这篇主要是进行代码中的一些数值可视化,帮助理解
代码来自于知乎:https://zhuanlan.zhihu.com/p/32078473
/代码地址https://github.com/chengstone/movie_recommender/blob/master/movie_recommender.ipynb
数据预处理过程中的预览:(可以跳过看图片结果)
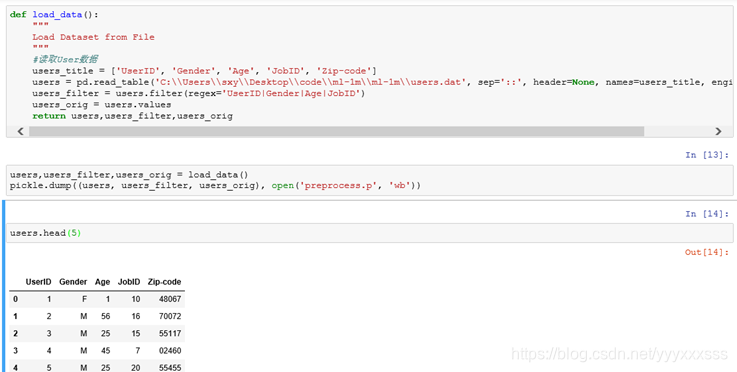
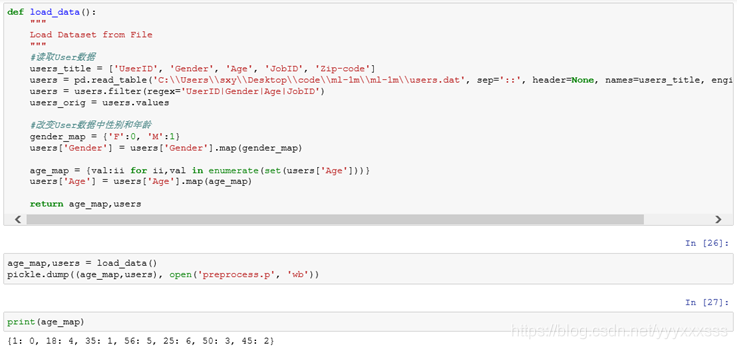
1.1、Users的初始读取显示
1、Pandas中可以用dataframe.head()和dataframe.tail()查看数据的头五行和尾五行,若需要改变行数,可在括号内指定
pandas主要的两个数据结构是Series和DataFrame
Series可以简单地被认为是一维的数组,Series和一维数组最主要的区别在于Series类型具有索引(index)
DataFrame是将数个Series按列合并而成的二维数据结构,每一列单独取出来是一个Series
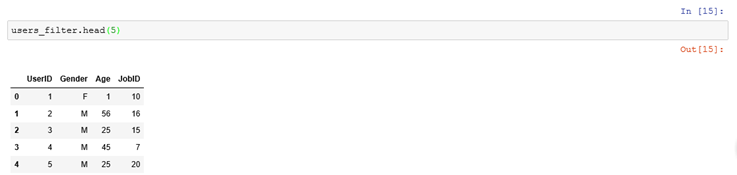
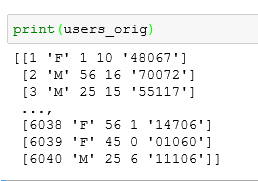
dataframe.values则以数组的形式返回DataFrame的元素:所以注意对于users.value的显示不能用head
2、users.value返回的是一个numpy.ndarray类型
如果没有numpy,Python内部只能用list或array来表示矩阵。
假如用list来表示[1,2,3],由于list的元素可以是任何对象,因此list中所保存的是对象的指针,这样就需要有3个指针和三个整数对象,比较浪费内存和CPU计算时间。
Python的array和list不同,它直接保存数值,和C语言的一维数组比较类似,但是不支持多维,表达形式很简陋,写科学计算的算法很难受。
numpy弥补了这些不足,核心贡献就是提供了ndarray这个存储单一数据类型的多维数组结构
3、ndarray介绍
ndarray可以用np.array这个函数来创建
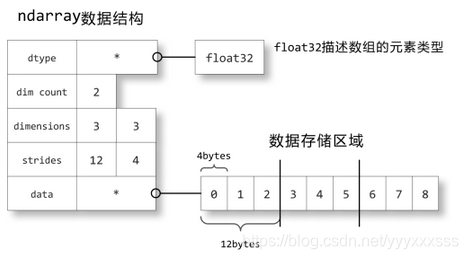
关于数组的描述信息保存在一个数据结构中,这个结构引用两个对象,一块用于保存数据的存储区域和一个用于描述元素类型的dtype对象。
数据存储区域保存着数组中所有元素的二进制数据,dtype对象则知道如何将元素的二进制数据转换为可用的值。数组的维数、大小等信息都保存在ndarray数组对象的数据结构中。
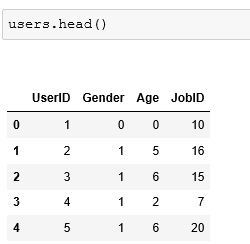
1.2、users表预处理后的显示
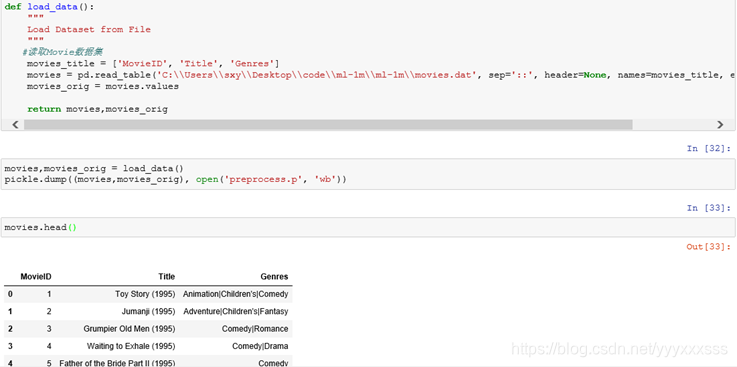
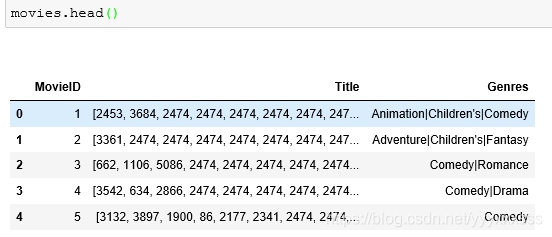
2.1、movie数据的初始读取

2.2、movies去掉年份



For ii,val in enumerate(set(movies['Title'])) 打印ii,val显示:

2.3、movie title转数字字典

For 循环后的title_set如下,加入的是一个单词

Title2int

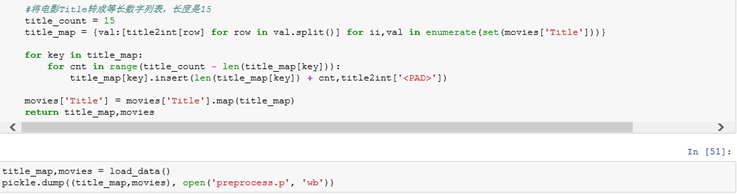
2.4电影Title转成等长数字列表,长度是15


2.5 电影genres转数字字典






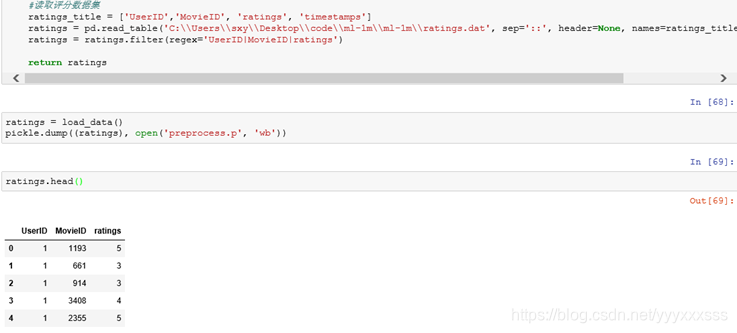
3 ratings读取
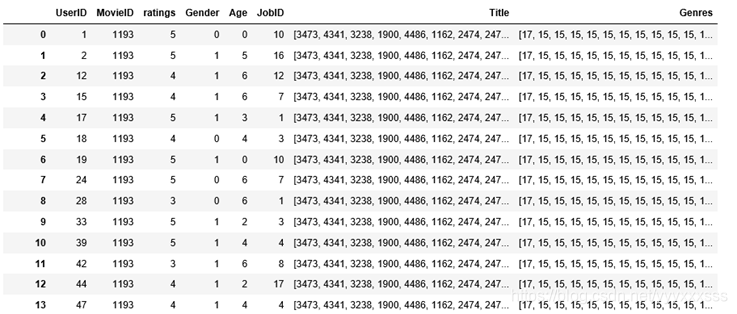
4、合并三个表
data = pd.merge(pd.merge(ratings, users), movies)
5、输入x和目标y


6、features_pd.values 和 targets_pd.values

