版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_36372879/article/details/84396421
Spark
Hadoop框架存在的问题
- JobTracker是MapReduce的集中处理点,存在单点故障的问题
- 以MapReduce task数目作为资源的表示比较简单,没有考虑CPU和内存占用情况
- 任务集中导致源代码复杂,增加bug修复和系统维护的难度
RDD
RDD(Resilient Distributed Dataset)是一个可读的、可分区的分布式数据集,任何数据在spark中都可以被表示为RDD
Spark应用程序
把需要处理的数据转为RDD,然后对RDD进行一系列的变换和操作
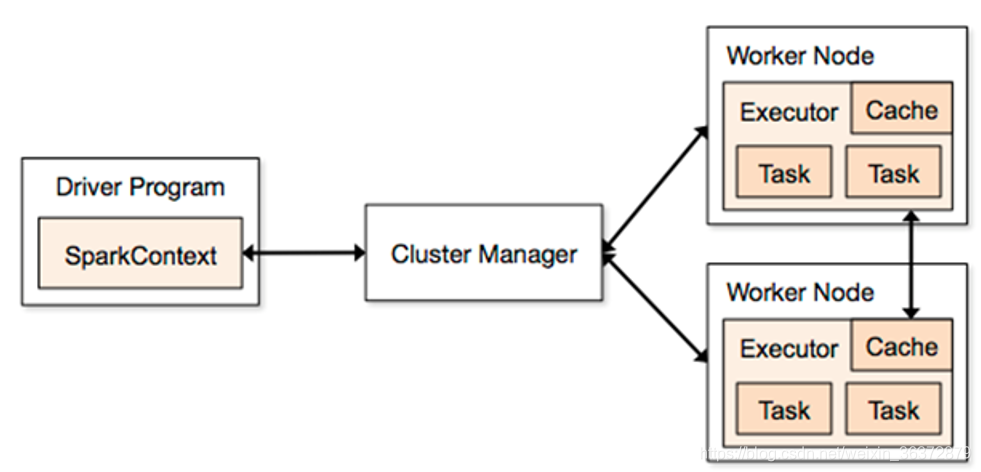
Driver Program程序入口,运行App的main,创建SparkContext
Cluster Manager:在集群上获取资源的外部服务
Workder Node:可以运行application代码的节点
Executor:一个进程,该进程负责运行task
Spark on yarn-cluster框架
Yarn的基本思想
Yarn的基本思想是将JobTracker的资源管理和作业调度分离
- 资源管理:ResourceManager
- 作业调度:ApplicationMaster创建SparkContext
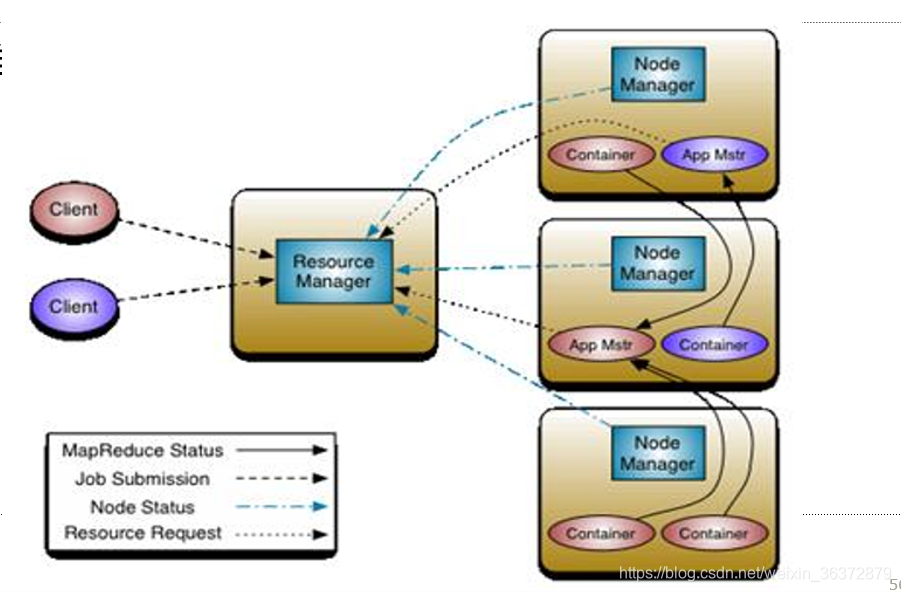
ResourceManager
负责资源管理与调度,资源管理的基本单位:task
NodeManager
节点代理,负责:
- 启动container/executor
- 监控资源使用情况给RM
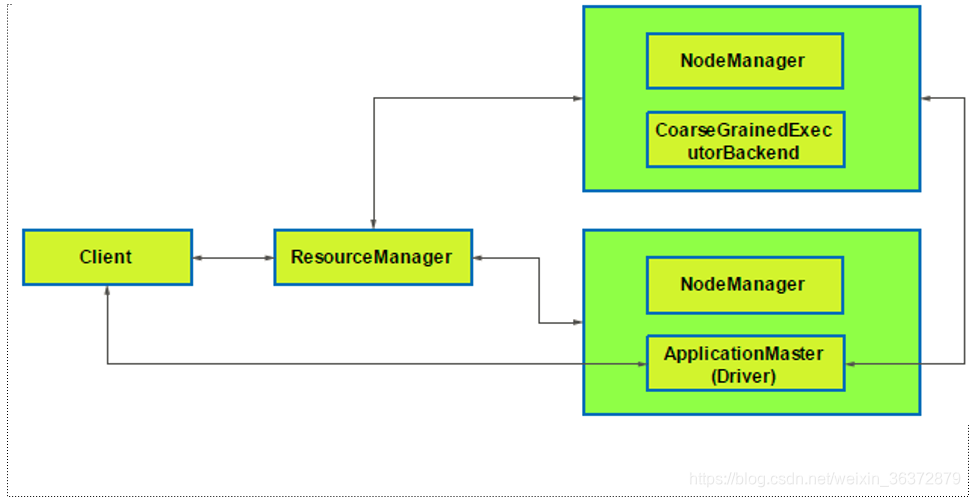
Application Master
负责作业调度
- 是第一个container
- 启动SparkContext
SparkContext
- 向RM注册
- 向RM申请资源
- 启动executor等待task
- 分配task给NM上的executor
- 监控task的运行情况
Spark on yarn-cluster流程
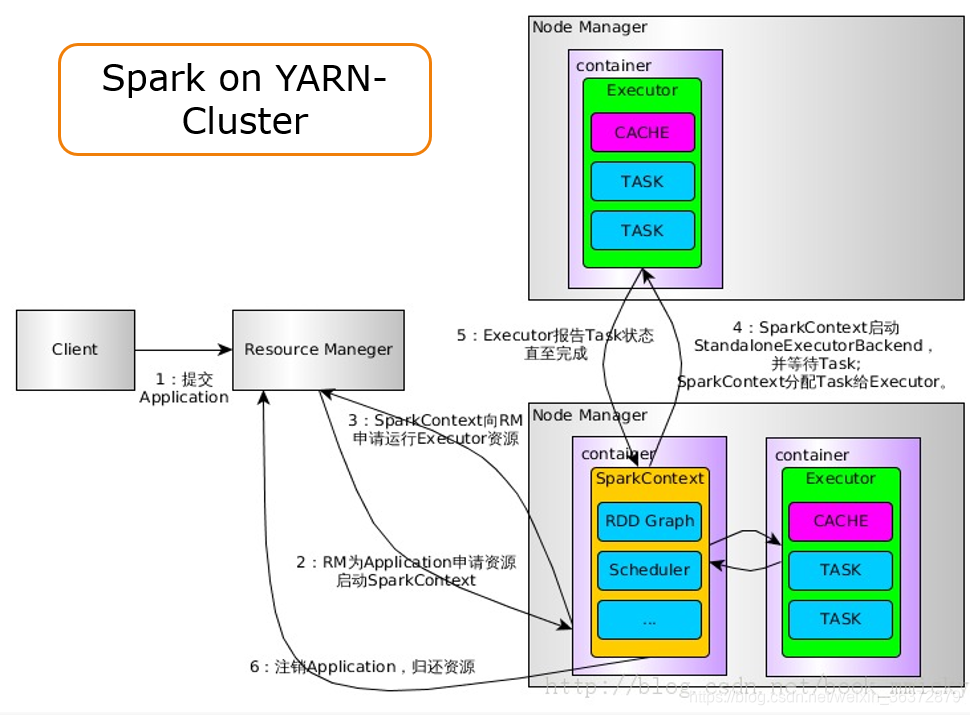
- 提交Application给RM
- RM向NodeManager申请第一个container给Application Master,Application Mater初始化SparkContext
- SparkContext向RM注册,并且申请运行executor的资源
- SparkContext和NodeManager通信,启动executor,SparkContext分配task给executor执行
- executor报告task的状态,直至完成
- 注销Application,归还资源