企业开发实践中通常需要提供数据搜索的功能,例如,电商系统中的商品搜索、订单搜索等。通常,搜索任务通常由搜索引擎担当。如Elasticsearch。而我们的原始数据为了安全性等问题通常存储在关系型数据库中。在搜索数据前,我们需要先将数据从关系型数据库中同步至搜索引擎中。因此,整个业务搜索过程包含两个阶段,第一阶段,将数据从关系型数据库同步至搜索引擎;第二阶段,从搜索引擎搜索数据,并返回至用户。下面,我将结合不同业务场景给出相应的数据同步解决方案。
第一,数据量小,业务查询简单。此类场景中,关系数据库中待同步的表数据中无表连接操作或者存在少量的表连接操作。用户在将数据同步到ES前对数据进行连接处理,或者数据同步时不做任何处理,待业务查询时再在ES中进行关联查询。通常我们可以采取Logstash或者Canal读取相应的表数据,然后写入到搜索引擎的索引中。具体架构设计如下图1.1所示。

图1.1 基于Logstash的数据同步方案

图1.2 基于Canal的数据同步方案
第二,数据量大,业务查询复杂。此种场景通常发生在大型综合类电商的商品查询中,由于数据量大,业务查询复杂,用户对查询的响应时延要求高。所以,我们需要考虑数据的分库分表问题,以及提前将数据组织好以便后期查询的问题。这种情况下,我们可以将数据分为主数据和从数据。例如,在商品查询中,it_item_spu为商品表,it_item_cate为商品分类表,it_item_sku为商品SKU表。我们可以认为,it_item_spu为主表,it_item_cate和it_item_sku为从表。我们可以将这三张表构建在一个大的索引中,该索引中包含这三张表中的所有信息。那么,我们如何来构建这个大而全的索引呢?这个时候,我们可以监听主表的变更记录,然后再通过JDBC反查数据连接其他从表来丰富数据。至于如何监听主表变更数据通常由两种处理方式,一种是基于Mysql的binlog日志来监听变更,另一种是基于业务操作发送事件来处理。其架构设计具体如图1.3和图1.4所示。

图1.3 基于Canal同步数据并反查数据库方案
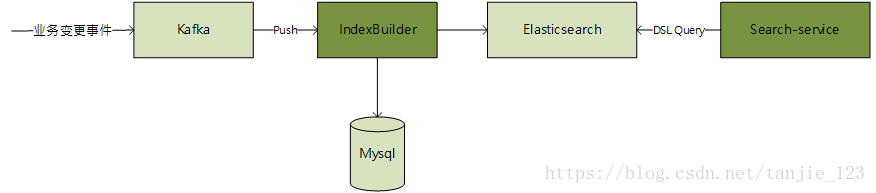
图1.4 基于Kafka消息事件并反查数据库方案
总结,数据同步为数据搜索提供了数据保证,而复杂业务逻辑场景下,如果能够在数据同步阶段微数据搜索重新组织好数据,那么就能够简化业务查询的逻辑,同时提供用户响应时延。