前言
前一段时间花费了不少时间,系统的学习了一下kubernetes的相关设计的资料,在这整理分享一下,希望能够帮助有需要的人。
PS文章大量资料参考自网络。重要的参考资源就是JimmySong的HandBook。
Kubernetes是什么
Kubernetes最初源于谷歌内部的Borg,提供了面向应用的容器集群部署和管理系统。Kubernetes的目标旨在消除编排物理/虚拟计算,网络和存储基础设施的负担,并使应用程序运营商和开发人员完全将重点放在以容器为中心的原语上进行自助运营。Kubernetes 也提供稳定、兼容的基础(平台),用于构建定制化的workflows 和更高级的自动化任务。 Kubernetes 具备完善的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和服务发现机制、内建负载均衡器、故障发现和自我修复能力、服务滚动升级和在线扩容、可扩展的资源自动调度机制、多粒度的资源配额管理能力。 Kubernetes 还提供完善的管理工具,涵盖开发、部署测试、运维监控等各个环节。
作用就像下面这附图所示,Kubernetes是云原生软件系统的操作系统。
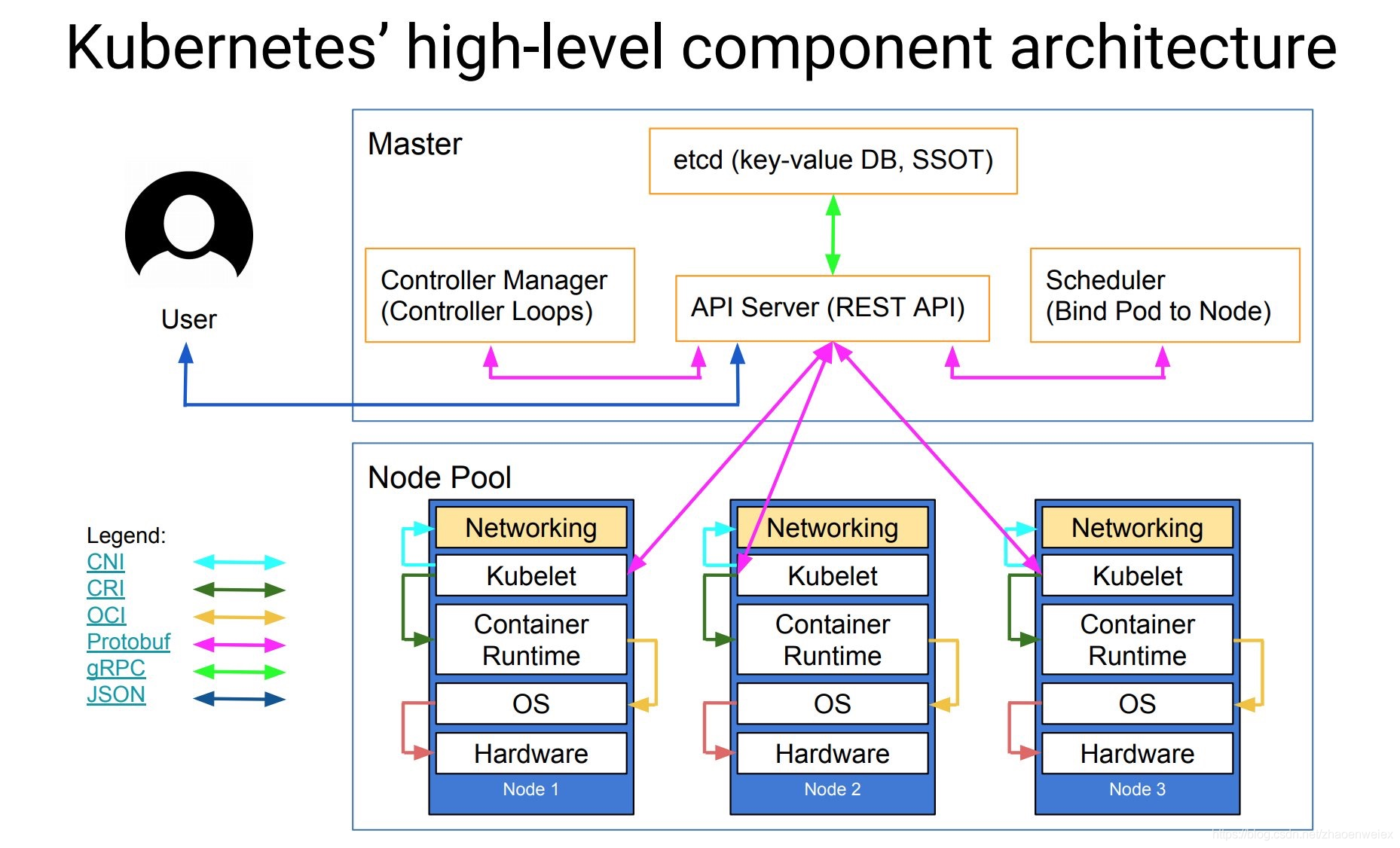
架构设计
Kubernetes主要由以下几个核心组件组成:
- etcd,保存了整个集群的状态; apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
- controller manager,负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler,负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
- kubelet,负责维护容器的生命周期,同时也负责Volume(CSI)和网络(CNI)的管理;
- Container runtime,负责镜像管理以及Pod和容器的真正运行(CRI);
- kube-proxy,负责为Service提供cluster内部的服务发现和负载均衡;
所以我们在手动部署的时候也是需要在master上部署etcd,kube-apiserver,kube-controller-manager,kube-scheduler,在node上部署kublet,kube-proxy
Kubernetes可以分为五个层次,由上到下分别为:生态系统,接口层,管理层,应用层,核心层。
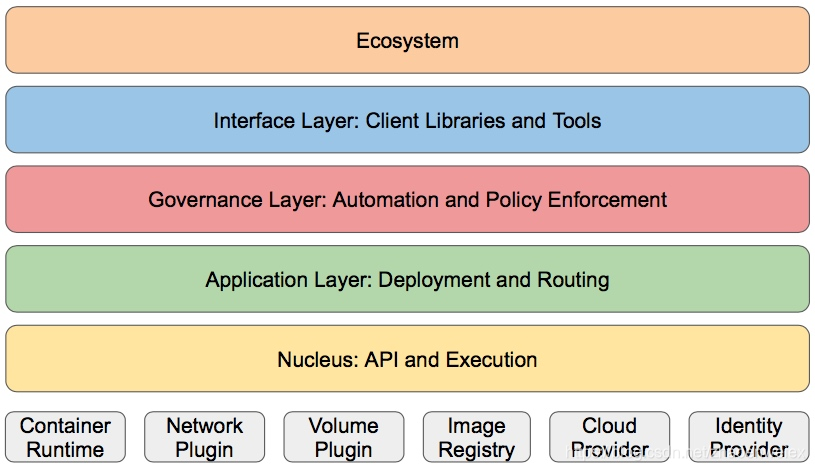
生态系统:在接口层之上的庞大容器集群管理调度的生态系统
接口层:kubectl命令行工具、客户端SDK以及集群联邦,说到接口层就的说到其API设计原则
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
API相关设计
API原则
- 所有API应该是声明式的。声明式的操作,相对于命令式操作,对于重复操作的效果是稳定的,这对于容易出现数据丢失或重复的分布式环境来说是很重要的。另外,声明式操作更容易被用户使用,可以使系统向用户隐藏实现的细节,隐藏实现的细节的同时,也就保留了系统未来持续优化的可能性。此外,声明式的API,同时隐含了所有的API对象都是名词性质的,例如Service、Volume这些API都是名词,这些名词描述了用户所期望得到的一个目标分布式对象。
- API对象是彼此互补而且可组合的。这里面实际是鼓励API对象尽量实现面向对象设计时的要求,即“高内聚,松耦合”,对业务相关的概念有一个合适的分解,提高分解出来的对象的可重用性。
- 高层API以操作意图为基础设计。如何能够设计好API,跟如何能用面向对象的方法设计好应用系统有相通的地方,高层设计一定是从业务出发,而不是过早的从技术实现出发。因此,针对Kubernetes的高层API设计,一定是以Kubernetes的业务为基础出发,也就是以系统调度管理容器的操作意图为基础设计。
- 低层API根据高层API的控制需要设计。设计实现低层API的目的,是为了被高层API使用,考虑减少冗余、提高重用性的目的,低层API的设计也要以需求为基础,要尽量抵抗受技术实现影响的诱惑。
- 尽量避免简单封装,不要有在外部API无法显式知道的内部隐藏的机制。简单的封装,实际没有提供新的功能,反而增加了对所封装API的依赖性。内部隐藏的机制也是非常不利于系统维护的设计方式,例如StatefulSet和ReplicaSet,本来就是两种Pod集合,那么Kubernetes就用不同API对象来定义它们,而不会说只用同一个ReplicaSet,内部通过特殊的算法再来区分这个ReplicaSet是有状态的还是无状态。
- API操作复杂度与对象数量成正比。这一条主要是从系统性能角度考虑,要保证整个系统随着系统规模的扩大,性能不会迅速变慢到无法使用,那么最低的限定就是API的操作复杂度不能超过O(N),N是对象的数量,否则系统就不具备水平伸缩性了。
- API对象状态不能依赖于网络连接状态。由于众所周知,在分布式环境下,网络连接断开是经常发生的事情,因此要保证API对象状态能应对网络的不稳定,API对象的状态就不能依赖于网络连接状态。
- 尽量避免让操作机制依赖于全局状态,因为在分布式系统中要保证全局状态的同步是非常困难的。
API结构
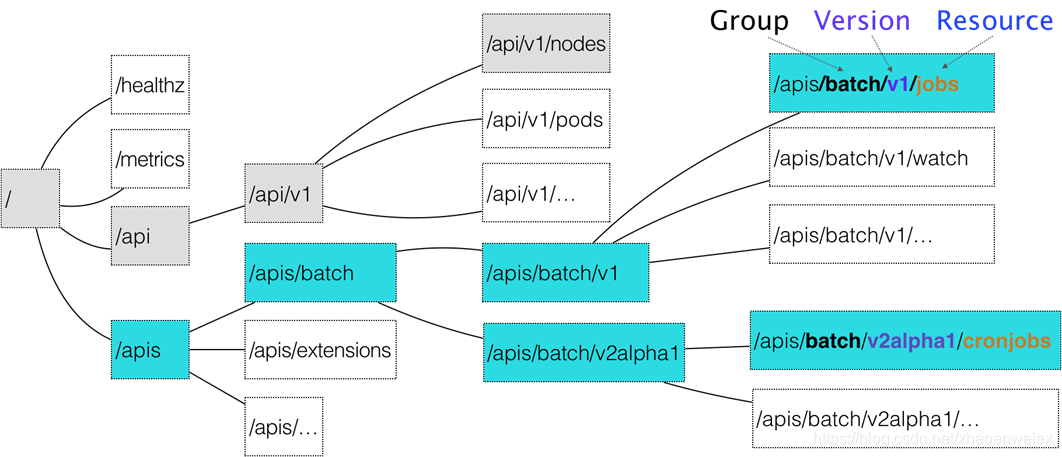
API原理
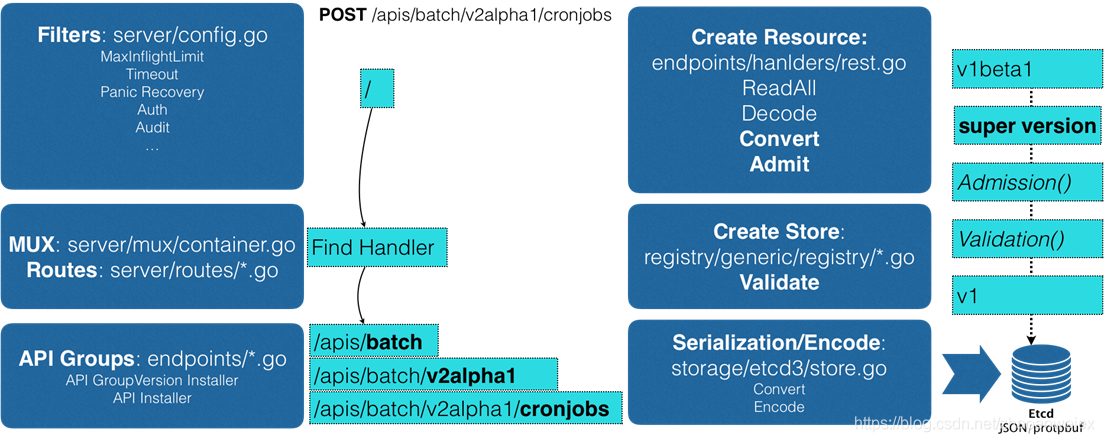
总结
kubernetes来自于谷歌的Brog但其在开源精神的洗礼下完成了再一次升级,尤其API的设计感觉堪称业界典范。要想了解一个软件技术人员的水平到底如何只需要看看他给出的接口设计就能了解一二了。
又发现了一个不错的面试题目。
参考资料
- https://jimmysong.io/kubernetes-handbook
- 极客时间的专栏,深入剖析Kubernetes