之前写过一篇利用Freemarker模板生成doc的博客,不过那个博客有点缺陷,生成的word占用的空间很大,几百页的word有将近100M了。所以,后面需求必须是生成的docx文档,结果导出后正常才几M,昨天花了一天的时间实现。
具体思路
1.把docx文档修改为ZIP格式(修改.docx后缀名为.zip)
2.获取zip里的document.xml文档以及_rels文件夹下的document.xml.rels文档
3.把内容填充到document.xml里,以及图片配置信息填充至document.xml.rels文档里
4.在输入docx文档的时候把填充过内容的的 document.xml、document.xml.rels用流的方式写入zip(详见下面代码)。
5.把图片写入zip文件下word/media文件夹中
6.输出docx文档
docx模板修改成zip格式后的信息如下(因为word文档本身就是ZIP格式实现的)
- document.xml里存放主要数据
- media存放图片信息
- _rels里存放配置信息
注意:如果docx模板里的图片带有具体路径的话,则图片的格式不受限制。
如果docx模板里里图片信息不带路径,则模板仅支持和模板图片类型一致的图片。
处理流程
1.准备好docx模板
2.把docx文档修改为ZIP格式(修改.docx后缀名为.zip)
3.获取zip文件里的word文件夹下的document.xml以及_rels文件夹里的document.xml.rels文件作为模板。
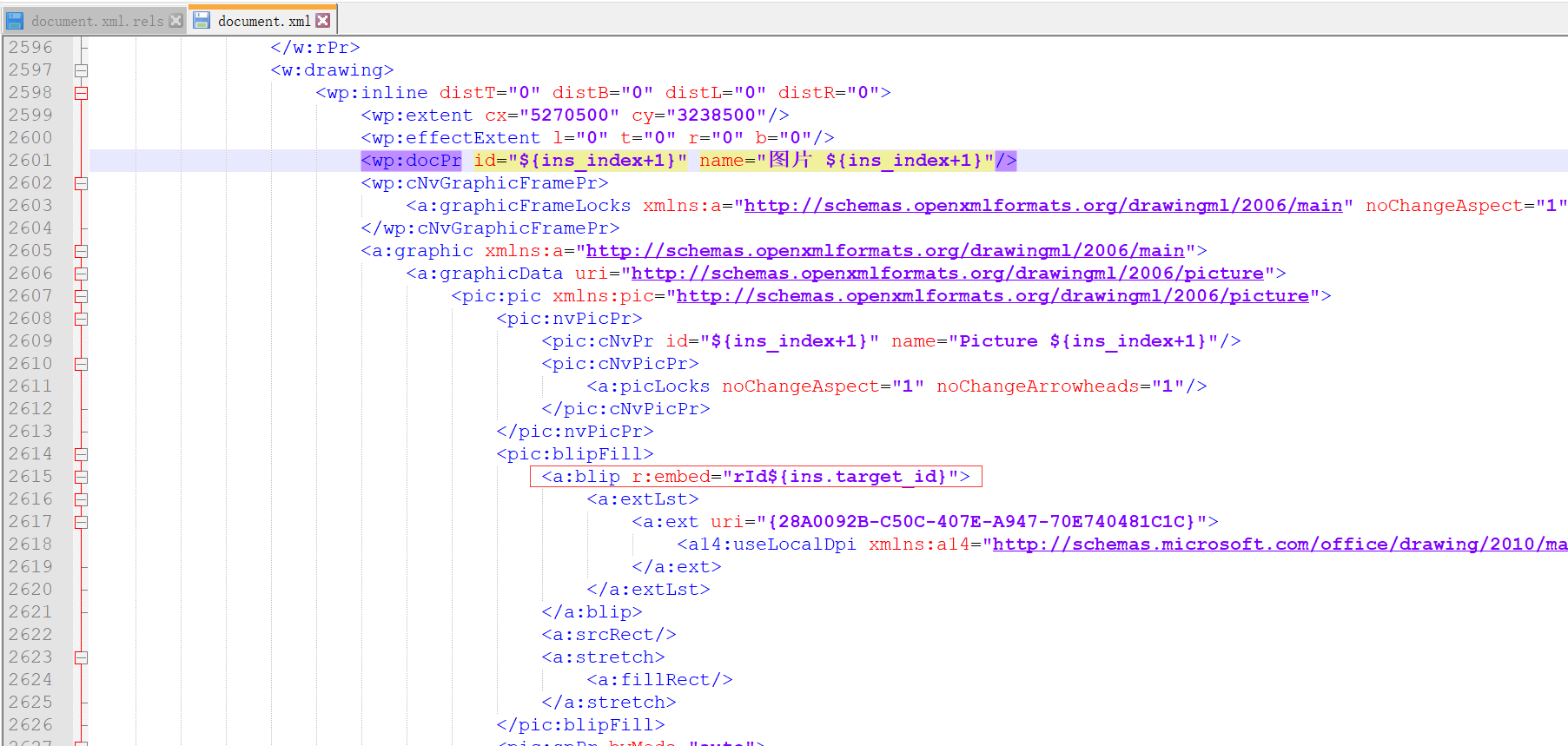
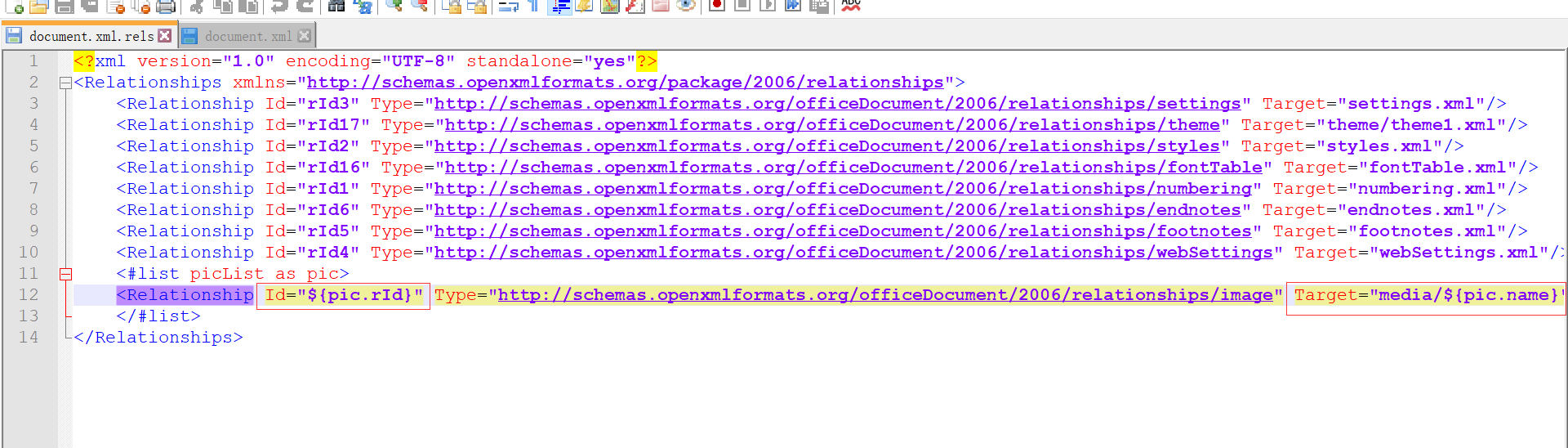
注意:这里图片配置信息是根据 rId来获取的,为了避免重复,可以根据自己具体的业务规则来实现
4.填充模板信息、写入图片信息。
//outputStream 输出流可以自己定义 浏览器或者文件输出流
public static void createDocx(Map dataMap,OutputStream outputStream) {
ZipOutputStream zipout = null;
try {
//图片配置文件模板
ByteArrayInputStream documentXmlRelsInput =FreeMarkUtils.getFreemarkerContentInputStream(dataMap, documentXmlRels);
//内容模板
ByteArrayInputStream documentInput = FreeMarkUtils.getFreemarkerContentInputStream(dataMap, document);
//最初设计的模板
File docxFile = new File(WordUtils.class.getClassLoader().getResource(template).getPath());
if (!docxFile.exists()) {
docxFile.createNewFile();
}
ZipFile zipFile = new ZipFile(docxFile);
Enumeration<? extends ZipEntry> zipEntrys = zipFile.entries();
zipout = new ZipOutputStream(outputStream);
//开始覆盖文档------------------
int len = -1;
byte[] buffer = new byte[1024];
while (zipEntrys.hasMoreElements()) {
ZipEntry next = zipEntrys.nextElement();
InputStream is = zipFile.getInputStream(next);
if (next.toString().indexOf("media") < 0) {
zipout.putNextEntry(new ZipEntry(next.getName()));
if (next.getName().indexOf("document.xml.rels") > 0) { //如果是document.xml.rels由我们输入
if (documentXmlRelsInput != null) {
while ((len = documentXmlRelsInput.read(buffer)) != -1) {
zipout.write(buffer, 0, len);
}
documentXmlRelsInput.close();
}
} else if ("word/document.xml".equals(next.getName())) {//如果是word/document.xml由我们输入
if (documentInput != null) {
while ((len = documentInput.read(buffer)) != -1) {
zipout.write(buffer, 0, len);
}
documentInput.close();
}
} else {
while ((len = is.read(buffer)) != -1) {
zipout.write(buffer, 0, len);
}
is.close();
}
}
}
//写入图片
List<Map<String, Object>> picList = (List<Map<String, Object>>) dataMap.get("picList");
for (Map<String, Object> pic : picList) {
ZipEntry next = new ZipEntry("word" + separator + "media" + separator + pic.get("name"));
zipout.putNextEntry(new ZipEntry(next.toString()));
InputStream in = (ByteArrayInputStream)pic.get("code");
while ((len = in.read(buffer)) != -1) {
zipout.write(buffer, 0, len);
}
in.close();
}
} catch (Exception e) {
logger.error("word导出失败:"+e.getStackTrace());
}finally {
if(zipout!=null){
try {
zipout.close();
} catch (IOException e) {
logger.error("io异常");
}
}
if(outputStream!=null){
try {
outputStream.close();
} catch (IOException e) {
logger.error("io异常");
}
}
}
}
/**
* 获取freemarker模板字符串
* @author lpf
*/
public class FreeMarkUtils {
private static Logger logger = LoggerFactory.getLogger(FreeMarkUtils.class);
public static Configuration getConfiguration(){
//创建配置实例
Configuration configuration = new Configuration(Configuration.VERSION_2_3_28);
//设置编码
configuration.setDefaultEncoding("utf-8");
configuration.setClassForTemplateLoading(FreeMarkUtils.class, "/template");
return configuration;
}
/**
* 获取模板字符串输入流
* @param dataMap 参数
* @param templateName 模板名称
* @return
*/
public static ByteArrayInputStream getFreemarkerContentInputStream(Map dataMap, String templateName) {
ByteArrayInputStream in = null;
try {
//获取模板
Template template = getConfiguration().getTemplate(templateName);
StringWriter swriter = new StringWriter();
//生成文件
template.process(dataMap, swriter);
in = new ByteArrayInputStream(swriter.toString().getBytes("utf-8"));//这里一定要设置utf-8编码 否则导出的word中中文会是乱码
} catch (Exception e) {
logger.error("模板生成错误!");
}
return in;
}
}
5.输出word测试
就是这么简单,比较麻烦的就是如果word比较复杂的话写freemarkr标签要仔细一些,还有word中的字符尽量对特殊字符有转义,否则会引起word打不开的现象。
总结
这里最重要的一个思想是把文件输出到ByteArrayOutputStream里,下载的时候把这个字节写出就行了。开发的时候注意编码问题,用这种方式导出还有一个好处就是,你会发现,同样一个word。导出doc格式的文件大小要比docx格式的文件大小大的多,所以还是推荐用这种;