什么是高可用
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
如何保障高可用
减少单点,服务器集群化
服务分层,并且每层都是集群,当集群中一个节点发生故障时,要自动将请求转移到可用节点上,此转移过程要对调用方透明
常见的服务分层思路
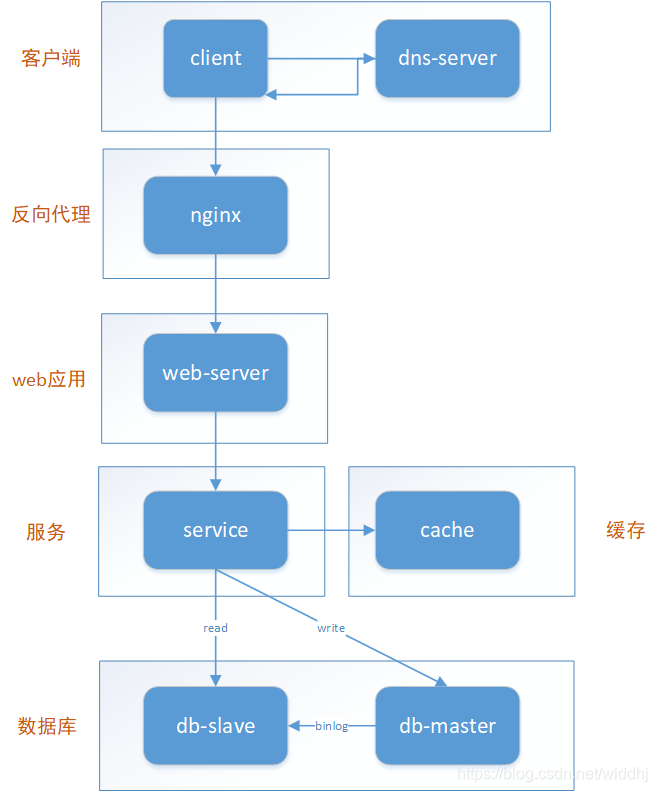
- 客户端层:典型调用方是浏览器browser或者手机应用APP
- 反向代理层:系统入口,反向代理
- 站点应用层:实现核心应用逻辑,返回html或者json
- 服务层:如果实现了服务化,就有这一层
- 数据-缓存层:缓存加速访问存储
- 数据-数据库层:数据库固化数据存储
整个系统的高可用,又是通过每一层的冗余+自动故障转移来综合实现的。
总结
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
方法论上,高可用是通过冗余+自动故障转移来实现的。
整个互联网分层系统架构的高可用,又是通过每一层的冗余+自动故障转移来综合实现的,具体的:
-
【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
-
【反向代理层】到【站点层】的高可用,是通过站点层的冗余实现的,常见实践是nginx与web-server之间的存活性探测与自动故障转移
-
【站点层】到【服务层】的高可用,是通过服务层的冗余实现的,常见实践是通过service-connection-pool来保证自动故障转移
-
【服务层】到【缓存层】的高可用,是通过缓存数据的冗余实现的,常见实践是缓存客户端双读双写,或者利用缓存集群的主从数据同步与sentinel保活与自动故障转移;更多的业务场景,对缓存没有高可用要求,可以使用缓存服务化来对调用方屏蔽底层复杂性
-
【服务层】到【数据库“读”】的高可用,是通过读库的冗余实现的,常见实践是通过db-connection-pool来保证自动故障转移
-
【服务层】到【数据库“写”】的高可用,是通过写库的冗余实现的,常见实践是keepalived + virtual IP自动故障转移