)
}
1.3.6 关闭通道和通道上的范围循环
发送者有可以通过关闭信道,来通知接收方不会有更多的数据被发送到信道上。
接收者可以在接收来自通道的数据时使用额外的变量来检查通道是否已经关闭。
语法结构:
v, ok := <- ch
在上面的语句中,如果ok的值是true,表示成功的将value值发送到一个通道。如果ok是false,这意味着我们正在从一个封闭的通道读取数据。从闭通道读取的值将是通道类型的零值。
例如,如果通道是一个int通道,那么从封闭通道接收的值将为0。
示例代码:
package main
import (
"fmt"
)
func producer(chnl chan int) {
for i := 0; i < 10; i++ {
chnl <- i
}
close(chnl)
}
func main() {
ch := make(chan int)
go producer(ch)
for {
v, ok := <-ch
if ok == false {
break
}
fmt.Println("Received ", v, ok)
}
}
运行结果
Received 0 true
Received 1 true
Received 2 true
Received 3 true
Received 4 true
Received 5 true
Received 6 true
Received 7 true
Received 8 true
Received 9 true
在上面的程序中,producer Goroutine将0到9写入chnl通道,然后关闭通道。主函数里有一个无限循环。它检查通道是否在行号中使用变量ok关闭。如果ok是假的,则意味着通道关闭,因此循环结束。还可以打印接收到的值和ok的值。for循环的for range形式可用于从通道接收值,直到它关闭为止。
使用range循环,示例代码:
package main
import (
"fmt"
)
func producer(chnl chan int) {
for i := 0; i < 10; i++ {
chnl <- i
}
close(chnl)
}
func main() {
ch := make(chan int)
go producer(ch)
for v := range ch {
fmt.Println("Received ",v)
}
}
1.3.7 缓冲通道
之前学习的所有通道基本上都没有缓冲。发送和接收到一个未缓冲的通道是阻塞的。
可以用缓冲区创建一个通道。发送到一个缓冲通道只有在缓冲区满时才被阻塞。类似地,从缓冲通道接收的信息只有在缓冲区为空时才会被阻塞。
可以通过将额外的容量参数传递给make函数来创建缓冲通道,该函数指定缓冲区的大小。
语法:
ch := make(chan type, capacity)
上述语法的容量应该大于0,以便通道具有缓冲区。默认情况下,无缓冲通道的容量为0,因此在之前创建通道时省略了容量参数。
示例代码:
package main
import (
"fmt"
)
func main() {
ch := make(chan string, 2)
ch <- "naveen"
ch <- "paul"
fmt.Println(<- ch)
fmt.Println(<- ch)
}
二、包(Package)
2.1 什么是包?为什么使用包?
到目前为止,我们已经看到了go程序,它只有一个文件,它的主函数有几个其他函数。在现实开发中,这种在单个文件中编写所有源代码的方法是行不通的。这样就不可能重用和维护代码。这时可以使用包。
包被用来组织go源代码,以便更好地重用和可读性。包提供了代码的划分,因此很容易维护应用程序。
例如,我们正在创建一个go图像处理应用程序,它提供了图像裁剪、锐化、模糊和颜色增强等功能。组织此应用程序的一种方法是将与某个特性相关的所有代码分组到它自己的包中。例如,裁剪可以是一个单独的包,锐化可以是另一个包。这样做的好处是,颜色增强功能可能需要一些锐化功能。颜色增强代码可以简单地导入(我们将在一分钟内讨论导入)这个锐化包并开始使用它的功能。这样,代码就变得易于重用。
我们将逐步创建一个应用程序来计算矩形的面积和对角线。
我们将通过这个应用程序更好地理解包。
2.2 main函数和main包
每个可执行的应用程序必须包含一个主函数。这个函数是执行的入口点。主函数应该存在main包中。
指定特定源文件属于包的代码行是package packagename。这应该是每个go源文件的第一行。
让我们首先创建应用程序的主函数和主包。
在go工作区的src文件夹中创建一个文件夹,并将其命名为geometry。创建一个文件geometry.go。
//geometry.go
package main // 该行代码,主要用于指定这个go文件 属于main包。
import "fmt" // 用于导入一个现有的包,现在导入的是包含Println方法的fmt包
func main() { // 主函数,作为程序执行的入口
fmt.Println("Geometrical shape properties")
}
第一行代码package main ,主要用于指定这个go文件 属于main包。