一般的使用缓存模型:
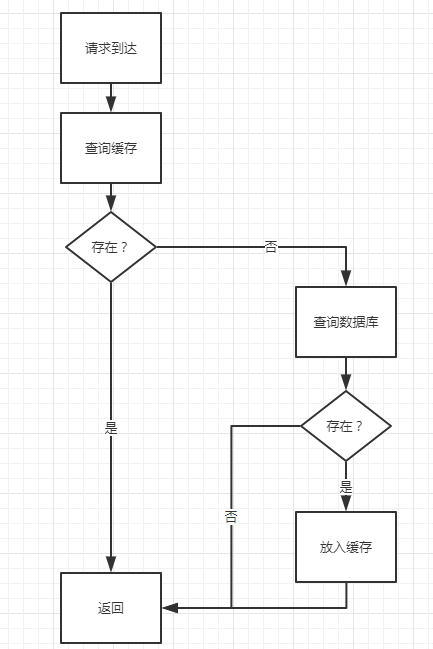
优点:减轻服务器压力
缺点:假设用户故意使用一个不存在的key请求,服务器每次还是会请求数据库
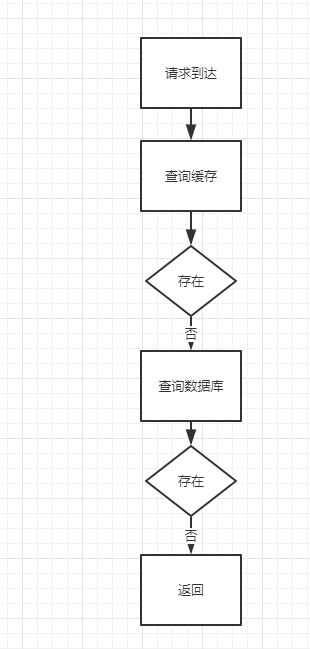
改进方案:
查询数据库,不存在时,向缓存中存放一个特殊字符
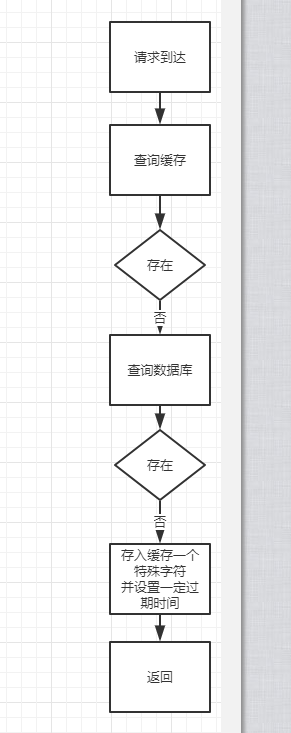
优点:用户使用一个不存在的key重复请求,可以避免给服务器带来的压力
缺点:用户每次使用不同的且不存在的key请求,该模型无法有效拦截
改进:
设置黑名单,如果同一ID,且多次请求不存在的key请求,将该IP记录在黑名单中,服务器处理请求前,先判断该i请求IP是否在黑名单中,在:不做处理,不在:正常处理
问题:当黑名单中集合存有海量的数据时,该集合将占用极大的内存空间,如何快速的判断该用户IP是否存在集合中?
方案:使用布隆过滤器