思考1:Google 搜索引擎每天要从世界各地抓取数以亿计的网页,数据都存储在哪里呢?
GFS:使用大量廉价的去掉硬盘的 PC 机构成集群,将数据都存储在服务器的内存中,采用分布式的文件系统进行存储。
思考2:内存中的数据掉电会丢失,怎么保证可靠呢?
在世界各地进行部署,部分地区还配有发电厂。
当然,不是所有的公司都像 Google 一样技术牛X,有钱,数据都存内存里面。我们的数据主要还是存储在硬盘中的,但是思路还是采用分布式的思想。
什么是分布式文件系统?
思考3:为什么要用分布式文件系统?分布式文件系统解决了什么问题?
分布式文件系统解决了数据的存储问题。
在没有使用分布式的文件系统时,数据存储可能遇到的问题有:
-
硬盘不够大,容纳不了我们要存储的数据。
解决:多几个硬盘。
-
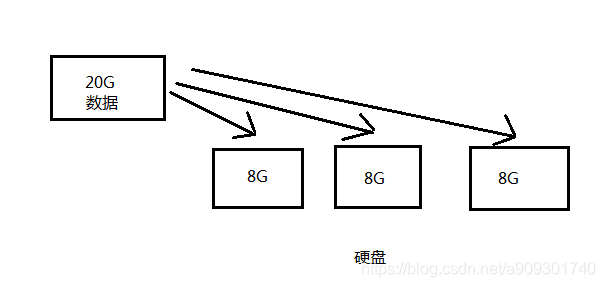
要存储的数据非常大,一下把数据全部存入硬盘,中途断电了,部分数据不就丢失了吗,怎么办?
解决:将数据分块,按数据块的大小进行存储。
ps:Hadoop1.x 的 HDFS 数据块的默认大小是 64 M,Hadoop2.x 的 HDFS 数据块的默认大小是128 M。 -
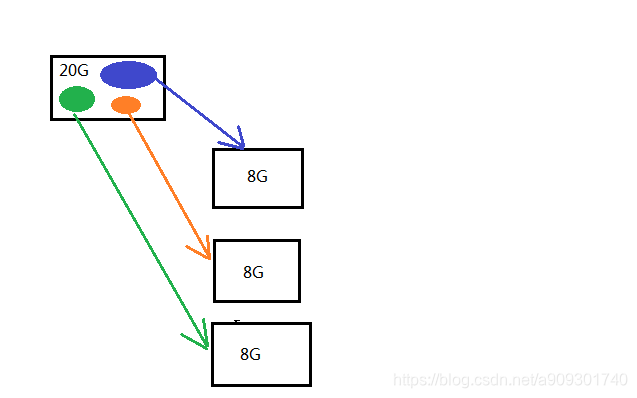
硬盘不够安全,硬盘一旦损坏,上面的数据就丢失了。
解决:数据冗余(同一份数据存多份),客户端上传到服务端一份数据之后,服务端通过水平复制的方式,复制多份相同的数据块到不同的硬盘。
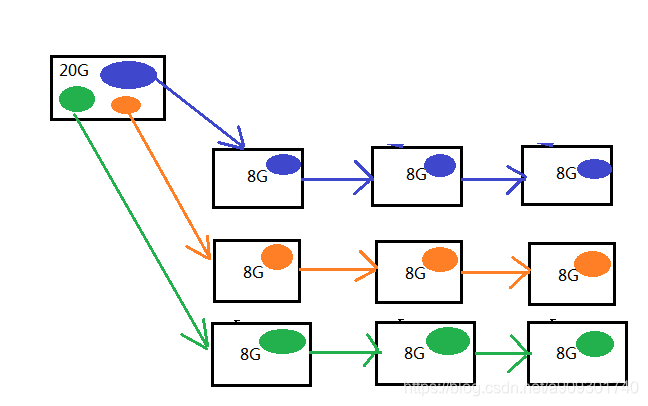
ps:HDFS 数据块默认的冗余度是 3,也就是 1 个数据块在 HDFS 中存 3 份。
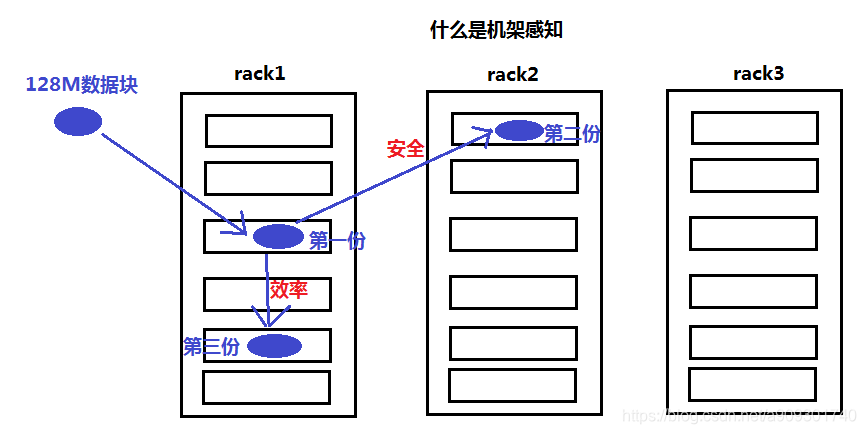
什么是机架感知?
-
冗余的数据块具体要水平复制到哪些硬盘上呢?是通过什么方式来决定数据块的存储位置呢?
解决:机架感知。 -
机架感知如何分配后两份数据块的存储位置?
第 2 份数据优先存储在与第 1 份数据不在同一个机架的另外一个机架的服务器上。(安全)
第 3 份数据优先存储在与第 1 份数据在同一个机架的另外一个服务器上。(效率)
-
为什么第 2 份数据优先存储在与第 1 份数据不在同一个机架的另外一个机架的服务器上?
这是从安全的角度考虑的,万一 rack1 上的所有服务器都挂掉了,还有 rack2 作为后援。 -
为什么第 3 份数据优先存储在与第 1 份数据在同一个机架的另外一个服务器上?
这是从效率的角度考虑的,rack1 上所有服务器都挂掉的该率是比较小的,但是某台服务器挂掉的概率还是有的。存储第一份数据的服务器挂掉后,还可以立即从所处的机架上的另一台服务器上取数据,效率较高。 -
数据块的水平复制,硬盘的添加和移除这些功能由谁来做呢?
需要有一个管理员来管理,不,两个管理员。
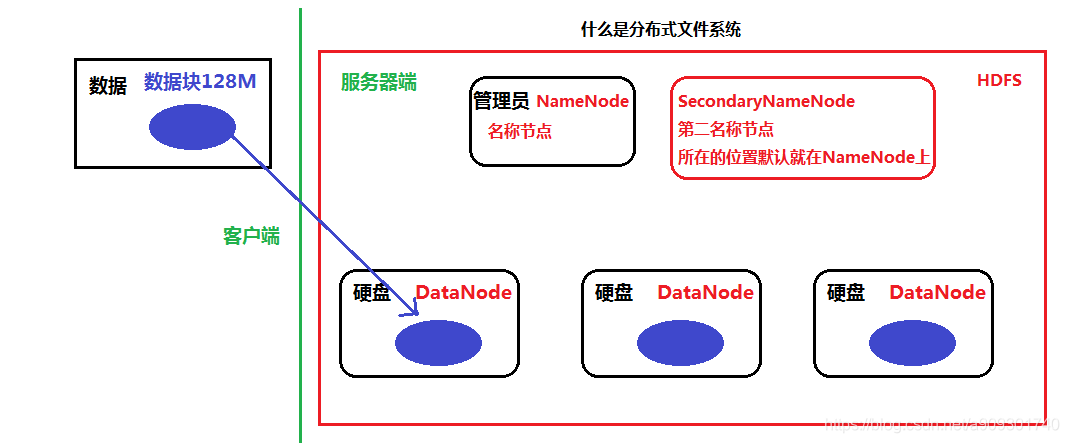
ps:到目前为止,用红框框住的部分就是我们的 HDFS,其实 HDFS 也就是仿照 GFS 的一个通用的(便宜)分布式文件系统。 -
数据块分布在各个服务器上,怎么查找呢?
解决:使用倒排索引,和数据库中的索引类似,存储的是数据块中的位置信息(元信息)。
什么是倒排索引?
思考4:什么是正排索引?正排索引哪里不好?为什么要使用倒排索引?
-
什么是正排索引?
以搜索引擎举例:每个文件都对应了一个文件 ID,文件内容是一系列的关键词的集合,在这个集合中存储了每个关键词出现的次数。
假如使用正排索引,那么在搜索引擎上搜索 “大数据” 时,搜索引擎就需要扫描库中所有的文档,找出所有包含 “大数据” 这个关键词的文件,根据文档 ID 找关键词,这就是正排索引。
很明显,使用正排索引的方式难以满足查找需求,所以就有了倒排索引。
-
什么是倒排索引?
倒排索引就是根据关键词找文件 ID。通过这种方式,就能大大提高搜索引擎检索文档的速度。
以上就是 Google 第一篇论文(GFS)中的一些思想。