版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Daycym/article/details/84197081
环境准备
- 1、服务器配置好hadoop2.7.3,详细配置过程可参考 hadoop2.7.3环境配置
- 2、本地安装好Eclipse,并配置好maven
- 3、本地解压hadoop-2.7.3,并下载winutils.exe文件放在自定义目录下
本地Eclipse配置maven
- 下载安装Eclipse,可上网参考
- 下载maven 官网
- 解压到自定义目录

- eclipse中配置maven【依次点击Windows->Preferences->Maven】

-
添加自定义的解压路径下的maven,并勾选,应用
-
修改maven默认的settings.xml

-
如果之后下载jar包时比较慢,可以通过maven的settings.xml配置镜像
-
在maven解压路径下的conf中settings.xml,记事本打开

阿里云maven镜像:
<mirrors>
<mirror>
<id>aliyun</id>
<name>aliyun maven</name>
<mirrorOf>central</mirrorOf>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</mirror>
</mirrors>
- 重启eclipse
由于我之前已经配置好,这里不一定能成功,可以自行参考网上的
解压hadoop,添加winutils.exe
- 下载hadoop-2.7.3.tar.gz 下载网站
- 解压到自定义目录
- 下载winutils.exe文件,放在自定义目录下
Eclipse准备
- 新建maven项目【new->other】




- 下载依赖包,打开pom.xml

- 添加hadoop客户端

添加并保存:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
- 保存后,maven dependencies下就会多很多jar包

如果之前没有下载过hadoop-client,因为要下载很多jar包会比较慢,通过设置maven镜像可以加快点下载速度
开始写代码(词频计数)
- 实现过程


- 创建包和类
package com.cym.dong.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyMapReduce {
//1. 自定义的map类
//继承Mapper类,<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
//输入的key,输入的value,输出的key,输出的value
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
//创建一个IntWritable类型的对象,给定值为1
IntWritable i = new IntWritable(1);
Text keystr = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String line = value.toString();
//传入每一个map方法的key和value做打印
System.out.println("key : "+key.get()+"--------- value : "+line);
String[] strs = line.split(" ");
for (String str : strs) {
//每一次循环遍历到一个单词就要输出到下一个步骤
keystr.set(str);
context.write(keystr, i);
}
/*StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
keystr.set(itr.nextToken());
context.write(keystr, i);
}*/
}
}
//2. 自定义的reduce类
//reducer类的输入,其实就是map类中map方法的输出
//输入key 输入value 输出key 输出value
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
IntWritable total = new IntWritable();
@Override
//Mapper类的map方法的数据输入到Reducer类的group方法中,得到<text, Iter(1,1)>,
//再将这个数据输入到Reducer类的reduce方法中
protected void reduce(Text inputKey, Iterable<IntWritable> inputValues,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//得到了key
String key = inputKey.toString();
//迭代Iterable,把每一个值相加
int count = 0;
//循环遍历迭代器中的所有值,做相加
for (IntWritable intWritable : inputValues) {
count += intWritable.get();
}
//把值设置到IntWritable,等待输出
total.set(count);
System.out.println("reduce输出结果: key:" + key +","+ count);
context.write(inputKey, total);
}
}
//3. 运行类,run方法,在测试的时候使用main函数,调用这个类的run方法来运行
/**
*
* @param args 参数是要接受main方法得到的参数,在run中使用
* @return
* @throws Exception
*/
public int run(String[] args) throws Exception {
//hadoop的配置的上下文
Configuration configuration = new Configuration();
//通过上下文构建一个job的实例,并且传入任务名称,单例!
Job job = Job.getInstance(configuration,this.getClass().getSimpleName());
//这个参数必须添加,否则本地运行没有问题,服务器上运行会报错
job.setJarByClass(MyMapReduce.class);
//设置任务从哪里读取数据
//调用这个方法的时候,要往args中传入参数,第一个位置上要传入从哪里读数据
Path inputpath = new Path(args[0]);
FileInputFormat.addInputPath(job, inputpath);
//调用这个方法的时候,要往args中传入参数,第二个位置上要传入结果数据保存到哪里
Path outputpath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outputpath);
//设置mapper类的参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce类的参数
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(2); //设置reduce数目
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0 : 1;
}
public static void main(String[] args) {
args = new String[]{
"hdfs://192.168.41.51:8020/test.txt",
"hdfs://192.168.41.51:8020/out1"
};
MyMapReduce mr = new MyMapReduce();
try {
int success = -1;
success = mr.run(args);
System.out.println("success:"+success);
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 开启hadoop服务器

自己写的脚本,也可一个个开始:
sbin/start-all-self.sh
-
运行程序
-
报错1

-
解决方法
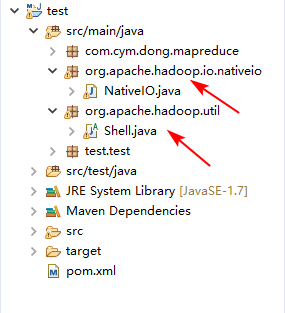
在任意处输入import org.apache.hadoop.util.Shell;鼠标悬浮在Shell上,按住Ctrl点击鼠标左键

.class不可以修改,Ctrl+a,Ctrl+c全部复制
点到项目的src/main/java目录上,Ctrl+v

- 修改
Shell.java

-
报错2

-
解决方法
直接点击上面报错中的蓝色字体,609那个

按上面同样的方式复制粘贴
修改609行,让它强行返回true

最后运行
-
目录结构
-
测试文件内容

-
运行结果

-
查看
http://dong-01.cym.com:50070

补充(添加日志输出)
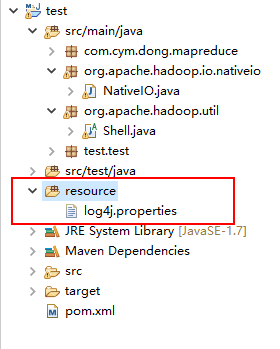
- 添加
log4j.properties文件
- 修改下输出为
out2 - 运行结果,就可以输出日志

打包类
-
注释代码

-
右键类名,点击
Export
- 选择JAR file

- 选择保存路径,Next

- Next

- 指定主类,Finish


服务器运行
- 上传服务器


- 运行
bin/yarn jar mymapreduce.jar /test.txt /out3 - 运行结果

