题目
| [编程题] 用户喜好 时间限制:3秒 空间限制:262144K 为了不断优化推荐效果,今日头条每天要存储和处理海量数据。假设有这样一种场景:我们对用户按照它们的注册时间先后来标号,对于一类文章,每个用户都有不同的喜好值,我们会想知道某一段时间内注册的用户(标号相连的一批用户)中,有多少用户对这类文章喜好值为k。因为一些特殊的原因,不会出现一个查询的用户区间完全覆盖另一个查询的用户区间(不存在L1<=L2<=R2<=R1)。
输入: 第1行为n代表用户的个数 第2行为n个整数,第i个代表用户标号为i的用户对某类文章的喜好度 第3行为一个正整数q代表查询的组数 第4行到第(3+q)行,每行包含3个整数l,r,k代表一组查询,即标号为l<=i<=r的用户中对这类文章喜好值为k的用户的个数。 数据范围n <= 300000,q<=300000 k是整型 输出描述: 输出:一共q行,每行一个整数代表喜好值为k的用户的个数
5
1
样例解释: |
思路:
在给出的一个数组中,在l和r之间,有多少个k。如何直接遍历查找的话会超时。其实我们可以把用户
喜好即K值作为一个标记,然后里面存储数组的index,接着判断index是否在l和r之间就行了。
- 使用链表数组来做的,k值作为数组下标,但是后来发现K值很大,会出现数组越界
- 题目没有给出K值的限制,如果直接使用数组下标来作为k值的标记,那么会出现数组越界错误。所以,我们使用
HashMap,用户爱好作为key,value为相同爱好的数组的index,我们使用一个单链表来存储value。
import java.util.*;
public class Main{
/**
* 创建一个HashMap的对象
* 声明一个类型为 HashMap的引用变量hashMap,注意键值对为<Integer,Node>
* 把新的HashMap的对象赋值给hashMap这个引用变量(即引用变量指向这个对象)
*/
public static HashMap<Integer,Node> hashMap=new HashMap<>();
/**
* 创建一个单链表
*/
static class Node{
private int position;
private Node Next;
public Node(int position ) {
this.position= position;
}
/**
* 该链表中增加node节点的方法
* 如果当前节点的Next为null,则把新的节点newNode赋值给当前节点
* 否则,在当前节点的Next指向下一个节点newNode
* @param newNode
*/
public void addNode(Node newNode){
if(this.Next==null){
this.Next= newNode;
}else{
this.Next.addNode(newNode);
}
}
}
public static void main(String[] args){
/**
* 通过new Scanner(System.in)创建一个Scanner对象,控制台会一直等待输入,直到敲回车键结束,把所输入的内容传给Scanner,作为扫描对象。
* 把扫描对象赋值给in这个引用变量
* 注意 nextInt()与nextLine()区别
*/
Scanner in = new Scanner(System.in);
int n,q,l,r,k,num;
n= in.nextInt();
for(int i=1;i<=n;i++){
num= in.nextInt();
Node node =new Node(i);//创建不同的Node对象给,并赋值给引用变量node
/**
* hashMap.get(num)
* num相当于hashMap<key,value>中的key
* hashMap.get(num) 获取对应的value值
*/
if(hashMap.get(num)!=null){//判断hashmap是否存在该用户喜好,存在就添加到链尾
hashMap.get(num).addNode(node);
}else if(hashMap.get(num)==null){
hashMap.put(num,node);
}
}
q=in.nextInt();
for(int i=0;i<q;i++){
l= in.nextInt();
r= in.nextInt();
k= in.nextInt();
int count = 0;
Node root= hashMap.get(k);
while(root!= null&&root.position<=r){
if(root.position>=l && root.position<=r){
count++;
}
root=root.Next;//指向下一个节点
}
System.out.println(count);
}
}
} 代码已经分析的很清楚了,说明的是,执行完语句后
Scanner in = new Scanner(System.in);
int n,q,l,r,k,num;
n= in.nextInt();
for(int i=1;i<=n;i++){
num= in.nextInt();
Node node =new Node(i);//创建不同的Node对象给,并赋值给引用变量node
/**
* hashMap.get(num)
* num相当于hashMap<key,value>中的key
* hashMap.get(num) 获取对应的value值
*/
if(hashMap.get(num)!=null){//判断hashmap是否存在该用户喜好,存在就添加到链尾
hashMap.get(num).addNode(node);
}else if(hashMap.get(num)==null){
hashMap.put(num,node);
}
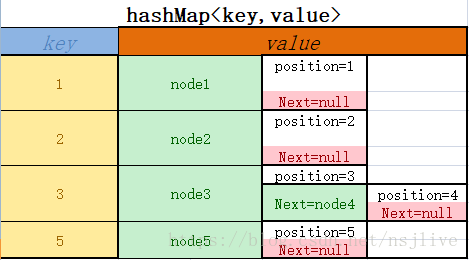
}哈希表及 链表情况如图所示:
代码参考自:https://blog.csdn.net/callmeMrLu/article/details/81917158